Claude 3.5 - 文档智能之王

Claude 3 的发布基本解决了文档提取的问题,但自那以后,模型的成熟使我们最终能够拥有一个“近乎完美”的开箱即用文档智能处理流水线,而无需依赖昂贵或供应商锁定的产品。
在本文中,我们将使用 新发布的模型 构建,并探索一种可用于生产的 IDP 解决方案,与市场上的 SOTA 解决方案相匹配。
IDP - 智能文档处理
在讨论 Claude 应用的具体细节之前,让我们先描述一下智能文档处理(IDP)。IDP 是一种结合人工智能技术来自动化文档处理的方法,将非结构化数据转换为结构化、可操作的见解。
IDP 工作流程
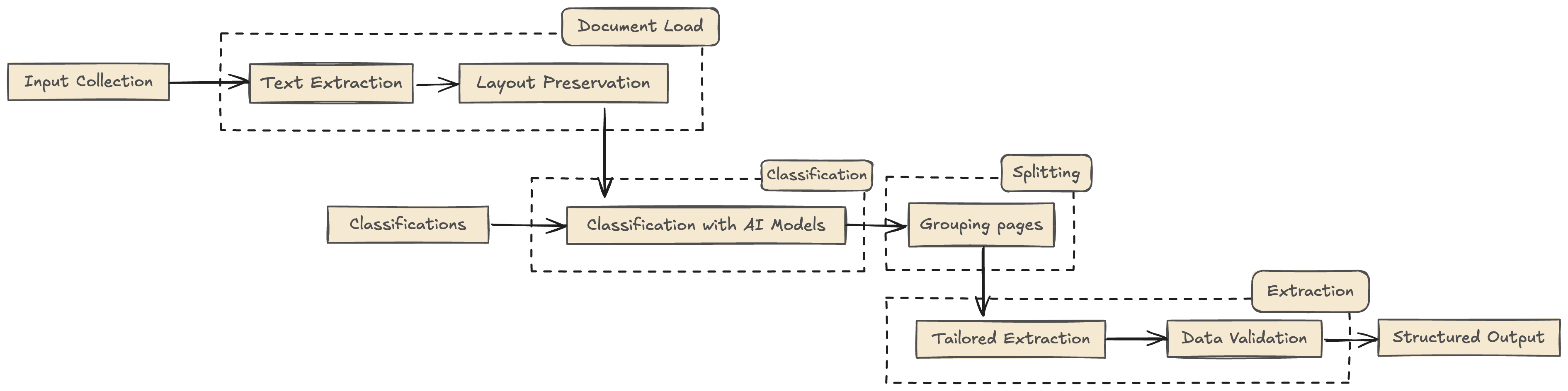
当您收到一批文档 - 扫描图像、PDF 文件或两者混合 - 目标是高效处理并提取有价值的信息。以下是工作流程通常的展开方式:
1. 文档加载:
首先收集需要处理的所有文档。这些文档可能是不同格式的,可能包括多个文档组合成一个文件。使用光学字符识别(OCR)提取文本,将图像和扫描文档转换为可机器读取的文本。确保保留布局以保持结构和格式,这对于理解表格、表单和其他格式化内容很重要。
2. 分类和文档拆分:
加载文档并将组合文件分隔为单独的页面或部分。使用人工智能模型对每个页面或文档进行分类,识别类型,如发票、合同或收据。根据分类结果排列和分组页面,以确保精确处理。
3. 基于分类的数据提取:
针对每个分类的文档类型实施特定的提取规则或模型。例如,从发票中提取发票号和总额,或识别合同中的各方和条款。这种有针对性的方法确保了与文档目的的精确数据提取。
简而言之,这是典型实施的详细流程。输出将是用户友好的,比如 JSON。
Claude 模型和 IDP

Claude 现在有两个旗舰模型,Haiku 和 Sonnet,Opus 现在是一个已弃用的模型。 如上图所示,输出比输入贵 4 倍,而 Haiku 比 Sonnet 便宜 12 倍。将这一点与上述 IDP 步骤联系起来,我们可以将模型归因于以下内容:
-
文档加载:Haiku 或/和 OCR。 将在下一节中展开,但 Haiku 可用于简单数据提取,能够生成 markdown 输出。这是一个 token 密集型的过程,不需要太多智能。尽管这些模型非常出色,但它们可能会出现错误和幻觉,因此最好始终将它们与 OCR 配对使用。
-
分类和文档拆分:Sonnet。 这两个步骤需要最多的智能。分类查看每个页面并决定如何分类,拆分则通过决定它们是否属于一起来聚合页面。图像对于两者都是必不可少的,以获得良好的结果。
-
提取:Haiku。 在流程的最后,我们不再需要那么多智能,因为繁重的工作已经完成。由于这是最 输出 token 密集型 的部分,非常适合结构化提取。
了解 Sonnet 和 Haiku 之间的定价动态对于优化成本至关重要。Sonnet 专门用于 高输入、低输出操作,而 Haiku 则相反。这种方法将提供一种解决方案,其性能可与完全 Sonnet 策略相媲美,但成本效益和可扩展性显著提高。
文档加载:提取和布局
在文档智能中,文档加载器 组件是流水线的起点。该组件负责从文档中提取文本和布局信息。我们将探讨两种实现文档加载器的版本:
-
仅使用图像输入
-
使用 PyPDF 提取文本和图像输入
版本 1:仅使用图像输入
我们直接将图像发送到 Claude 模型,而不进行任何先前的文本提取。这种方法利用了 Claude 的图像处理能力来提取文本并理解文档。
import anthropic
import base64
client = anthropic.Anthropic(
api_key="your_anthropic_api_key",
)
def load_image_as_base64(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def extract_data_from_image(image_path):
base64_image = load_image_as_base64(image_path)
response = client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=1000,
temperature=0,
system="You are an state of art OCR that extract markdown text from the image",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "##Content\n" + base64_image # Added content header
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": base64_image
