
我清楚地记得,直到几个月前,Prompt Engineering(提示工程)仍然备受瞩目。整个就业市场都充斥着提示工程师的角色,但现在不再如此。Prompt Engineering 并不是任何艺术或科学,它只是一种聪明的汉斯现象,人类为系统提供必要的上下文以更好地回答问题。人们甚至写了书籍/博客,比如《前 50 个提示,以获得 GPT 的最佳效果》,等等。但大规模实验清楚地表明,并不存在适用于所有问题的单一提示或策略,有些提示看似在孤立环境中效果更好,但在全面分析时却是一种碰运气。因此,今天我们要谈论的是 DSPY:将声明性语言模型调用编译成自我改进的管道,这是斯坦福开发的一个框架,用于自我改进的管道,其中 LLM 被视为一个模块,由编译器进行优化,类似于 PyTorch 中找到的抽象。
引言
正如我上面提到的,互联网上充斥着推广书籍和博客。其中大部分只是在向你兜售一堆垃圾。现在,正如我所说,其中有一些可能确实有效,但这并不是构建我们应用程序的好方法。了解某些事情不起作用的时候很重要,我们需要定义一个安全的假设空间,即系统工作和不工作的情况。
甚至有论文表明,使用某些情感提示可以提高 LLM 的性能。对于我来说,我对这样的论文的真实性仍然持保留态度。这种效果能持续多久?对每个主题都适用吗?是否有一些主题,在这种情感提示下可能导致更糟糕的结果?有很多这样的论文,无意中发布了半成品的研究。另一篇类似的论文是《自回归的余烬》,后来证明很多东西是错误的。

但更大的问题是,这是一种什么样的科学/系统化方式,我必须告诉一个系统:“如果你不立即给出答案,我可能会被解雇,或者我的祖母病了,等等”。这只是人们随机尝试入侵 LLM 行为。
理解提示问题
例如,当我说“使用硬负例示例添加 5-shot CoT 与 RAG”时,从概念上讲很清楚,但在实践中实施起来确实很困难。LLM 对提示非常敏感,因此在提示中放置这种结构大多数时候不起作用。LLM 对提示的书写方式非常敏感,这使得很难引导它们。
因此,当我们构建一个管道时,不仅仅是我试图说服一个 LLM 以某种方式输出,而更重要的是输出应该受到限制,以便作为更大管道中其他模块的输入。
为了解决这个问题,已经有很多研究正在进行,但在许多方面受到了很大限制。大多数都依赖于字符串模板,这些模板脆弱且不可扩展。语言模型随时间变化,提示就会失效。如果我们想将我们的模块插入到不同的管道中,它就无法工作。我们希望它能与新工具、新数据库或检索器进行交互,但它无法工作。
这正是 DSPy 旨在解决的问题,将 LLM 视为一个模块,根据它与管道中其他组件的交互方式自动调整其行为。
DSPy 范式:让我们编程 - 而不是提示 - 语言模型
因此,DSPy 的目标是将重点从调整 LLM 转移到良好的整体系统设计。
但如何做到?
