黑森林实验室推出了 FLUX.1,这是一套开源的 AI 图像生成模型套件,您可以在本地运行。
FLUX 模型席卷了社交媒体,因为其中最大的一个 FLUX.1,在性能上超越了 Stable Diffusion 3 Ultra、Midjourney v6.0 和 DALL·E 3 HD。
看看这些基准测试结果,简直疯狂!
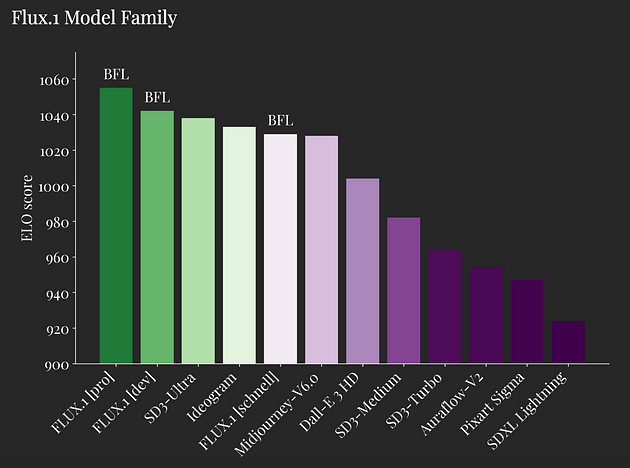
这里有 3 个模型:
-
Flux.1 [pro]: 专有的、基于 API 的,每张图片 0.055 美元。
-
Flux.1 [dev]: 120 亿参数,非商业用途。
-
Flux.1 [schnell]: 120 亿参数,速度优化,Apache 2.0 许可。
而且它们都基于混合多模态 Transformer 块:
-
并行扩散和并行注意力层
-
扩展到 120 亿参数
-
流匹配(在可能性和样本质量方面始终表现比基于扩散的替代方法更好)
当您阅读本文时,已经发布了许多 LoRA 和扩展版本,人们说它明显比 Midjourney 更好,而我的经验也非常…… 非常有希望!
FLUX 模型使得接触尖端生成式 AI 研究变得更加民主化,并推动了文本到图像合成的极限。
有趣的是,黑森林首席执行官 Robin Rombach 也是 VQGAN、潜在扩散、对抗性扩散蒸馏、Stable Diffusion XL 和 Stable Video Diffusion 的关键论文合著者。
我们将看到一波 Flux 的开放版本,这就是为什么我想带您通过 LoRA 在本地进行 Flux 微调。
让我们开始吧!

为 Flux LoRA 微调设置环境
首先,这是您应该已经准备好的内容:
-
Python >3.10
-
Nvidia GPU,至少有 24GB 的 VRAM 用于训练 FLUX.1(我正在使用 4090)
-
Python 虚拟环境
-
Git
一切就绪后,打开您的命令行界面 - 这可以是命令提示符、终端或您习惯使用的任何其他 CLI 工具 - 并运行以下命令:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python3 -m venv flux-finetune-env
source flux-finetune-env/bin/activate
pip3 install torch
pip3 install -r requirements.txt
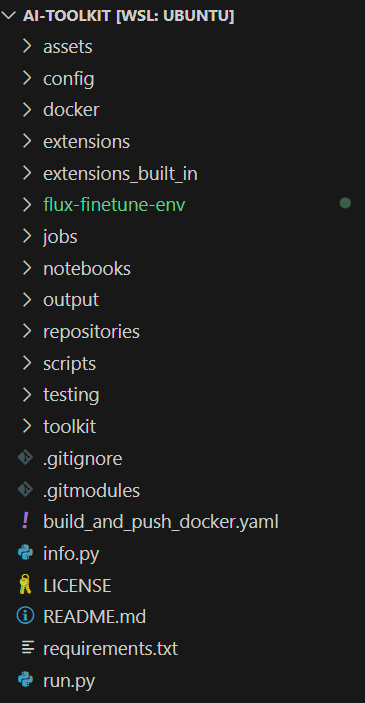
现在您应该看到完整的项目如下:
现在,我们将设置 Hugging Face:
-
登录 HF 并接受 black-forest-labs/FLUX.1-dev 模型访问权限。目前,我们只能使用 FLUX.1-dev,它继承了非商业许可证。
-
在此文件夹的根目录下创建一个名为
.env的文件。
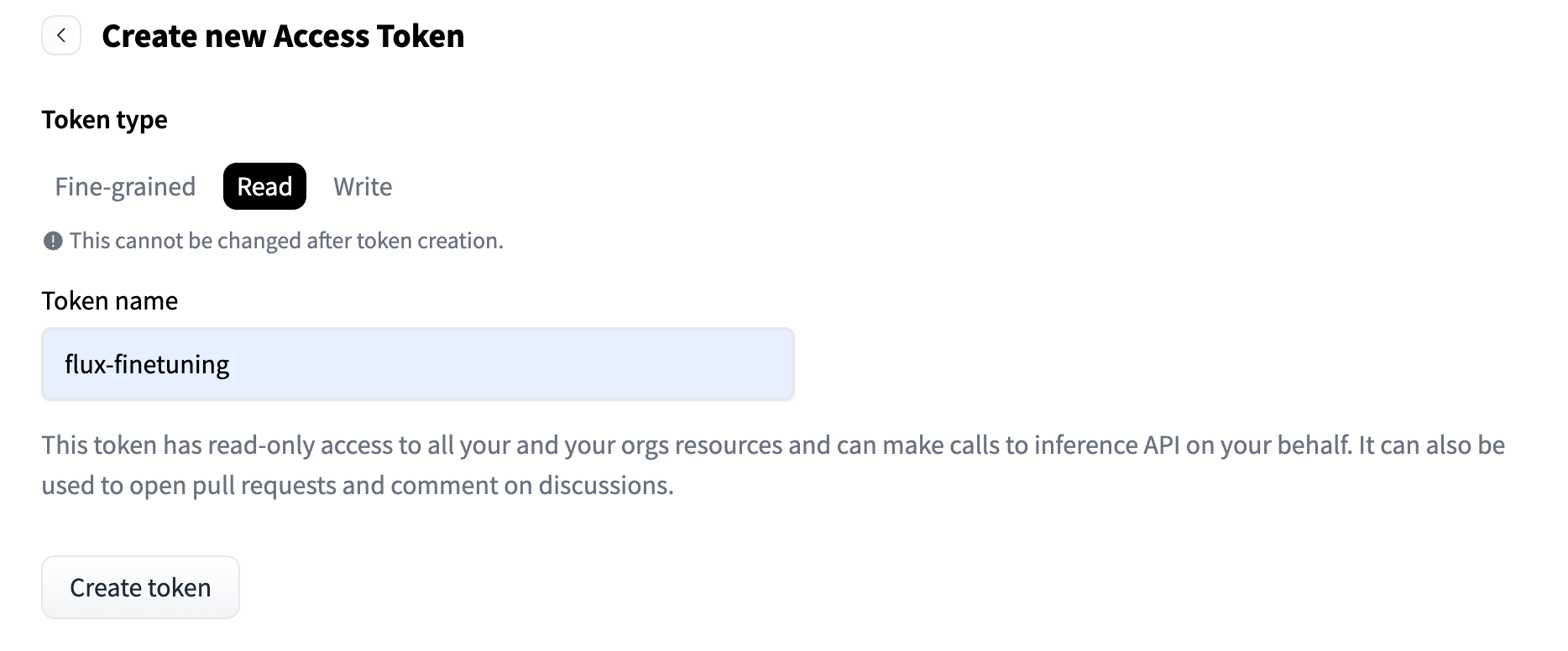
并将其添加到 .env 文件中:
HF_TOKEN=hf_jpTKpr....
我们已经准备就绪!
准备用于微调 FLUX 模型的数据集
这是我们将根据存储库中共享的指导准备数据集的方法:
-
文件夹结构:数据集将组织在一个包含图像及其对应文本文件的文件夹中。
-
文件命名:文本文件将与其对应的图像具有相同的名称,但扩展名为
.txt(例如,image22.jpg和image22.txt)。 -
支持的图像格式:仅支持 JPG、JPEG 和 PNG 格式。由于已知问题,请勿使用 WebP。
-
文本文件内容:每个文本文件应仅包含相应图像的标题。如果在配置中使用
trigger_word,则标题中可以包含单词[trigger],它将被自动替换。 -
图像处理:图像永远不会被放大,但将根据需要缩小,并放置在适当的批次桶中。
-
图像裁剪/调整大小:不需要手动裁剪或调整图像大小。加载器将自动调整图像大小,并可以处理不同的纵横比。
最终,您的 data 文件夹应如下所示:
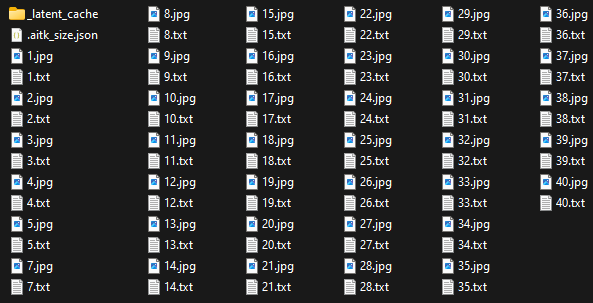