}
},
{
"type": "text",
"text": "\nExtract and only return the markdown data:"
}
]
}
]
)
return response.content[0].text
# 示例用法
image_path = "path/to/document.jpg"
extracted_data = extract_data_from_image(image_path)
print(extracted_data)
版本 2:使用 PyPDF 提取文本和图像输入
在这个版本中,我们首先使用 PyPDF 从 PDF 中提取文本,然后将提取的文本和图像一起发送到 Claude 模型。
import anthropic
import base64
from PyPDF2 import PdfReader
import pdf2image
client = anthropic.Anthropic(
api_key="your_anthropic_api_key",
)
def extract_text_from_pdf(pdf_path):
reader = PdfReader(pdf_path)
text = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
text += page_text + "\n"
return text
def convert_pdf_to_image(pdf_path):
# Convert the first page of the PDF to an image
def extract_data_from_pdf(pdf_path):
text_content = extract_text_from_pdf(pdf_path)
base64_image = convert_pdf_to_image(pdf_path)
if not base64_image:
raise Exception("Failed to convert PDF to image.")
response = client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=1000,
temperature=0,
system="You are an state of art OCR that extract markdown text from the image",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": f"##Content\n{text_content}\n"
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": base64_image
}
},
{
"type": "text",
"text": "\nExtract and only return the markdown data:"
}
]
}
]
)
return response.content[0].text
# 示例用法
pdf_path = "path/to/document.pdf"
extracted_data = extract_data_from_pdf(pdf_path)
print(extracted_data)
为什么 OCR 很重要:幻觉
在文档智能中,OCR 往往是一切开始的基础。随着大语言模型对图像处理的兴起,OCR 的使用成为解决方案的一部分。让我们甚至不称之为 OCR,而是一个 文档加载器 组件,因为它可以是类似 Pypdf 的 数据检索库。
保留它的原因有两个:精度 和 成本。这种视觉模型有时会在清晰度低和手写文字方面遇到困难,而这对于 OCR 来说是一项掌握的任务。因此,您应该将两种方法结合起来使用,即 OCR 和图像,以避免可能出现的 1-5% 幻觉。图像将被用作 “结构映射指南”,换句话说,您不需要复杂的 OCR 服务来检测表格等内容,因为这些内容在图像中是可见的。
以下是一些直接的 OCR 工具,您可以使用:
-
Tesseract:无需介绍,但 open-ocr 需要。为您提供了一个可用于可扩展性的“无服务器,作为服务的 OCR”解决方案。
-
EasyOCR:EasyOCR 名副其实,易于设置和使用。支持 80 多种语言,非常适合一般性 OCR。- PaddleOCR: 在处理亚洲语言方面表现特别出色。
注意:如果您使用的是有效的 PDF 文件,而非扫描或图片,甚至可以跳过 OCR,使用其他工具如 Pypdf,它们也能很好地完成任务。
分类
在加载和准备我们的文档之后,下一个关键步骤是分类。这涉及根据图像数据确定文档类型,例如发票、合同或驾驶执照。Sonnet 将使用图像来执行此任务,方法非常简单直接。
