"...拥有能够相互交互以追求其所有者目标的AI系统,在此过程中运用合作、协调和谈判等社交技能。我坚信,这个梦想必须成为AI未来的核心部分。"
— 迈克尔·伍尔德里奇,牛津大学计算机科学系教授兼AI项目主任(伦敦阿兰·图灵研究所)
仅仅提示是不够的
"提示"这个词在2022年中期左右成为了一个热门词汇。在YouTube和Twitter等平台上,任何想要表明自己专注于AI的人都开始采用"提示人"、"提示向导"或"提示女王"等标题。尽管这可能不是最可持续的策略。
好的提示在一段时间内带来了令人印象深刻的结果,但我们很快就习惯了这些结果,它们不再有魔力。它们变成了标准。这本身并不是坏事,但对于习惯了快速、重大技术进步的客户群体来说,这个标准并不足够好。此外,用户还遇到了一些限制,比如幻觉和听起来很普通的文本。
因此,不足为奇的是,研究人员和普通用户开始制定新技术来改善LLM的性能。我们中的一些人甚至发现,通过让ChatGPT误以为它在对话结束时会得到200美元,它的输出将显著改善。
但是,情况似乎正在迅速改变。微软CEO萨蒂亚·纳德拉表示,多代理运行时"将成为我们这个时代的关键运行时",而安德烈·卡尔帕西最近宣布了从"提示工程 → 流程工程"的范式转变。
突然之间,某些词语和想法开始在大众中流行起来:流程、迭代和协作式AI代理。从社交媒体上的数量庞大的新项目来看,这些术语似乎已经开始捕捉我们的想象力。
那么,什么是代理?
代理只是一个可以行动的实体。这个概念已经存在了数千年以某种形式,但随着人工智能的兴起,特别是自动驾驶汽车的兴起,它变得越来越受关注。
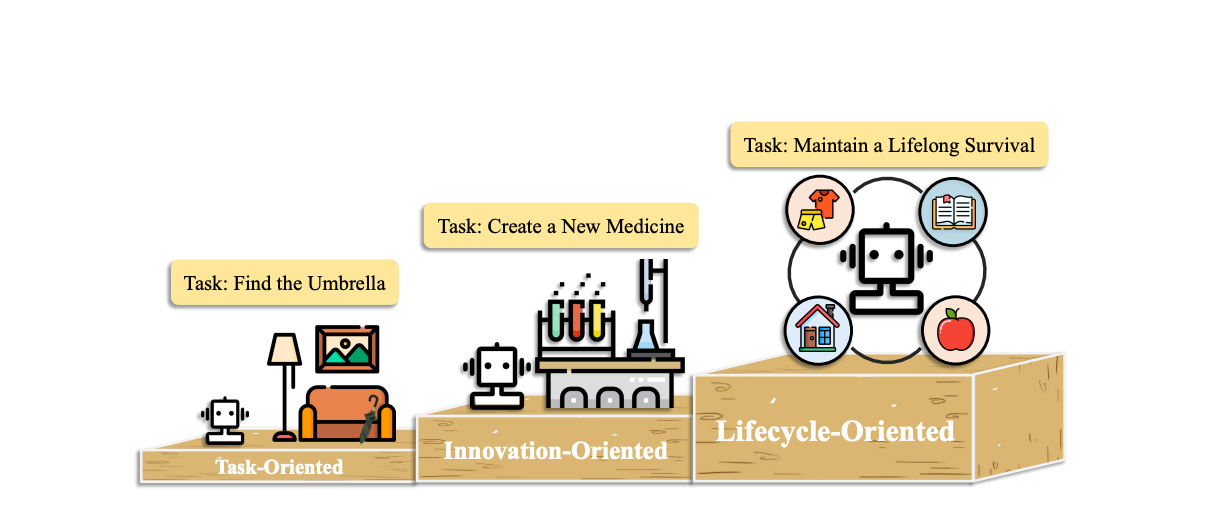
最近的一项研究强调了代理提供的"迭代思维"的重要性。根据同一项研究,代理可以根据能力分为3类:
-
任务导向 ➡️ 在这个级别上,代理能够自动化乏味、重复的任务,例如:抓取数据 -> 提取关键点 -> 总结
-
创新导向 ➡️ 在医学或科学数据上训练的代理可能具有科学突破的能力,而且已经有证据表明这已经在发生
-
AGI 或 生命周期导向 ➡️ 通用的超级智能,能够进行规划,可能会从一个代理团队中而不是一个超大型LLM中出现。
微软知道如何做出良好回应
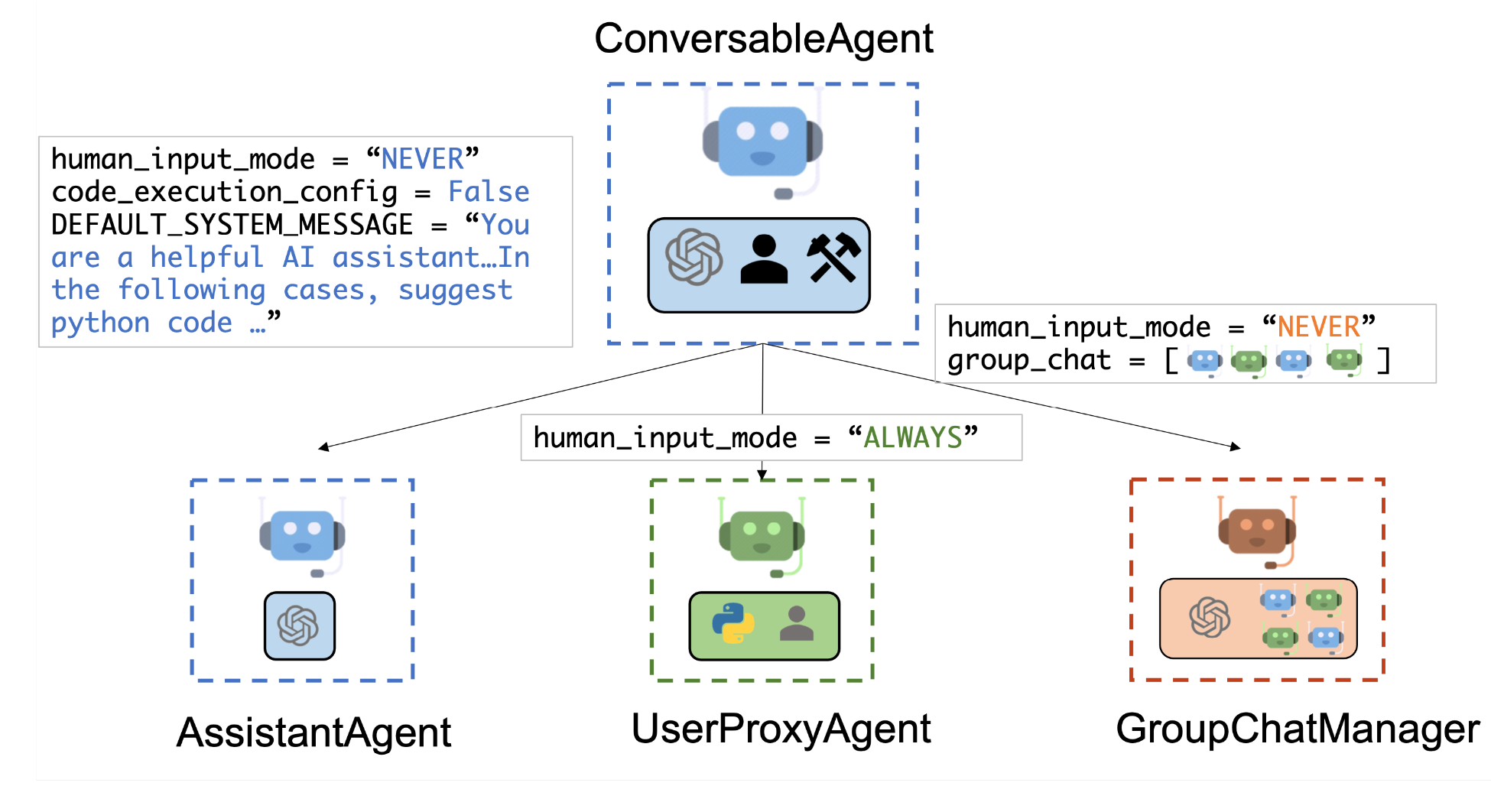
Autogen的推出再适合不过了。随着范式的转变,越来越多的人开始探索自主代理团队,Autogen团队开发了一个轻巧灵活的框架。这种创新使每个人都能够创建自己的代理团队,包括非程序员。
让我们谈谈Autogen Studio,如何安装它,如何使用像mistral和gemini这样的api模型以及本地LLM。让我们一起探索吧。
你更喜欢图形还是文本?