为了在心智层面上思考这个问题,我们可以将 LLM 视为:设备:执行指令并通过类似 DNN 的抽象操作的设备。
例如,我们在 PyTorch 中定义了一个卷积层,它可以对来自其他层的一组输入进行操作。从概念上讲,我们可以堆叠这些层,并在我们的原始输入上实现所需的抽象级别,我们不需要定义任何 CUDA 核心和许多其他指令。所有这些都已经在卷积层的定义中抽象出来。这就是我们希望在 LLM 中做的事情,其中 LLM 是抽象模块,堆叠在不同的组合中以实现某种类型的行为,无论是 CoT、ReAct 还是其他什么。
为了获得所需的行为,我们需要改变一些东西:

NLP 签名
这些只是我们希望从我们的 LLM 中获得的行为声明。这仅定义了需要实现的内容,而不是如何提示 LLM 做到这一点的规范。

-
签名处理结构化格式和解析逻辑。
-
签名可以编译成自我改进和管道自适应提示或微调。
DSPY 使用以下方式推断字段的作用:
-
它们的名称,例如,DSPy 将使用上下文学习来解释问题与答案的不同之处。
-
它们的痕迹(输入/输出示例)
**注意:**所有这些都不是硬编码的,而是系统在编译过程中自行解决。
模块
这是我们使用签名构建模块的地方,比如,如果我们想构建一个 CoT 模块,我们就使用这些签名来构建它。这将自动生成高质量的提示,以实现某些提示技术的行为。
更具体的定义: 模块是一个参数化层,通过抽象提示技术来表达签名。

声明后,模块就像可调用函数一样运行。
参数: 为了表达特定的签名,任何 LLM 调用都需要指定:
-
要调用的具体 LLM
-
提示指令
-
每个签名字段的字符串前缀
-
用作少量提示和/或微调数据的演示
优化器
为了使这个系统工作,优化器基本上接管整个管道,并根据某个度量标准对其进行优化,在这个过程中自动生成最佳提示,甚至更新语言模型的权重。
在高层次上的想法是,我们将使用优化器来编译我们的代码,使语言模型调用的每个模块都被优化为自动生成的提示,或者适合我们要解决的任务的新微调权重集。
实际示例
对于复杂的问答任务,单个搜索查询通常是不够的。例如,在 HotPotQA 中的一个示例包括关于“Right Back At It Again”作者的出生城市的问题。搜索查询通常可以正确识别作者为“Jeremy McKinnon”,但缺乏在确定他的出生日期时组成预期答案的能力。
在检索增强的 NLP 文献中,解决这一挑战的标准方法是构建多跳搜索系统,如 GoldEn(Qi 等,2019)和 Baleen(Khattab 等,2021)。这些系统阅读检索结果,然后在必要时生成额外的查询以收集额外信息,然后得出最终答案。使用 DSPy,我们可以轻松地在几行代码中模拟这样的系统。
目前,要实现这一点,我们需要编写非常复杂的提示,并以非常混乱的方式结构化它们。但糟糕的部分是,一旦我改变问题的类型,我可能需要完全改变系统设计,但使用 DSPy 就不会这样。
配置语言模型和检索模型
import dspy
turbo = dspy.OpenAI(model='gpt-3.5-turbo')
colbertv2_wiki17_abstracts = dspy.ColBERTv2(url='http://20.102.90.50:2017/wiki17_abstracts')
dspy.settings.configure(lm=turbo, rm=colbertv2_wiki17_abstracts)
如果您想了解更多关于检索模型的信息:
加载数据集
我们使用提到的 HotPotQA 数据集,这是一个典型的复杂问答对集合,通常以多跳方式回答。我们可以通过 HotPotQA 类通过 DSPy 加载此数据集:
from dspy.datasets import HotPotQA
# 加载数据集。
dataset = HotPotQA(train_seed=1, train_size=20, eval_seed=2023, dev_size=50, test_size=0)
# 告诉 DSPy 'question' 字段是输入。任何其他字段都是标签和/或元数据。
trainset = [x.with_inputs('question') for x in dataset.train]
devset = [x.with_inputs('question') for x in dataset.dev]
len(trainset), len(devset)
#输出
(20, 50)
构建签名
现在我们已经加载了数据,让我们开始为 Baleen 管道的子任务定义签名。
我们将首先创建 GenerateAnswer 签名,它将以 context 和 question 作为输入,并给出 answer 作为输出。
class GenerateAnswer(dspy.Signature):
"""用简短的事实性答案回答问题。"""
context = dspy.InputField(desc="可能包含相关事实")
question = dspy.InputField()
answer = dspy.OutputField(desc="通常在 1 到 5 个单词之间")```python
class GenerateSearchQuery(dspy.Signature):
"""编写一个简单的搜索查询,以帮助回答复杂问题。"""
context = dspy.InputField(desc="可能包含相关事实")
question = dspy.InputField()
query = dspy.OutputField()
构建流水线
因此,让我们定义程序本身 SimplifiedBaleen。实现这一目标的方法有很多种,但我们将把这个版本简化为关键要素。
from dsp.utils import deduplicate
class SimplifiedBaleen(dspy.Module):
def __init__(self, passages_per_hop=3, max_hops=2):
super().__init__()
self.generate_query = [dspy.ChainOfThought(GenerateSearchQuery) for _ in range(max_hops)]
