在社交媒体上数月的预热和隐藏在代号 "Project Strawberry" 背后,OpenAI 期待已久的新语言模型终于来了 - 它被称为 'o1'。
他们没有将其命名为 GPT-5 或 GPT-4.1 有点不寻常。那么,为什么他们选择了 o1 呢?
根据 OpenAI 的说法,这些新模型的进步是如此显著,以至于他们觉得有必要将计数器重置为 1:
但对于复杂的推理任务来说,这是一个重大的进步,代表了人工智能能力的一个新水平。鉴于此,我们将计数器重置为 1,并将这个系列命名为 OpenAI o1。
这些模型的主要重点是 思考和推理复杂任务并解决更难的问题。因此,不要期望它运行速度很快;相反,它提供比以前模型更好、更合乎逻辑的答案。
o1 系列模型有两个变体:o1-mini 和 o1-preview。
-
o1-preview: 这是最先进、最有能力的官方 o1 模型的预览。o1 在人工智能推理领域取得了显著进展。
-
o1-mini: 这是一个更快、更便宜的推理模型,特别擅长编码。作为一个较小的模型,o1-mini 比 o1-preview 便宜 80%,使其成为需要推理但不需要广泛世界知识的应用的强大、具有成本效益的模型。
OpenAI 强调,这些新模型是通过强化学习进行训练以执行复杂推理。但在 LLMs 的背景下,推理究竟意味着什么呢?
推理是如何工作的?
就像人类在回答困难问题之前思考一会儿一样,o1 在尝试解决问题时使用一种思维链。