如果你是一个视觉型的人,你可能更喜欢基于节点的编辑器,而不是Autogen Studio的用户界面,这里有一个看起来不错的编辑器"x-force",它的效果非常好。
安装
对于非技术用户来说,这部分可能是唯一的新的和令人生畏的部分。但它仍然相当简单,只需要几个步骤。
打开一个文本编辑器(我使用的是VSCode)和一个新的终端。接下来,你需要安装和激活一个虚拟环境。这是一种整理项目文件夹和文件并将其与其他项目分开的好方法。在终端中输入:
python3 --version
你需要确保版本是3.3或更高。选择一个你想要创建虚拟环境的目录,并给它一个适当的名称(_any_name只是一个示例):
python3 -m venv any_name
最后,在Unix或MacOS上激活环境:
source any_name/bin/activate
在Windows上激活:
source any_name/bin/activate.bat
激活后,你可以继续下载Autogen Studio:
python -m install autogenstudio
这就是你需要做的全部!
在下一步中,我建议你决定你想要使用哪种类型的模型。这个决定将影响你的下一步。
可用的模型有:
-
openai
-
其他提供api的模型 - gemini或mistral
-
本地模型
我将解释如何执行每个选项,但让我们从#1 - OpenAI开始。
1. OpenAI模型
这是最简单的选择。如果你想使用任何openai模型,你需要设置环境变量:
export OPENAI_API_KEY=your-key
完成这一步后,通过输入以下命令来运行Autogen:
autogenstudio ui --port 8081
希望终端中出现以下行:
INFO: Started server process [24451]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8081 (Press CTRL+C to quit)
你应该导航到http://127.0.0.1:8081,你将能够看到Autogen Studio的用户界面:
让我们专注于左侧带有技能、模型、代理和工作流程标签的选项卡,这些是Autogen的核心概念,让我们分解每个词的含义:
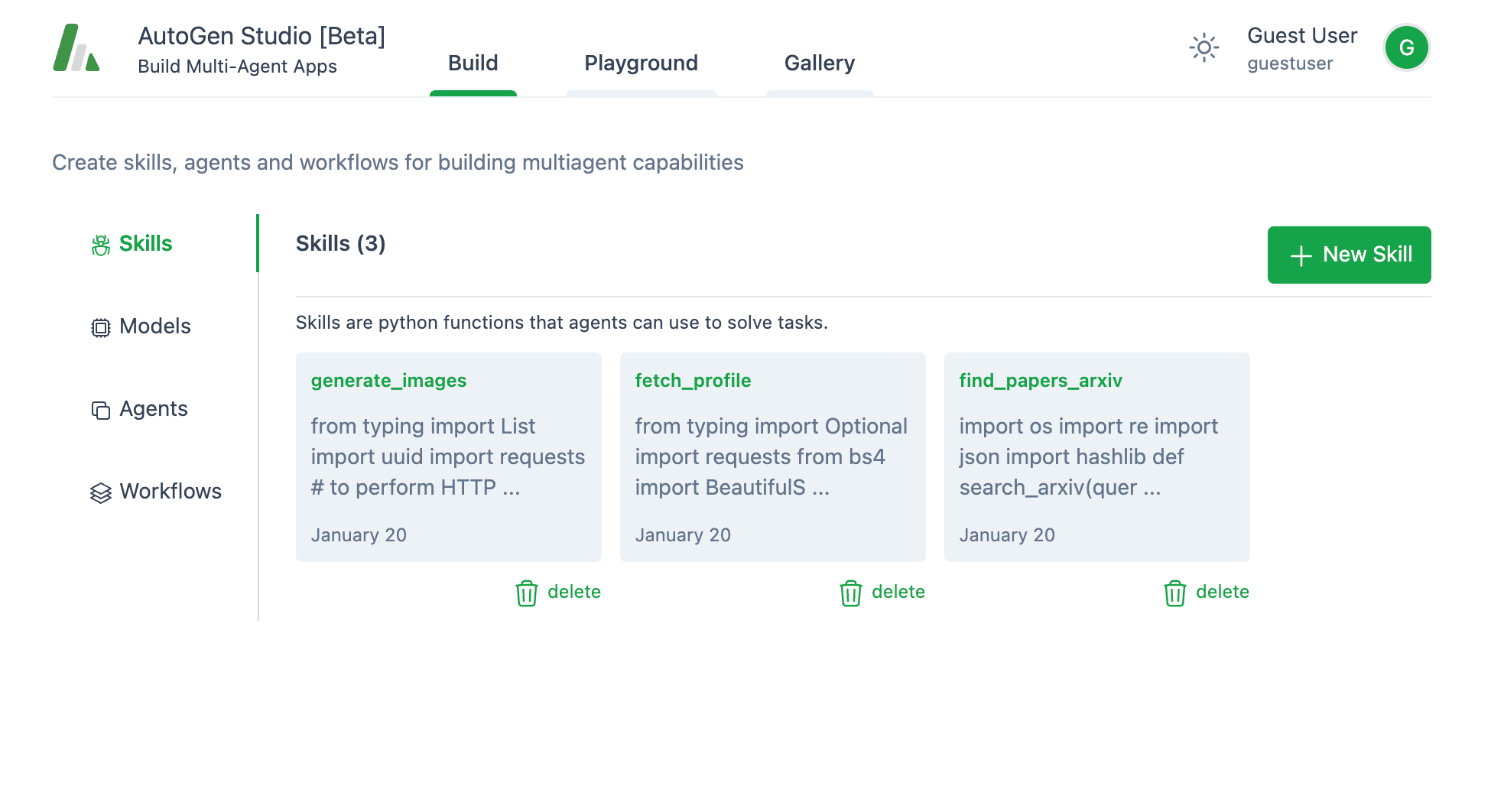
1. 技能:
你将能够看到3个带有预定义技能的选项卡 - 或者说代理可以使用的工具。每个技能基本上都是代理可以用来解决任务或通过api与外部世界交流的Python代码。
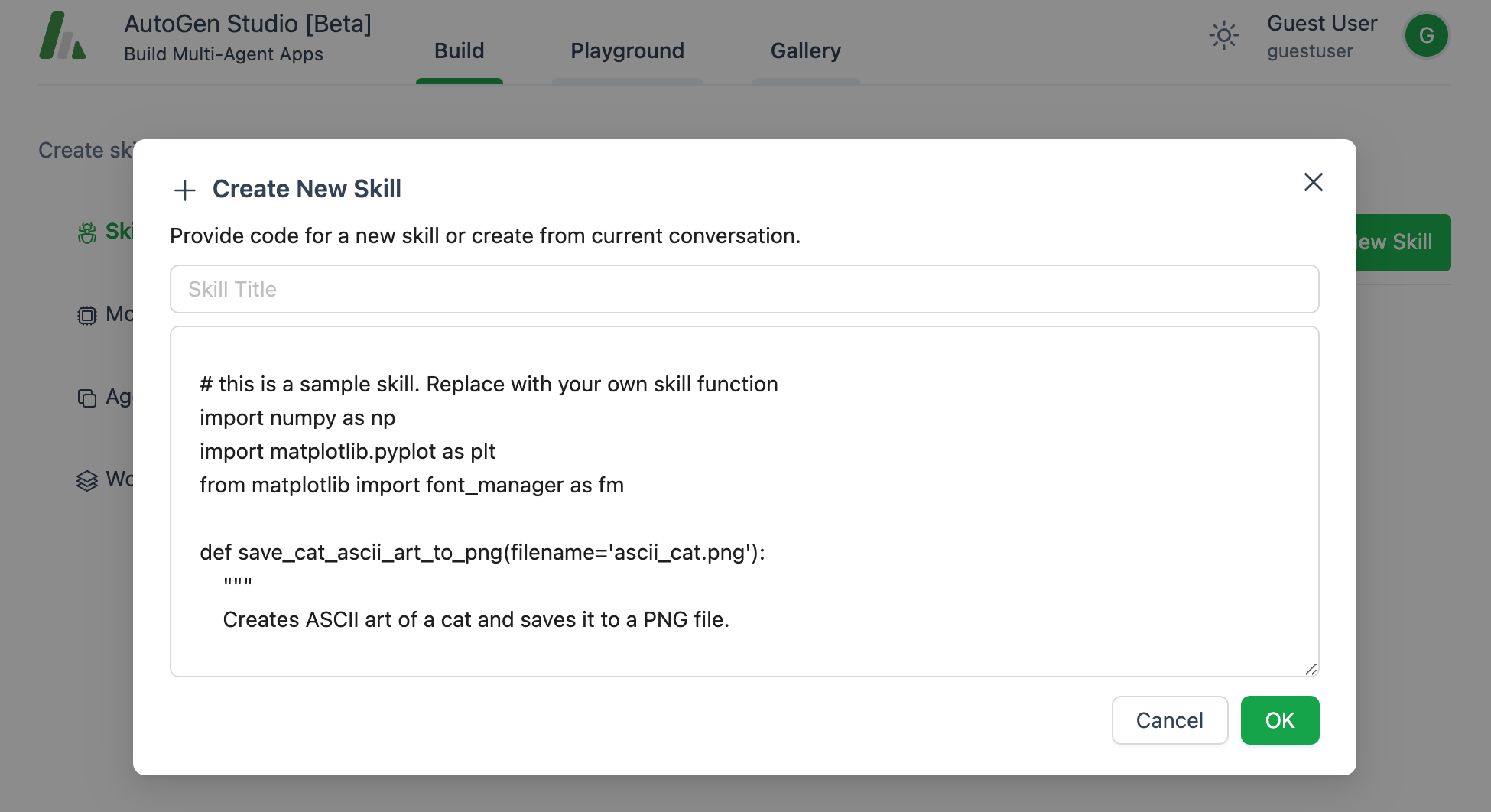
你也可以编写自己的自定义代码并保存以供以后使用。只需点击**+ 新技能**按钮:
2. 模型:
非常直观。Autogen带有3个预定义的模型配置:azure gpt-4、gpt-4–1106-preview和zephyr-7b。
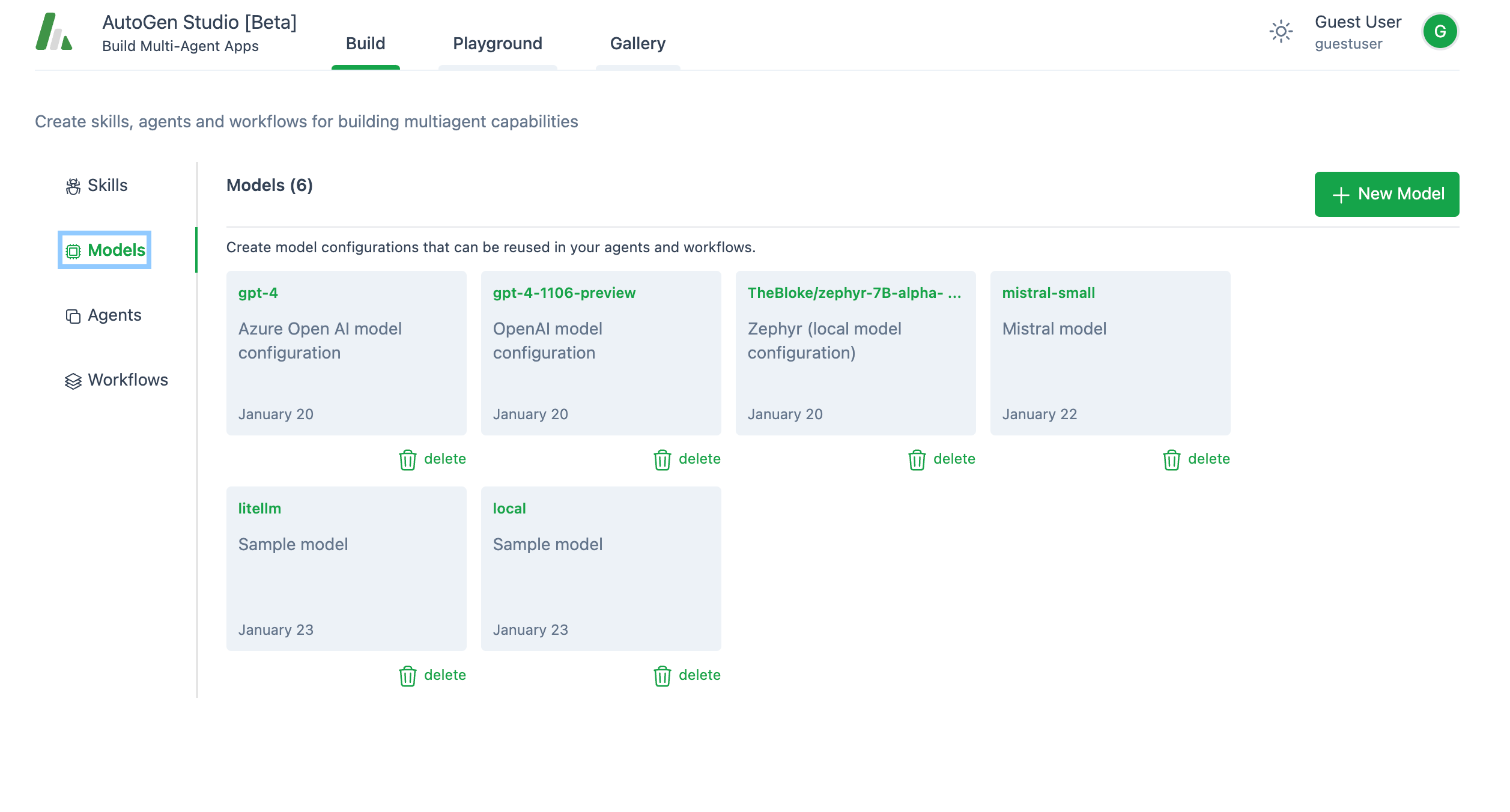
当然,你可以通过点击**+ 新模型按钮添加新模型。由于这是一个openai演示**,所以不需要添加新模型(代理将使用gpt-4-preview,它已经预定义)。但如果你需要除openai之外的任何其他模型,你需要添加一个新模型(稍后会详细介绍)。
3. 代理:
将有两个预定义的代理:
-
"primary_assistant" - 作为定义良好的代理的模式非常有用。所以不要删除它,相反,我建议你将其系统提示的一些通用部分复制到你想要创建的任何新代理中。
-
"userproxy" - 代表你执行代码。
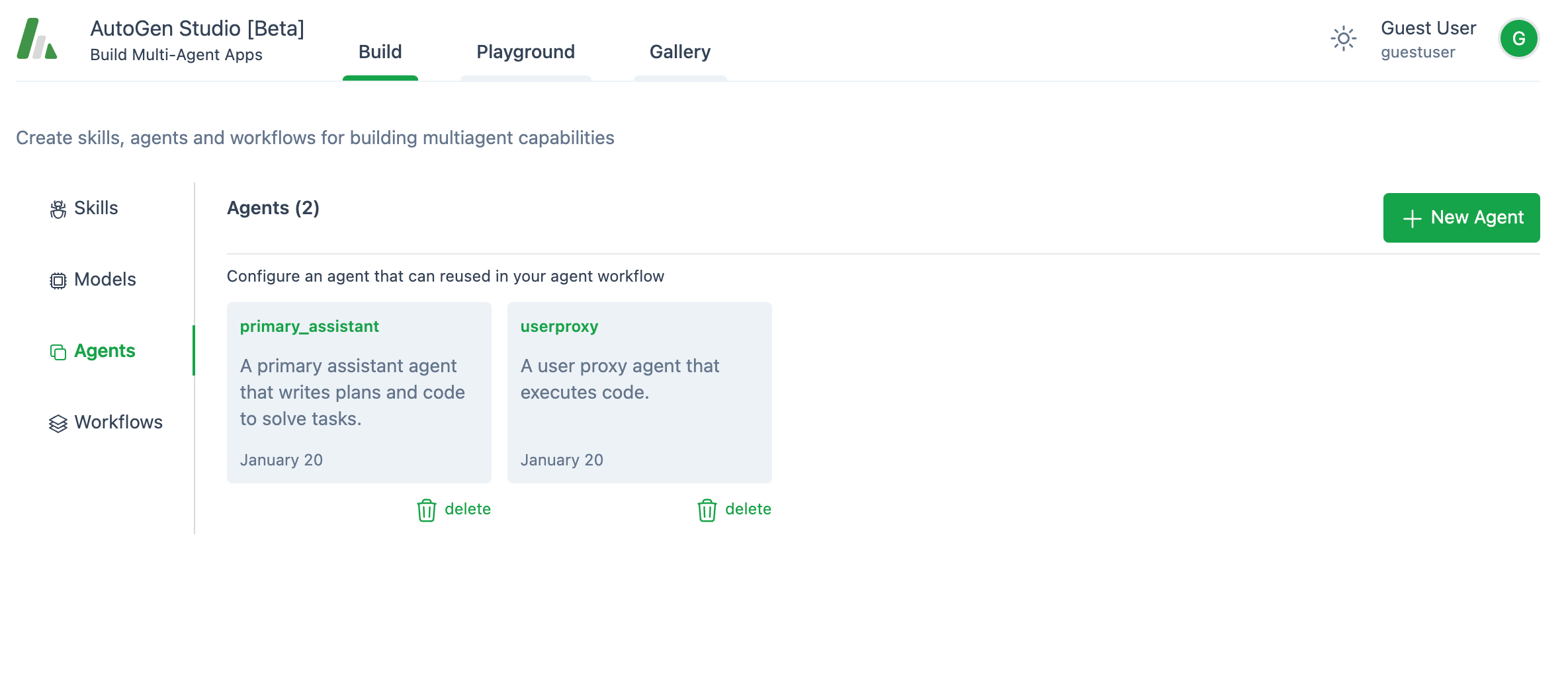
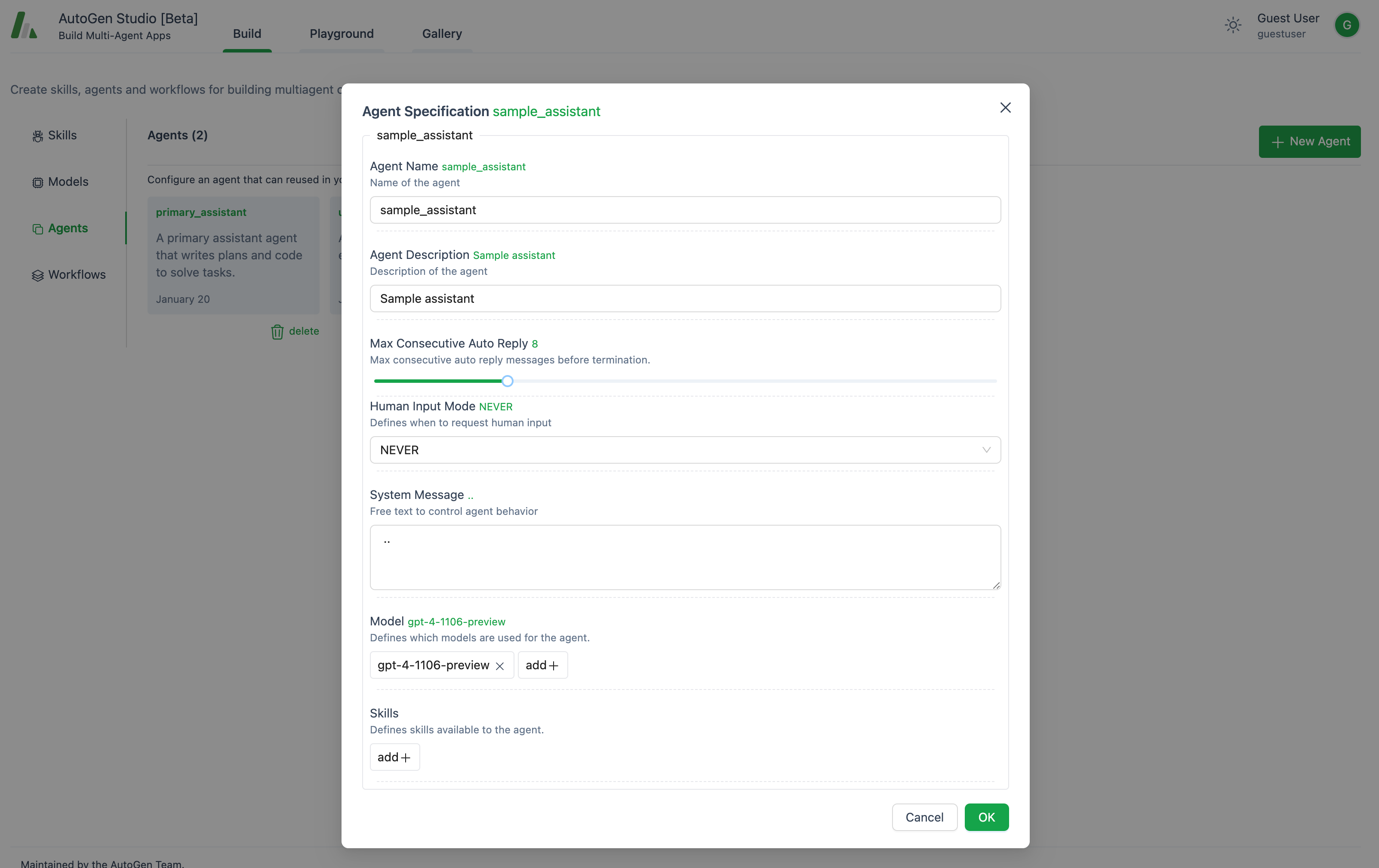
如果你想添加自定义代理,只需点击**+ 新代理按钮。在这里,你将定义代理在描述和系统消息**字段中的专业知识。你还可以选择代理将使用的模型,并为其分配特定的技能。
3. 工作流程:
我的文章让你睡着了吗 😴?希望不是,因为我保证下一部分会更有趣!