self.retrieve = dspy.Retrieve(k=passages_per_hop)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
self.max_hops = max_hops
def forward(self, question):
context = []
for hop in range(self.max_hops):
query = self.generate_query[hop](context=context, question=question).query
passages = self.retrieve(query).passages
context = deduplicate(context + passages)
pred = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=pred.answer)
正如我们所看到的,__init__ 方法定义了一些关键的子模块:
-
generate_query: 对于每个跳数,我们将使用一个带有
GenerateSearchQuery签名的dspy.ChainOfThought预测器。 -
retrieve: 该模块将使用生成的查询在我们定义的 ColBERT RM 搜索索引上进行搜索,通过
dspy.Retrieve模块。 -
generate_answer: 这个
dspy.Predict模块将与GenerateAnswer签名一起使用,以生成最终答案。
forward 方法在简单的控制流中使用这些子模块。
-
首先,我们将循环执行
self.max_hops次。 -
在每次迭代中,我们将使用
self.generate_query[hop]中的预测器生成一个搜索查询。 -
我们将使用该查询检索前 k 个段落。
-
我们将将(去重后的)段落添加到我们的
context累加器中。 -
循环结束后,我们将使用
self.generate_answer生成一个答案。 -
我们将返回一个包含检索到的
context和预测的answer的预测结果。
执行流水线
让我们在其零-shot(未编译)设置中执行此程序。
这并不一定意味着性能会很差,而是我们直接受到底层 LM 理解我们的子任务的可靠性的限制。当使用最昂贵/强大的模型(例如 GPT-4)处理最简单和最标准的任务(例如回答有关流行实体的简单问题)时,通常情况下这是完全可以接受的。
# 向这个简单的 RAG 程序提出任何你喜欢的问题。
my_question = "David Gregory 继承的城堡有多少层?"
# 获取预测。这包含 `pred.context` 和 `pred.answer`。
uncompiled_baleen = SimplifiedBaleen() # 未编译(即零-shot)程序
pred = uncompiled_baleen(my_question)
# 打印上下文和答案。
print(f"问题: {my_question}")
print(f"预测的答案: {pred.answer}")
print(f"检索到的上下文(截断): {[c[:200] + '...' for c in pred.context]}")
#Output
问题: David Gregory 继承的城堡有多少层?
预测的答案: 五
检索到的上下文(截断): ['David Gregory (physician) | David Gregory (20 December 1625 – 1720) was a Scottish physician and inventor. His surname is sometimes spelt as Gregorie, the original Scottish spelling. He inherited Kinn...', 'The Boleyn Inheritance | The Boleyn Inheritance is a novel by British author Philippa Gregory which was first published in 2006. It is a direct sequel to her previous novel "The Other Boleyn Girl," an...', 'Gregory of Gaeta | Gregory was the Duke of Gaeta from 963 until his death. He was the second son of Docibilis II of Gaeta and his wife Orania. He succeeded his brother John II, who had left only daugh...', 'Kinnairdy Castle | Kinnairdy Castle is a tower house, having five storeys and a garret, two miles south of Aberchirder, Aberdeenshire, Scotland. The alternative name is Old Kinnairdy....', 'Kinnaird Head | Kinnaird Head (Scottish Gaelic: "An Ceann Àrd" , "high headland") is a headland projecting into the North Sea, within the town of Fraserburgh, Aberdeenshire on the east coast of Scotla...', 'Kinnaird Castle, Brechin | Kinnaird Castle is a 15th-century castle in Angus, Scotland. The castle has been home to the Carnegie family, the Earl of Southesk, for more than 600 years....']