import anthropic
import base64
client = anthropic.Anthropic(
api_key="your_anthropic_api_key",
)
def load_image_as_base64(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def classify_document_with_image_only(image_path):
base64_image = load_image_as_base64(image_path)
response = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1000,
temperature=0,
system="You are an AI assistant that classifies document images into categories.",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "##Content\nPlease classify the following document image.\n"
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": base64_image
}
},
{
"type": "text",
"text": """
##Classifications
Please classify the document into one of the following categories:
- Invoice
- Contract
- Receipt
- Driver License
##Output Format
Provide your answer in JSON format:
{
"classification": "<Category>",
"confidence": <confidence_score_between_1_and_10>
}
##Valid JSON
"""
}
]
}
]
)
try:
result = json.loads(response.content[0].text)
return result
except json.JSONDecodeError:
# 如果响应不是有效的 JSON,则回退
return {
"classification": "Unknown",
"confidence": 0
}
# 示例用法
image_path = "path/to/document.jpg"
classification_result = classify_document_with_image_only(image_path)
print("Document Classification:", classification_result["classification"])
print("Confidence Score:", classification_result["confidence"])
JSON 响应提供了文档分类和置信度分数,我们解析后用于下游任务。然后,您可以根据 AI 的情绪设计您的业务逻辑。Claude 不提供 logprobs,这在其他提供商如 OpenAI 或 huggingface 中可用,可作为检查置信度水平的更优方式。
高级分类
上述方法是一个简单的方法,对于大多数情况来说已经足够了。如果您最终需要一个生产就绪的、具有强大分类系统的 LLMs,您可以查看这篇文章。
文档拆分
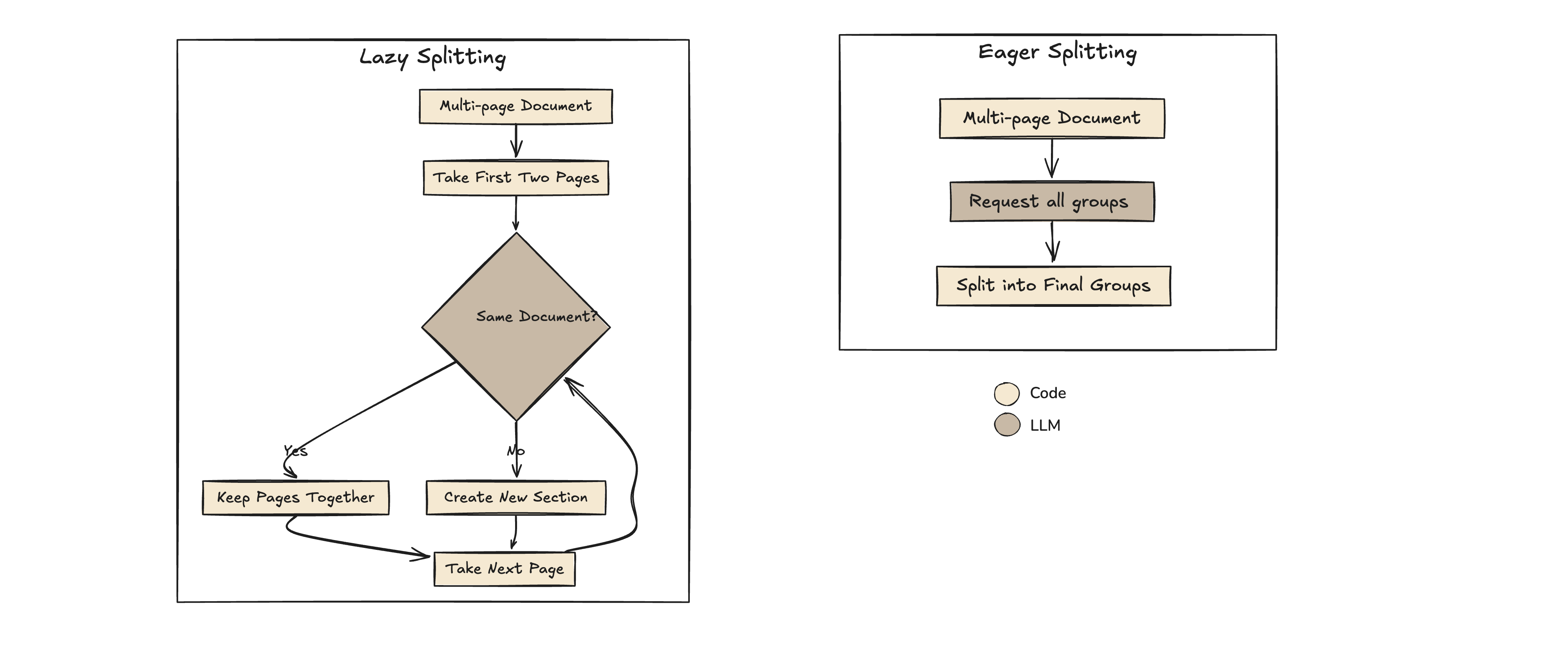
在文档处理中,拆分可以将合并文件中的单个文档或部分分开。在处理批量文档时,这一任务尤为重要,因为不同部分可能需要不同的处理,始终使用 Sonnet。这可以通过两种策略实现:积极和懒惰。
积极 vs. 懒惰方法
根据文档大小和页面之间关系的复杂性,积极和懒惰拆分具有不同的用例。
积极拆分 积极拆分在单次处理中处理文档,一次性识别和划分所有部分。对于上下文大小不限制性能的小到中等大小文档效率高。
积极拆分的优势:
-
速度:处理更快,因为所有拆分点都是预先确定的。
-
简单性:适用于完全适合模型上下文窗口的文档,便于实现。
懒惰拆分 另一方面,懒惰拆分逐步以块的方式处理文档,每次评估一小组页面以确定它们是否属于一起。在这种情况下,处理并检查连续性的两页组,使其能够有效扩展到更大的文档。
懒惰拆分的优势:
- 可扩展性:适用于超出模型上下文窗口的文档。
懒惰拆分需要处理块的连续性并在拆分过程中保持状态,这可能增加复杂性,但确保了可扩展性。