它学会了识别和纠正错误。它学会了将棘手的步骤分解为简单的步骤。它学会了在当前方法不起作用时尝试另一种方法。
关键点在于推理使模型在生成最终响应之前考虑多种方法。
以下是这个过程:
-
生成推理 Token
-
生成可见的完成 Token 作为答案
-
从上下文中丢弃推理 Token
丢弃推理 Token 使上下文集中在关键信息上。
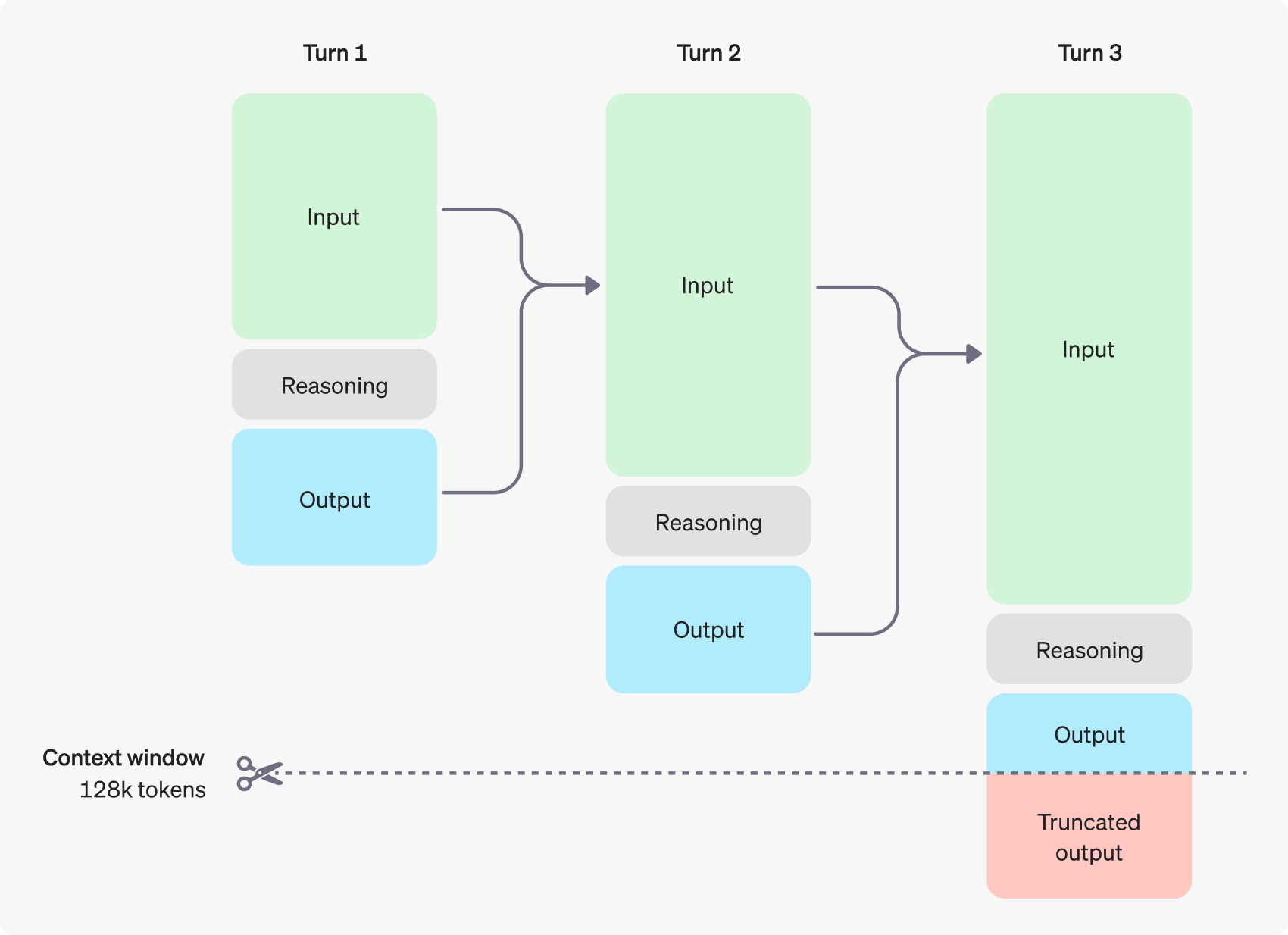
注意: 虽然推理 Token 在 API 中不可见,但它们仍然占据模型上下文窗口中的空间,并作为输出 Token计费。
这种方法可能会慢一些,但根据 NVIDIA 的高级研究员 Jim Fan 的说法,我们终于看到了推理时间扩展的范式被推广并在生产中部署。
Jim 提出了一些很好的观点:
-
你不需要一个庞大的模型来进行推理。 许多参数专门用于记忆事实,以便在诸如问答游戏之类的基准测试中表现良好。可以将推理与知识分离出来,即一个小型的“推理核心”,它知道如何调用浏览器和代码验证器。预训练计算量可以减少。
-
大量的计算被转移到服务推理而不是预/后训练。 LLMs 是基于文本的模拟器。通过在模拟器中推出许多可能的策略和情景,模型最终会收敛到良好的解决方案。这个过程是一个经过深入研究的问题,就像 AlphaGo 的蒙特卡洛树搜索(MCTS)一样。
o1 与 GPT-4o 相比如何?