对于每个图像,应该有一个 .jpg 文件和一个包含标题的 .txt 文件。

我在互联网上浏览了图片(40 张),并要求 ChatGPT 创建标题并生成 .txt 文件以供下载。
您可以在这里找到完整的数据集。
正如您所见,我正在追求复古的外观和风格。
配置 FLUX 微调流程
首先,让我们将位于 config/examples/train_lora_flux_24gb.yaml 的示例配置文件复制到 config 文件夹,并将其重命名为 flux_vintage_aesthetics.yaml,
并进行以下编辑:
---
job: extension
config:
# this name will be the folder and filename name
name: "flux_vintage_aesthetics"
process:
- type: 'sd_trainer'
# root folder to save training sessions/samples/weights
training_folder: "output/vintageae"
# uncomment to see performance stats in the terminal every N steps
performance_log_every: 1000
device: cuda:0
# if a trigger word is specified, it will be added to captions of training data if it does not already exist
# alternatively, in your captions you can add [trigger] and it will be replaced with the trigger word
trigger_word: "v1nt4g3"
network:
type: "lora"
linear: 32
linear_alpha: 32
save:
dtype: float16 # precision to save
save_every: 250 # save every this many steps
max_step_saves_to_keep: 4 # how many intermittent saves to keep
datasets:
# datasets are a folder of images. captions need to be txt files with the same name as the image
# for instance image2.jpg and image2.txt. Only jpg, jpeg, and png are supported currently
# images will automatically be resized and bucketed into the resolution specified
# on windows, escape back slashes with another backslash so
# "C:\\path\\to\\images\\folder"
- folder_path: "data"
caption_ext: "txt"
caption_dropout_rate: 0.05 # will drop out the caption 5% of time
shuffle_tokens: false # shuffle caption order, split by commas
cache_latents_to_disk: true # leave this true unless you know what you're doing
resolution: [ 512, 768, 1024 ] # flux enjoys multiple resolutions
train:
batch_size: 1
steps: 4000 # total number of steps to train 500 - 4000 is a good range