推荐方法
对于我们的 IDP 用例,积极拆分是合适的,因为它提供了简单性以进行演示。
以下是在文档处理流水线中实现积极拆分的 Python 代码:
def eager_split_document(document_text):
prompt = f"""##Document Text:
{document_text}
##Instructions:
1. 首先,分析文档并确定逻辑部分
2. 对于每个部分,根据内容连续性确定属于它的页面
3. 解释每个部分的原因
4. 以 JSON 格式返回结果
##Output Format:
{{
"reasoning": "这些页面为何属于一起的解释",
"groupOfDocuments": [
{{
"reasoning": "这些页面为何属于一起的解释",
"pages": [1, 2]
}}
]
}}
请逐步思考并提供您的分析。
只返回 JSON,不要返回其他内容。
##Valid JSON"""
response = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1000,
temperature=0,
system="You are a document processor that identifies logical sections in a document using careful analysis.",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
}
]
}
]
)
try:
# 解析 JSON 响应
result = json.loads(response.content[0].text)
return result
except json.JSONDecodeError:
# 解析错误的回退
return {
"groupOfDocuments": [],
"error": "Failed to parse response"
}
提取
一旦您对文档进行了分类和组织,下一个重要步骤就是提取。这个过程涉及根据文档类型从每个文档中检索特定字段,比如说对于发票,您会提取发票号码、日期、总金额和供应商名称。对于合同,您会收集合同 ID、涉及方、生效日期和关键条款。
为了执行这种提取,我们将使用上面讨论过的Claude 3.5 Haiku。我们将介绍**Instructor**库,它简化了与 Claude 这样的 LLMs 互动,通过与 Pydantic 模型集成进行数据验证和解析。
使用 Instructor 进行结构化提取
Instructor 是一个 Python 库,允许您使用 Pydantic 定义您的预期输出模式,并为您处理提示创建和响应解析。以下是您可以实现提取过程的方法:
步骤 1:使用 Pydantic 定义数据模型
首先,使用 Pydantic 为每种文档类型定义数据模型。
from pydantic import BaseModel
from typing import List
class InvoiceLineItem(BaseModel):
description: str
quantity: float
unit_price: float
amount: float
class Invoice(BaseModel):
invoice_number: str
invoice_date: str
total_amount: float
supplier_name: str
line_items: List[InvoiceLineItem]
class Contract(BaseModel):
contract_id: str
parties: List[str]
effective_date: str
terms_summary: str
步骤 2:实现提取函数
接下来,创建一个函数,该函数使用 Instructor 发送提取请求到 Claude 并将响应解析为预期的数据模型。由于我们已经有了第一次提取的 markdown 内容,因此可以跳过图像。
import instructor
from anthropic import Anthropic
client = instructor.from_anthropic(Anthropic(api_key="your_anthropic_api_key"))
def extract_document_fields(content, document_type):
if document_type == "Invoice":
response_model = Invoice
system_prompt = "You are an AI assistant that extracts invoice data from text."