为了测试 o1 模型在各种人类考试和机器学习基准测试中的表现如何,OpenAI 进行了多样化的测试。
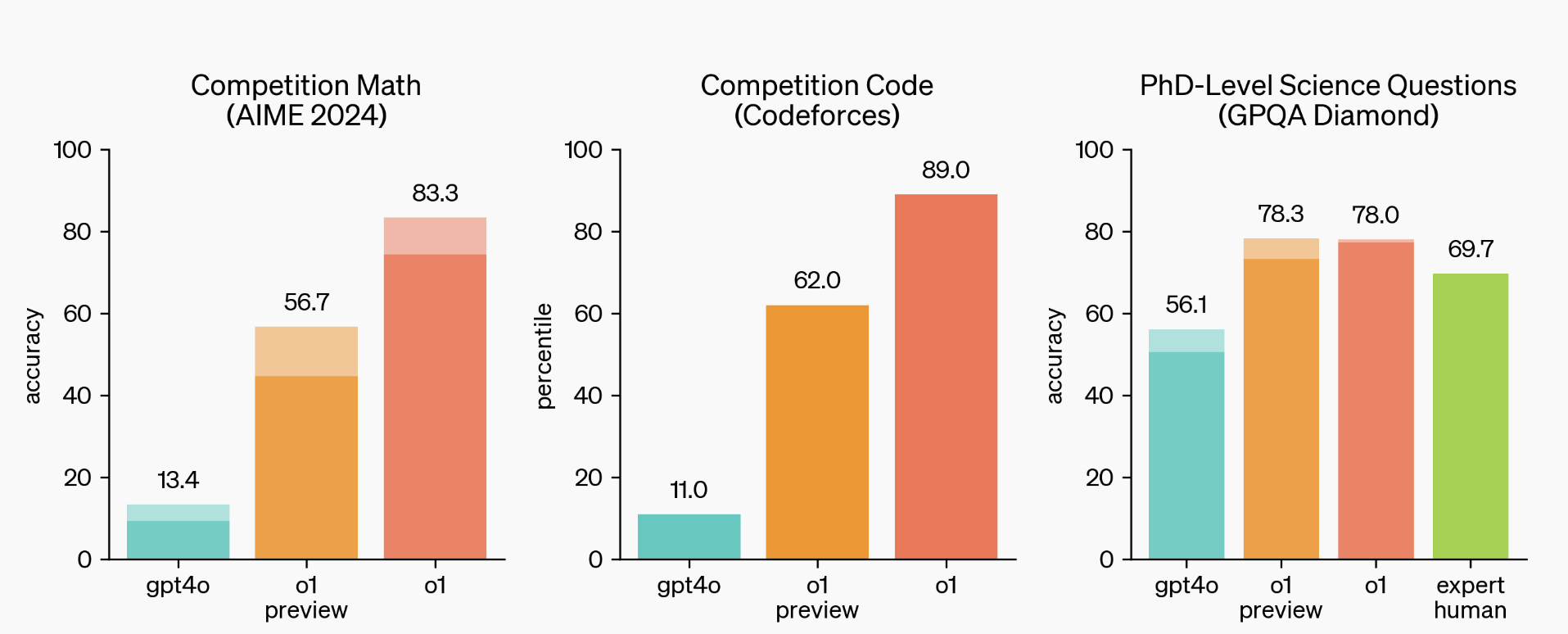
上图显示,o1 在涉及数学、编码和科学问题的具有挑战性的推理基准测试中大大优于 GPT-4o。
在评估 OpenAI 新发布的 o1 模型时,OpenAI 发现它们在 GPQA-diamond 基准测试上表现出色 - 这是一个具有挑战性的智力测试,评估化学、物理和生物方面的专业知识。
为了将模型的表现与持有博士学位的专家相比较,OpenAI 与这些专家合作,让他们回答相同的 GPQA-diamond 问题。