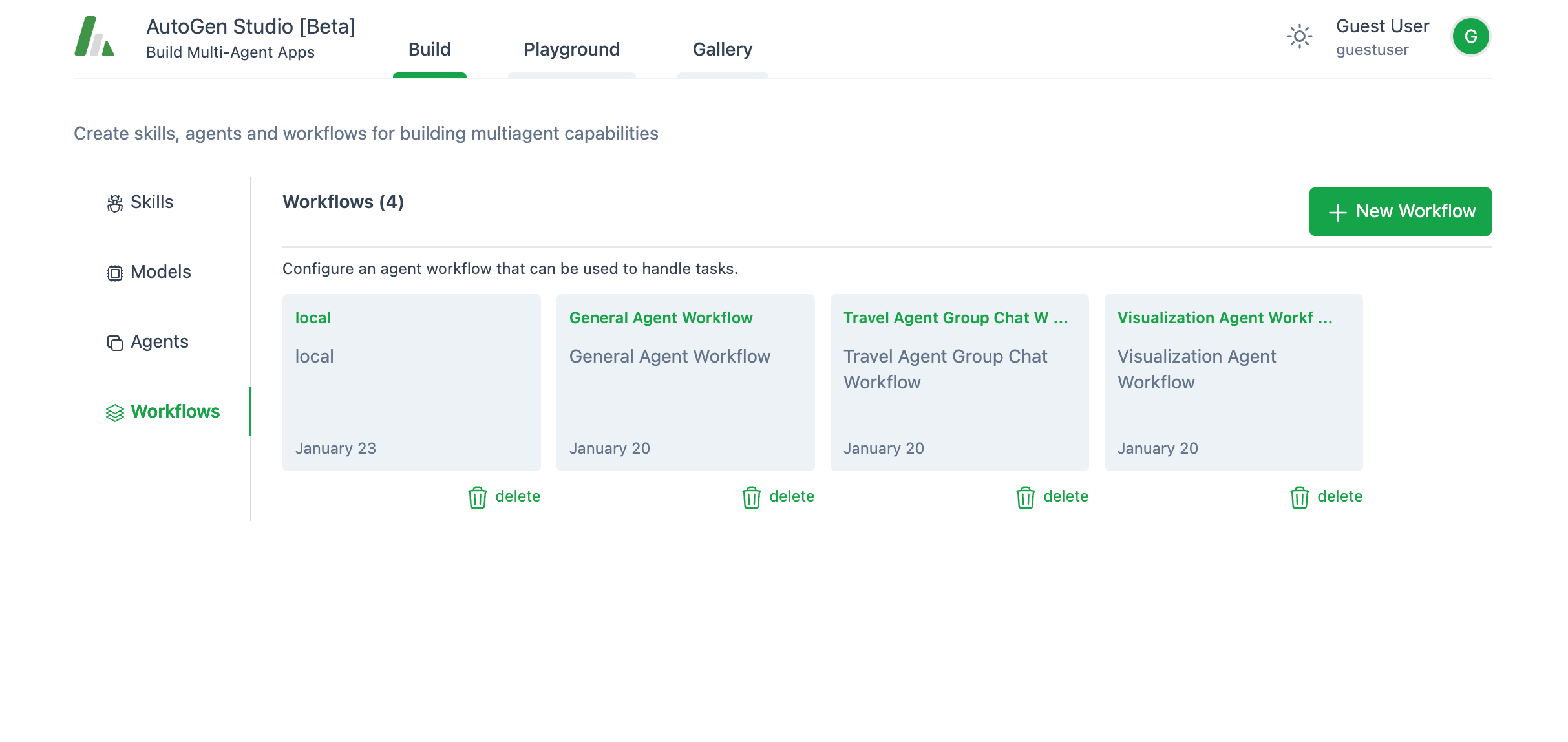 工作流是一个定义了代理之间如何相互交互的功能。当你想创建一个新的工作流时,你有两个选项:
工作流是一个定义了代理之间如何相互交互的功能。当你想创建一个新的工作流时,你有两个选项:
- 两个代理之间的聊天
- 群聊
如果你选择两个代理之间的聊天,事情就很简单了,代理只需互相交谈,直到达成某种解决方案。
但是当你有一个群聊时会发生什么呢?
我们来看一下。
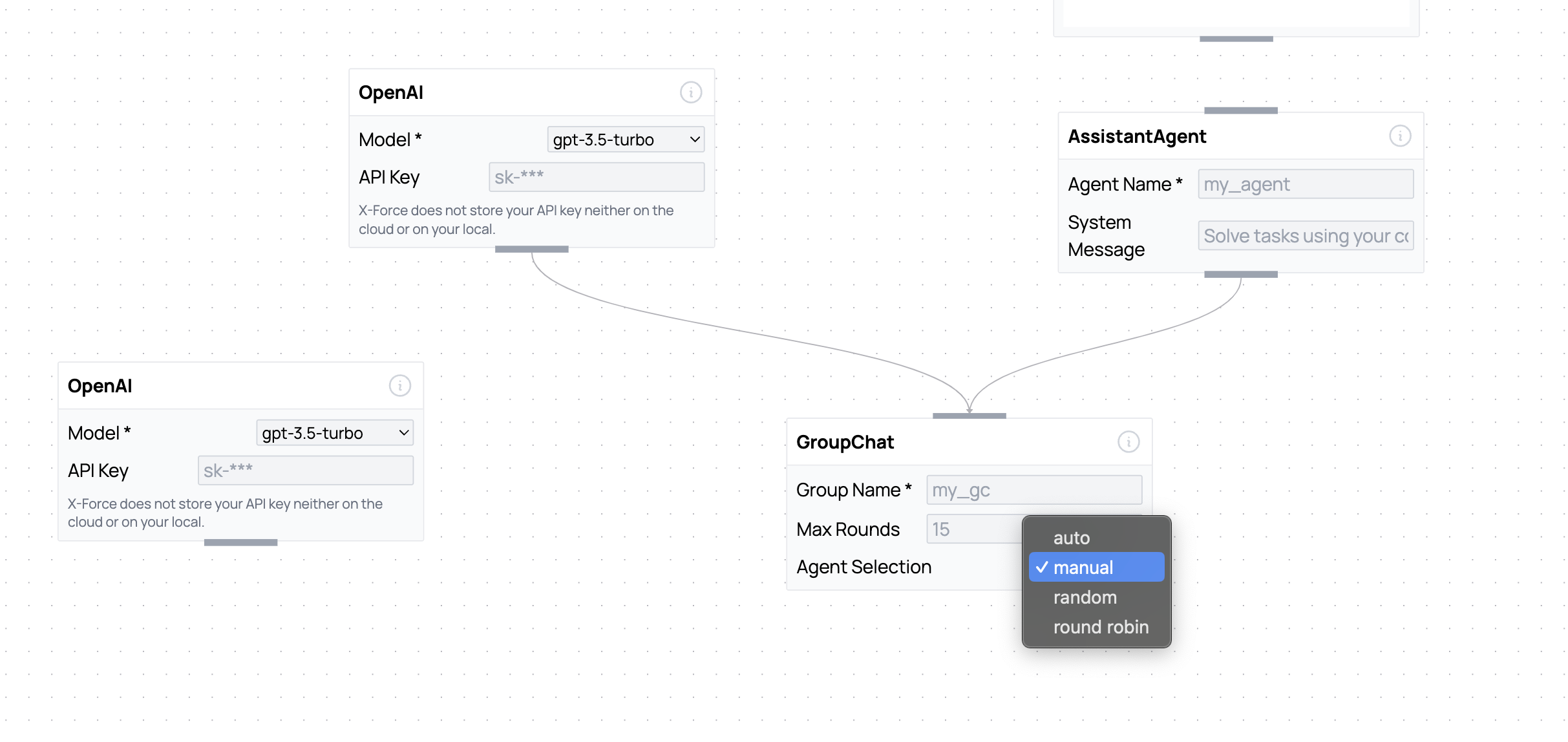
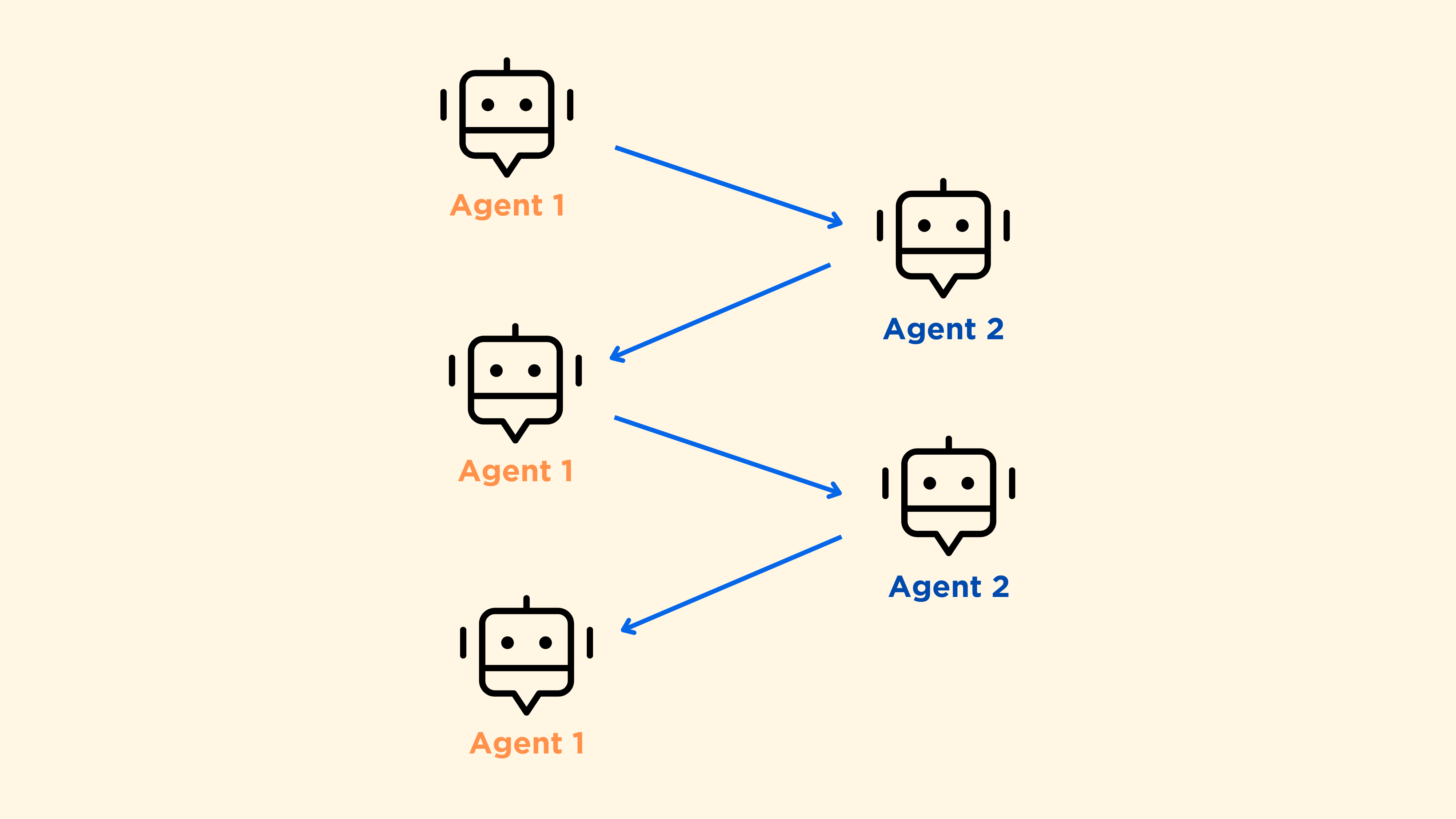
想象一下,你有一个由10个人组成的工作小组。他们之间可能会有哪些可能的互动方式呢?如果是一群朋友,那可能是非等级制(所有团队成员都是平等的)。现在想象一下,这群朋友实际上是一群代理,它看起来就像这样:
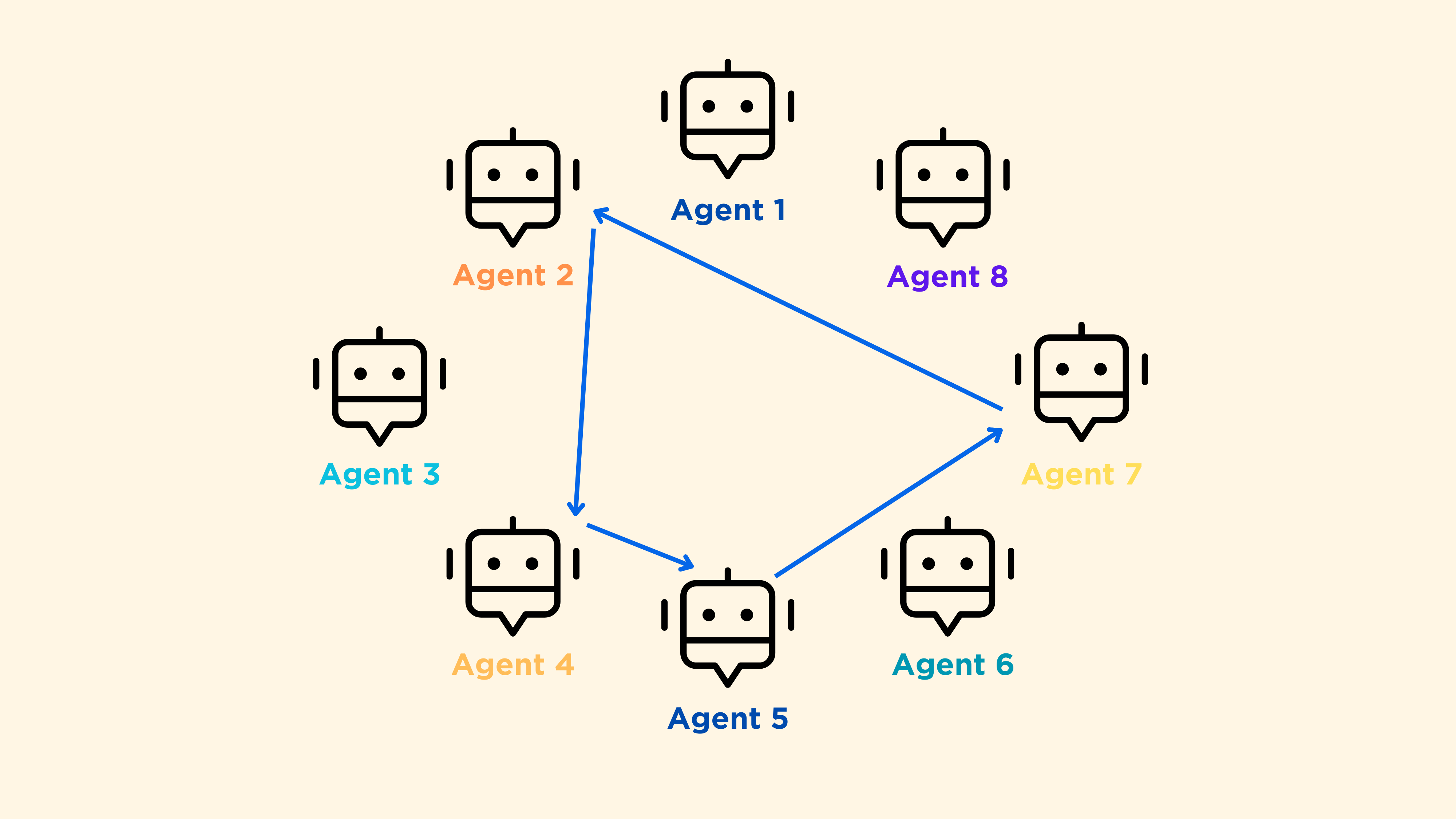
如果是一个教师+学生的班级,那可能是等级制(教师选择下一个发言的学生)。这种类型的对话是Autogen中的代理之间的默认通信方式。有一个聊天管理器会动态选择最合适的下一个“发言者”。
相比之下,在Autogen中有更多可能的工作流。实际上,通过修改代码,你可以选择下一个发言者。然而,对于Studio来说,截至2024年1月底,你只能使用带有“auto”标签的默认群聊。
其他工作流可以通过我之前提到的可视化编辑器-x-force来实现:
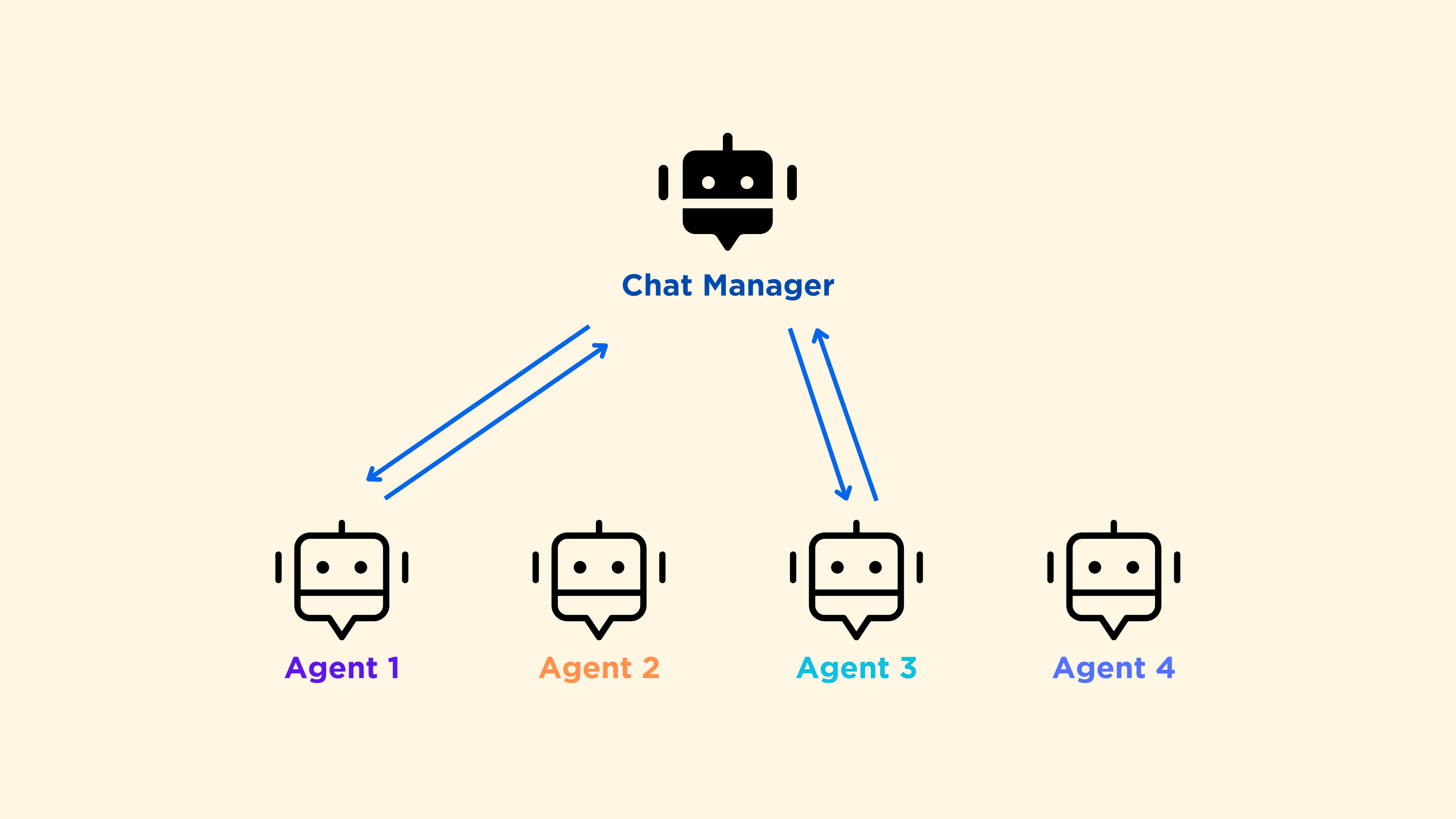
手动和随机的工作流很容易理解,但我想更详细地解释一下“轮流”这个工作流。描述这个工作流的最好词语是“顺序”:
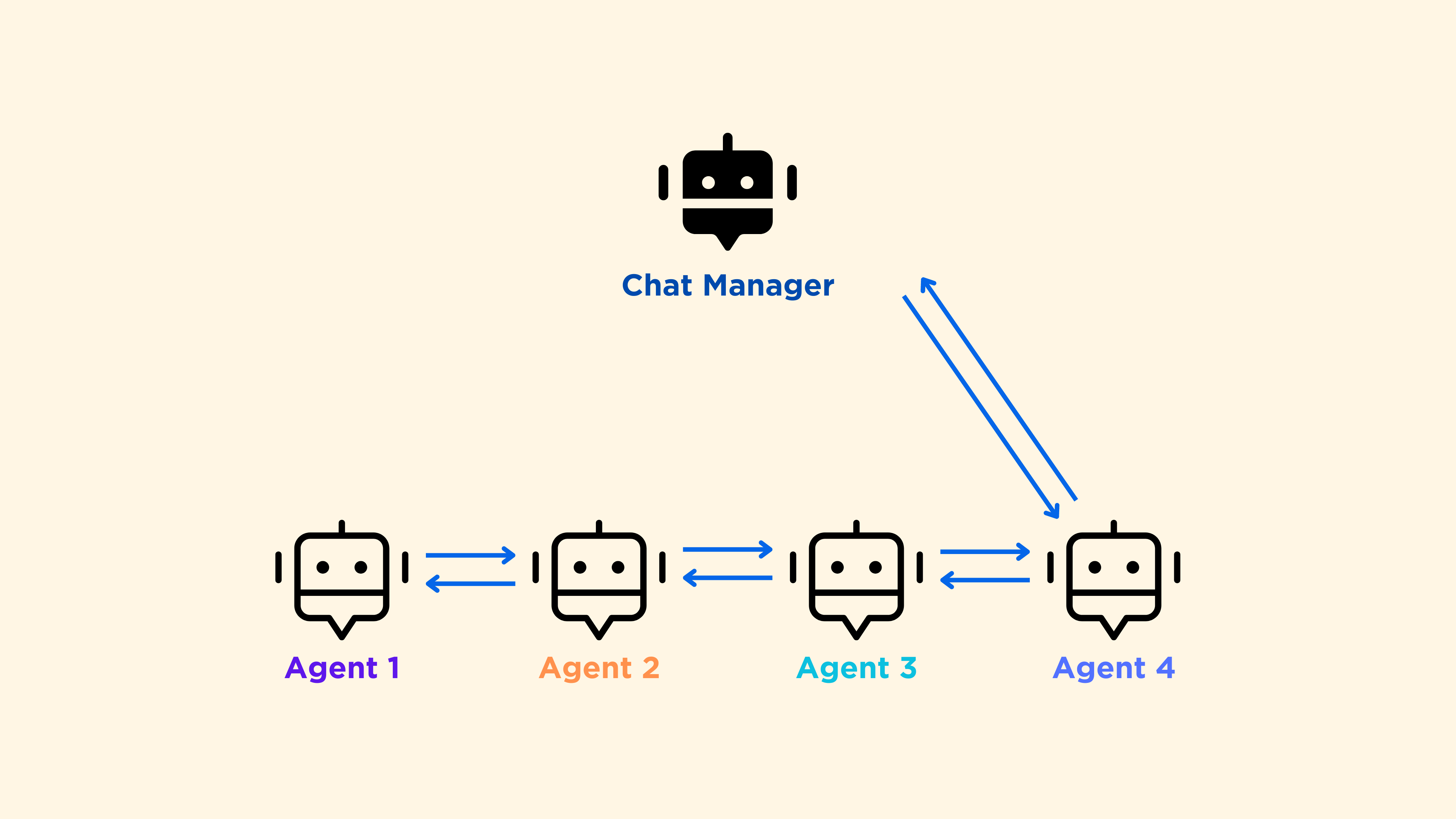
这是一种线性和固定的代理之间的通信方式,但最后仍然有一个聊天管理器接收信息。
现在你已经准备好了,可以给代理分配任务了。要开始一个会话,请转到playground标签:
为了与代理开始一个新的会话,你需要定义一个工作流:
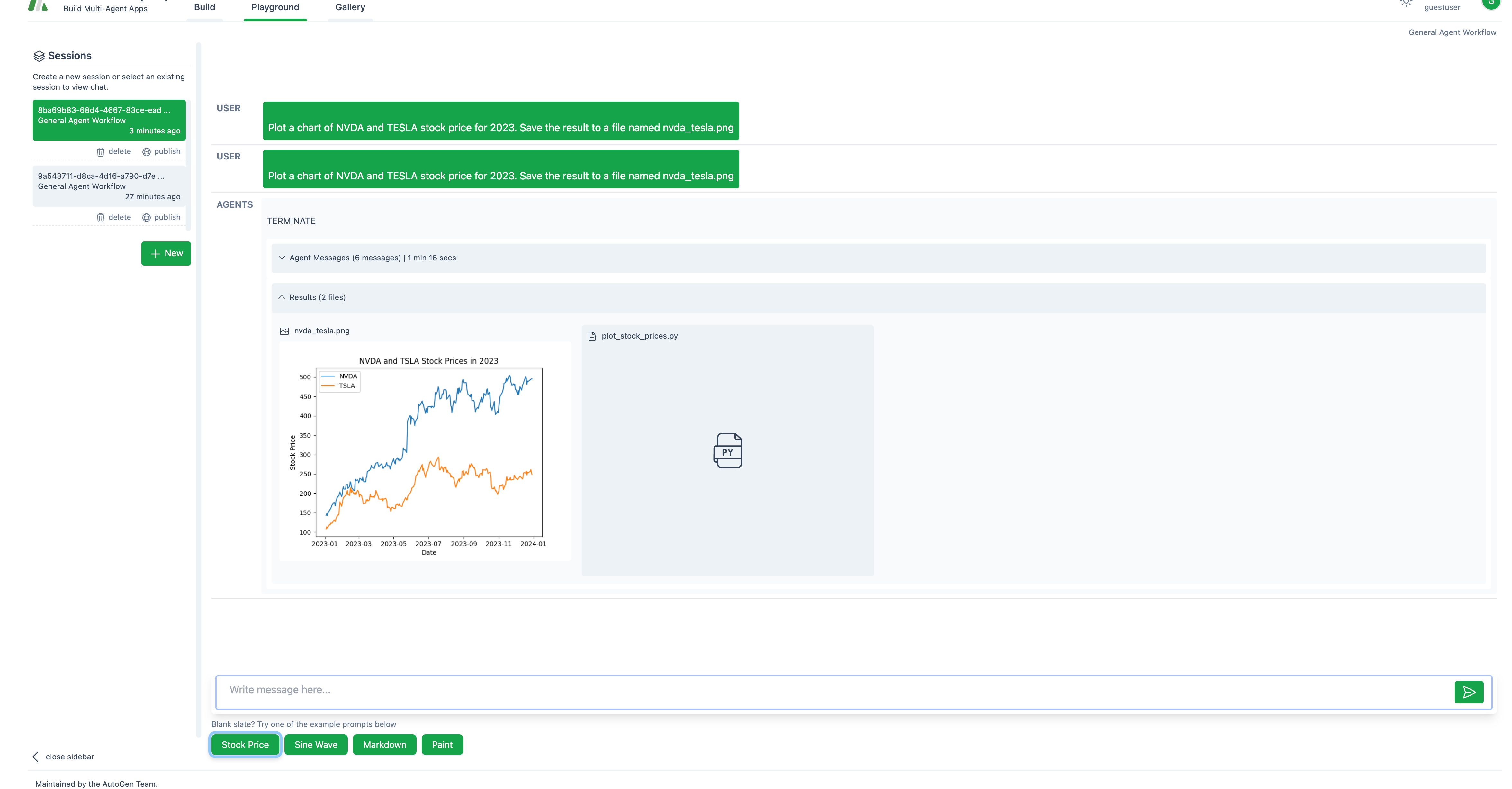
现在你可以开始与OpenAI代理进行对话了:
2.其他API模型-Gemini和Mistral
假设你想使用免费的Gemini API(其他模型如Mistral的过程相同)。
你需要首先设置一个环境变量:
export GEMINI_API_KEY=your-key
你还需要安装一个额外的软件包(仅适用于Gemini,其他模型不需要):
pip install -q google-generativeai