elif document_type == "Contract":
response_model = Contract
system_prompt = "You are an AI assistant that extracts contract data from text."
else:
raise ValueError(f"Unsupported document type: {document_type}")
# 使用 Instructor 启用的客户端
instructor_client = instructor.from_anthropic(client)
resp = instructor_client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=1000,
system=system_prompt,
messages=[
{
"role": "user",
"content": f"""Extract the data from the following {document_type.lower()} and provide it in JSON format matching the {document_type} model.
{document_type} Text:
{content}
"""
}
],
response_model=response_model,
)
return resp
```## 使用 ExtractThinker
我们探讨了智能文档处理(IDP)工作流程,并提供了一个可以实施的逐步指南。或者,您可以使用 **[ExtractThinker](https://github.com/enoch3712/ExtractThinker)**,这是一个专为大语言模型设计的开源 IDP 库。我们讨论的所有内容都可以用几行代码轻松实现。
### 安装 ExtractThinker
首先,请确保已安装 ExtractThinker:
```typescript
pip install extract-thinker
定义数据模型(合同)
我们将以相同的方式声明,但使用 Contract 而不是 BaseModel。Contract 在这里包含了传统 pydantic 对象之外的额外逻辑,但使用方式相同。
from extract_thinker import Contract
from pydantic import BaseModel
from typing import List
class InvoiceLineItem(BaseModel):
description: str
quantity: float
unit_price: float
amount: float
class InvoiceContract(Contract):
invoice_number: str
invoice_date: str
total_amount: float
supplier_name: str
line_items: List[InvoiceLineItem]
class DriverLicenseContract(Contract):
name: str
date_of_birth: str
license_number: str
expiration_date: str
设置流程
接下来,我们将设置 Extractor 和 Process,DocumentLoader,并分配 LLM 模型(可以作为组件)。请注意,DocumentLoader 和模型都是相同的。