值得注意的是,o1 在这个基准测试上超过了这些人类专家,成为第一个在这个基准测试上做到这一点的模型。虽然这并不意味着 o1 在所有方面都优于博士学位,但它确实表明该模型在解决某些博士学位应该能够解决的问题方面更为娴熟。
您可以在这里阅读有关 o1 模型的技术报告 here。
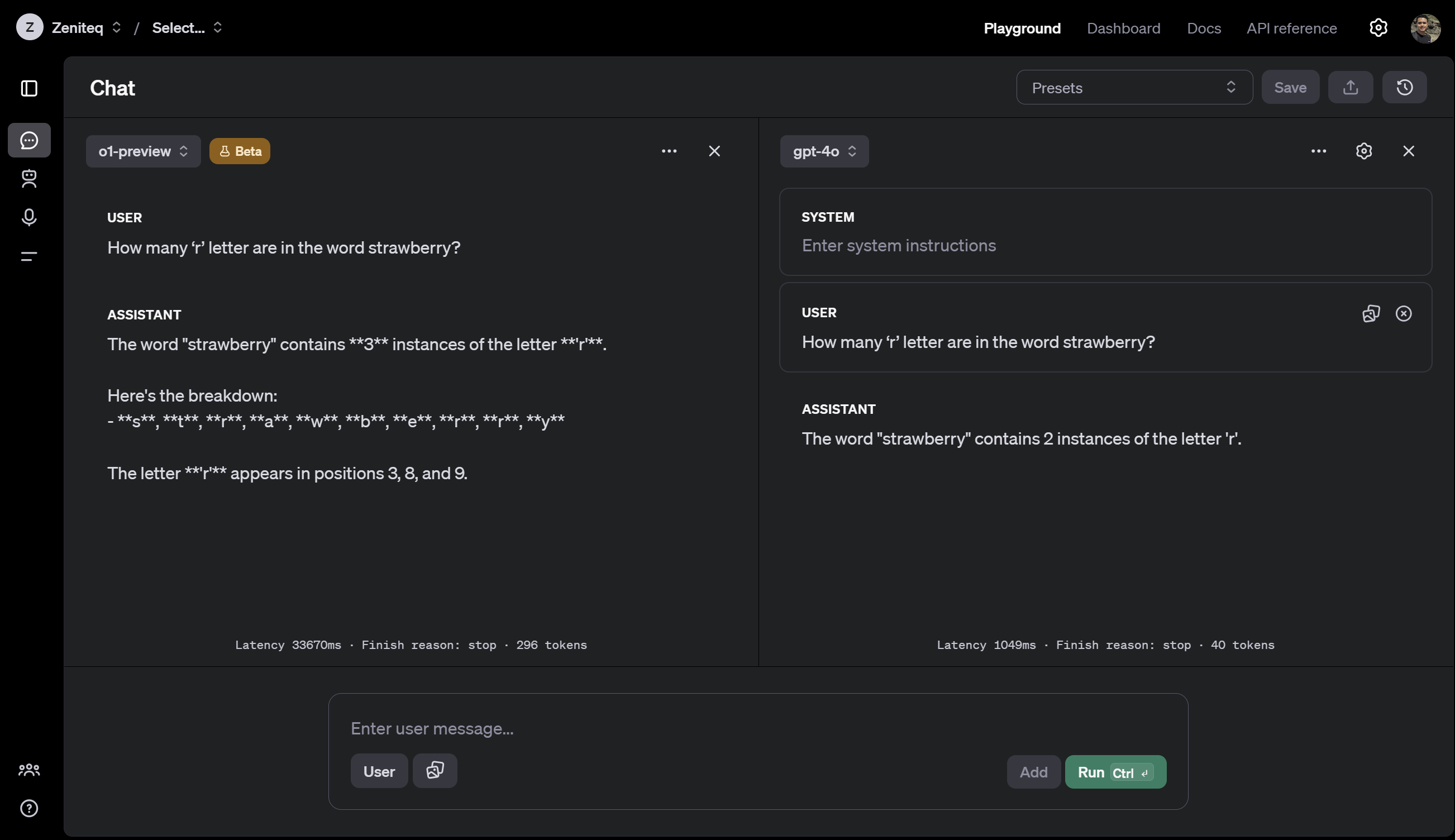
现在,为了看看 o1 在经典问题上的表现如何与之前的模型 GPT-4o 相比,让我们看一个经典问题:计算单词 "strawberry" 中 'r' 的数量。
提示:单词 "strawberry" 中有多少个 'r' 字母?