gradient_accumulation_steps: 1
train_unet: true
train_text_encoder: false # probably won't work with flux
gradient_checkpointing: true # need the on unless you have a ton of vram
noise_scheduler: "flowmatch" # for training only
optimizer: "adamw8bit"
lr: 1e-4
# uncomment this to skip the pre training sample
skip_first_sample: true
# uncomment to completely disable sampling
# disable_sampling: true
# uncomment to use new vell curved weighting. Experimental but may produce better results
linear_timesteps: true
# ema will smooth out learning, but could slow it down. Recommended to leave on.
ema_config:
use_ema: true
ema_decay: 0.99# 如果 GPU 支持的话,Flux 可能会需要这个,其他数据类型可能无法正常工作
数据类型: bf16
模型:
# huggingface 模型名称或路径
名称或路径: "black-forest-labs/FLUX.1-dev"
is_flux: true
量化: true # 运行 8 位混合精度
# 低 VRAM: true # 如果 GPU 连接到您的显示器,请取消注释。它将使用更少的 VRAM 进行量化,但速度较慢。
样本:
采样器: "flowmatch" # 必须与 train.noise_scheduler 匹配
每隔多少步采样: 250 # 每隔这么多步采样一次
宽度: 1024
高度: 1024
提示:
# 您可以在这里的提示中添加 [trigger],它将被触发词替换
- "[trigger] 拿着写着'I LOVE VINTAGE!'的牌子"
- "[trigger] 红发,在公园里下棋,旁边是一辆老式白色汽车,街道两旁有树"
- "[trigger] 拿着咖啡杯,在咖啡馆里坐着,戴着针织帽"
- "[trigger] 穿着浅米色西装和大号帽子,在夜总会当 DJ,鱼眼镜头,烟雾机,激光灯,拿着马丁尼展现优雅"
- "[trigger] 在海滩上炫耀他的新 T 恤,背景中有一只鲨鱼跃出水面"
- "一对情侣手牵手穿过雪覆盖的山脉中迷人的乡村风景"
- "[trigger] 穿着短袖白衬衫塞进高腰黑裤,站在舞台上弹吉他,唱歌"
- "留胡子的嬉皮士男子,穿着时尚复古的服装,在木工作坊里搭建椅子"
- "一对时尚的情侣手牵手走出豪华建筑。女士穿着黑色连衣裙和宽边帽,而男士穿着定制的棕色西装外套和深色裤子。"
- "一名女子在河边享受阳光明媚的一天,脸朝着太阳倚靠着。她穿着宽松的蓝色衬衫和白色短裤,身边放着编织袋,捕捉到一个无忧无虑的时刻。"
- "[trigger] 自信地站在船上,抓住横梁,风吹拂着头发。他穿着蓝白条纹衬衫搭配白色裤子,展现出一种航海风格。"
负例: "" # 在 Flux 上未使用
种子: 42
漫步种子: true
引导比例: 4
采样步数: 20
# 您可以在此处添加任何其他元信息。[name] 将替换为顶部的配置名称
meta:
名称: "[vintageae]"
版本: '1.0'> **Llama 3 Powered Voice Assistant: Integrating Local RAG with Qdrant, Whisper, and LangChain**
在这篇文章中,我们介绍了 Llama 3 动力语音助手,它将本地 RAG 与 Qdrant、Whisper 和 LangChain 进行了整合。