优化流水线
然而,对于更专业的任务、新领域/设置以及更高效(或开放)的模型,零-shot 方法很快就会显得力不从心。
为了解决这个问题,DSPy 提供了编译功能。让我们编译我们的多跳(SimplifiedBaleen)程序。
让我们首先为编译定义验证逻辑:
-
预测的答案与标准答案匹配。
-
检索到的上下文包含标准答案。
-
生成的查询中没有冗长的内容(即没有超过 100 个字符的查询)。
-
生成的查询中没有大致重复的内容(即没有与之前查询的 F1 分数达到 0.8 或更高的查询)。
def validate_context_and_answer_and_hops(example, pred, trace=None):
if not dspy.evaluate.answer_exact_match(example, pred): return False
if not dspy.evaluate.answer_passage_match(example, pred): return False
hops = [example.question] + [outputs.query for *_, outputs in trace if 'query' in outputs]
if max([len(h) for h in hops]) > 100: return False
if any(dspy.evaluate.answer_exact_match_str(hops[idx], hops[:idx], frac=0.8) for idx in range(2, len(hops))): return False
return True
我们将使用 DSPy 中最基本的提词器之一,即 BootstrapFewShot,通过少量示例来优化流水线中的预测器。
from dspy.teleprompt import BootstrapFewShot
teleprompter = BootstrapFewShot(metric=validate_context_and_answer_and_hops)
compiled_baleen = teleprompter.compile(SimplifiedBaleen(), teacher=SimplifiedBaleen(passages_per_hop=2), trainset=trainset)
评估流水线
现在让我们定义评估函数,并比较未编译和编译的 Baleen 流水线的性能。虽然这个 devset 并不是一个完全可靠的基准,但在本教程中使用它是有益的。
from dspy.evaluate.evaluate import Evaluate
# 定义检查我们是否检索到正确文档的指标
def gold_passages_retrieved(example, pred, trace=None):
gold_titles = set(map(dspy.evaluate.normalize_text, example["gold_titles"]))
found_titles = set(
map(dspy.evaluate.normalize_text, [c.split(" | ")[0] for c in pred.context])
)
return gold_titles.issubset(found_titles)
# 设置 `evaluate_on_hotpotqa` 函数。我们将在下面多次使用它。
evaluate_on_hotpotqa = Evaluate(devset=devset, num_threads=1, display_progress=True, display_table=5)
uncompiled_baleen_retrieval_score = evaluate_on_hotpotqa(uncompiled_baleen, metric=gold_passages_retrieved, display=False)
compiled_baleen_retrieval_score = evaluate_on_hotpotqa(compiled_baleen, metric=gold_passages_retrieved)
print(f"## 未编译 Baleen 的检索分数: {uncompiled_baleen_retrieval_score}")
print(f"## 编译 Baleen 的检索分数: {compiled_baleen_retrieval_score}")
#Output
## 未编译 Baleen 的检索分数: 36.0
## 编译 Baleen 的检索分数: 60.0
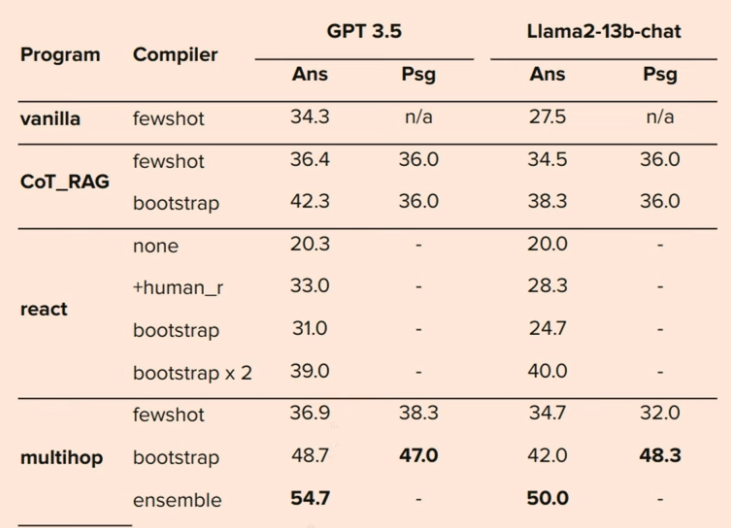
结论
这些结果表明,在 DSPy 中结合多跳设置甚至可以超越人类反馈。它们甚至表明,当在 DSPy 设置中使用时,即使是像 T5 这样的规模小得多的模型也可以与 GPT 相提并论。DSPy 是我在 lang chain 发布后遇到的最酷的东西之一,这显示了在制作一个比在大型 LLM 管道中随意放置部件更好且系统化设计的系统方面的巨大潜力。