from extract_thinker import Extractor, Process, Classification, SplittingStrategy
from extract_thinker.document_loader import DocumentLoaderPyPdf
from extract_thinker.splitter import ImageSplitter
import os
# 初始化 Extractor
extractor = Extractor()
extractor.load_document_loader(DocumentLoaderPyPdf())
extractor.load_llm("claude-3-5-haiku-20240307") # 用于提取
# 定义分类
classifications = [
Classification(
name="Driver License",
description="这是驾驶执照",
contract=DriverLicenseContract,
extractor=extractor
),
Classification(
name="Invoice",
description="这是发票",
contract=InvoiceContract,
extractor=extractor
)
]
# 初始化 Process
process = Process()
process.load_document_loader(DocumentLoaderPyPdf())
process.load_splitter(ImageSplitter("claude-3-5-sonnet-20241022",
SplittingStrategy.EAGER) # Eager 是默认值
如果需要,您可以为每个分类使用多个 Extractor 组件。例如,如果需要简单提取收据,只需 日期 和 税号,那么只需要一个小模型(例如 Llama 3.2 3b),而另一个则需要 Haiku。
处理文档
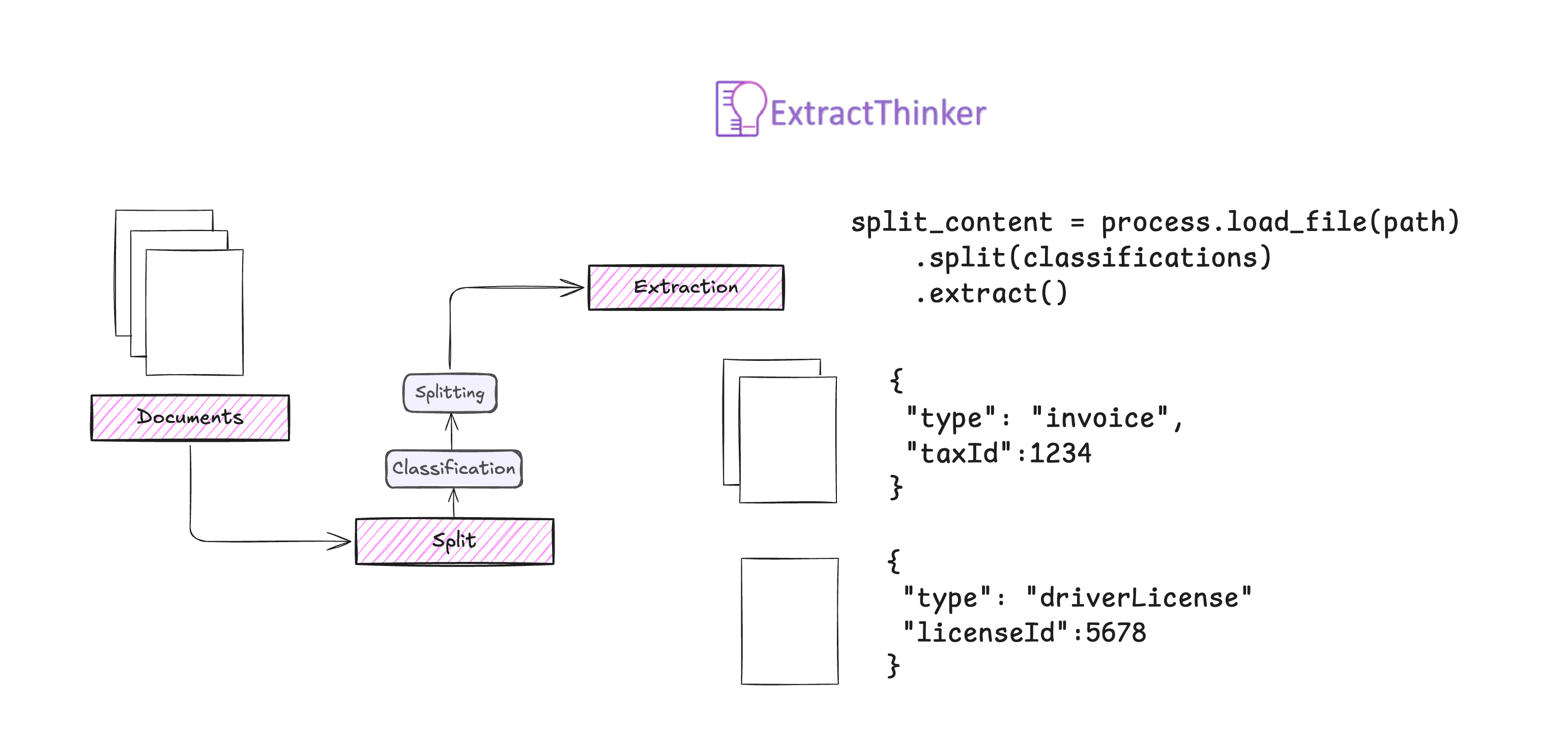
现在,我们可以通过加载文档、拆分文档并根据分类提取数据来处理文档。
# 您的文档路径
path = "path/to/your/document.pdf"
# 处理文档:加载、拆分、分类和提取
split_content = process.load_file(path)\
.split(classifications)\
.extract()
# 'split_content' 将包含从文档中提取的数据
for content in split_content:
print(content.json(indent=2))
结论
通过利用像 Claude 3.5 这样的模型,并策略性地利用 Haiku 和 Sonnet,我们可以显著提高智能文档处理(IDP)工作流的效率和准确性。这种方法降低了成本,提高了可扩展性,并为处理各种文档类型提供了系统化方法,而无需依赖昂贵的供应商锁定解决方案。
ExtractThinker 简化了这些 IDP 流程的实施,使您能够专注于应用程序逻辑,而不是大语言模型交互的复杂性。
智能文档处理(IDP)是一门掌握的科学,也是在大语言模型革命之后才出现的。在我今年进行的多个实施中,IDP 和提取的唯一问题,目前是由用户或图像质量不佳引起的,需要处理对比度和其他规格。