-
o1 花了 33 秒和 296 个 Token 来解决它,回答正确。
-
GPT-4o 花了不到一秒,消耗了 39 个 Token,但未通过测试。
让我们再试一次。这次,我们要求两个模型列出在其名称的第三个位置有字母 'A' 的国家的列表。
提示:给我 5 个名称中第三个位置有字母 A 的国家
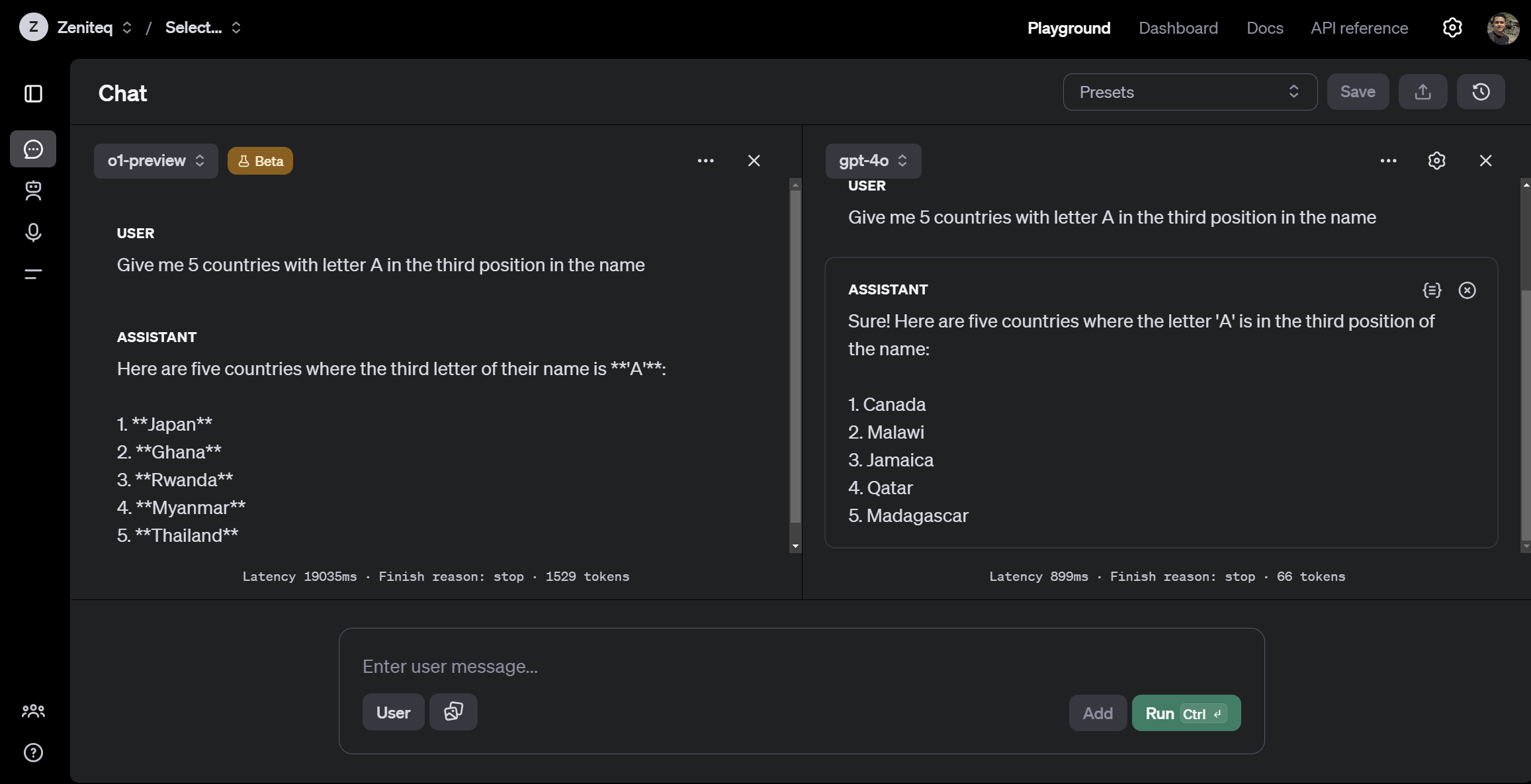
同样,尽管 o1 花费更长的时间“思考”,但回答是正确的。
o1 并非完美
即使 Sam Altman 承认 o1 仍然存在缺陷和局限性。在初次使用时,它可能看起来比在与其花费更多时间后更令人印象深刻。
有时,它仍然会犯错误 - 即使是在询问其响应中有多少个 'r' 的简单问题上。
另一个需要注意的是,o1 模型在推理方面提供了显著的进步,但并不打算在所有用例中取代 GPT-4o。
对于需要图像输入、函数调用或始终快速响应时间的应用程序,GPT-4o 和 GPT-4o mini 模型将继续是正确的选择。
对于开发人员,以下是一些 o1 的聊天完成 API 参数,目前尚不可用:
-
模态: 仅支持文本,不支持图像。
-
消息类型: 仅支持用户和助手消息,不支持系统消息。
-
流式传输: 不支持。
-
工具: 不支持工具、函数调用和响应格式参数。
-
Logprobs: 不支持。
-
其他:
temperature、top_p和n固定为1,而presence_penalty和frequency_penalty固定为0。 -
助手和批处理: 这些模型不支持助手 API 或批处理 API。
如何获得 o1 模型的访问权限?
o1 今天在 ChatGPT 中向所有 Plus 和 Team 用户推出,并在第 5 层的 API 中向开发人员推出。
如果您是免费 ChatGPT 用户,OpenAI 提到他们计划为所有 ChatGPT 免费用户提供 o1-mini 访问权限,但没有提供具体的时间表。
o1 还可以在 OpenAI Playground 中使用。只需登录到 https://platform.openai.com/,在 Playground 选项卡下,将模型设置为 "o1-mini" 或 "o1-preview"。
还有 API 模型 "o1-mini-2024–09–12" 和 "o1-preview-2024–09–12",这些模型已经可以供开发人员使用。
o1 模型的提示技巧
如果您习惯于使用 Claude 3.5 Sonnet、Gemini Pro 或 GPT-4o 等模型进行提示,那么提示 o1 模型是不同的。
o1 模型在简单直接的提示下表现最佳。一些提示工程技术,如少量提示或指导模型“逐步思考”,可能不会提高性能,有时甚至会妨碍性能。
查看一些最佳实践:
-
保持提示简单直接: 模型擅长理解并回应简明清晰的指令,无需详尽的指导。
-
避免链式思维提示: 由于这些模型在内部进行推理,提示它们“逐步思考”或“解释您的推理”是不必要的。
-
使用分隔符以提高清晰度: 使用分隔符,如三重引号、XML 标记或章节标题,以清楚地指示输入的不同部分,帮助模型适当地解释不同部分。
-
在检索增强生成(RAG)中限制额外上下文: 当提供额外上下文或文档时,只包含最相关的信息,以防止模型过于复杂化其响应。
最后的思考
好吧,当涉及基于聊天的问题解决和内容生成时,o1 是令人印象深刻的。但你知道我最兴奋的是什么吗?它融入到编码助手中,比如 Cursor AI。
我已经看到一些人将他们的 API 密钥插入到 Cursor 中,并使用 o1 为他们编写代码。我还没有尝试过,但我非常期待尝试一下。
从我的初步测试来看,o1 的思考、规划和执行能力是非常出色的。我们基本上正在见证一种具有代理性编码系统的 ChatGPT 时刻。其新能力的影响是巨大的。我真诚地相信,将会有一波全新的产品应运而生,这些产品将不同于我们以往所见。在软件开发领域的新可能性令人振奋,我迫不及待地想看到 o1 将如何在未来几周内彻底改变我们编码和构建应用程序的方式。