使用我之前提到的命令运行autogen:"autogenstudio ui - port 8081"。然后添加一个新模型。
如果你尝试使用autogen的UI窗口配置模型,是行不通的,因为你需要有一个与OpenAI兼容的端点。
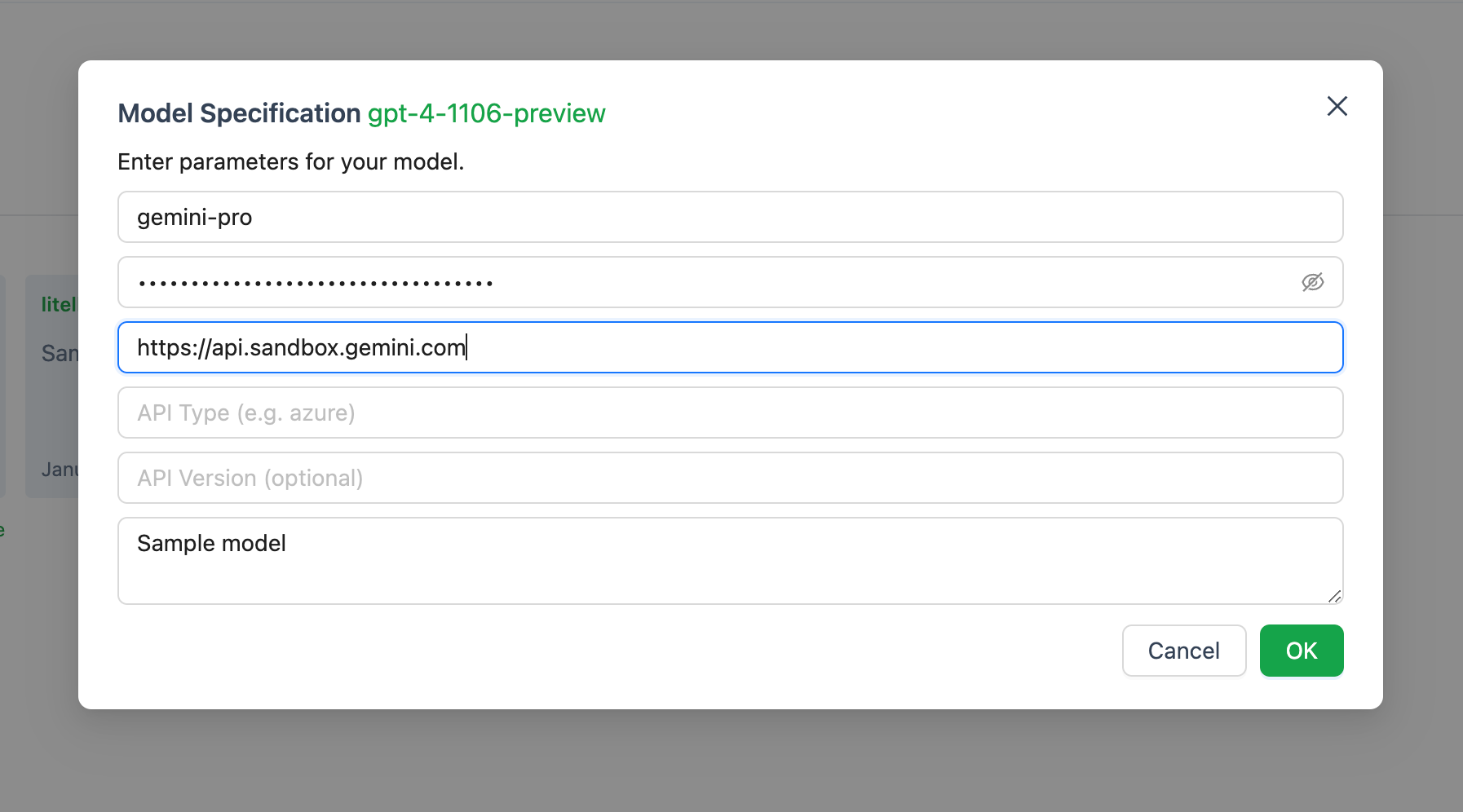
相反,你需要安装另一个软件包 - litellm。不详细介绍,litellm是一种将Gemini转换为OpenAI兼容的API端点的方法。否则,你无法通过将API密钥复制粘贴到Autogen中来进行Gemini API调用。
要安装它,请在终端中输入以下命令:
pip install 'litellm[proxy]'
要启动服务器,请输入以下命令:
litellm --model gemini/gemini-pro
如果一切顺利,你应该能够看到一个地址,类似于这样:
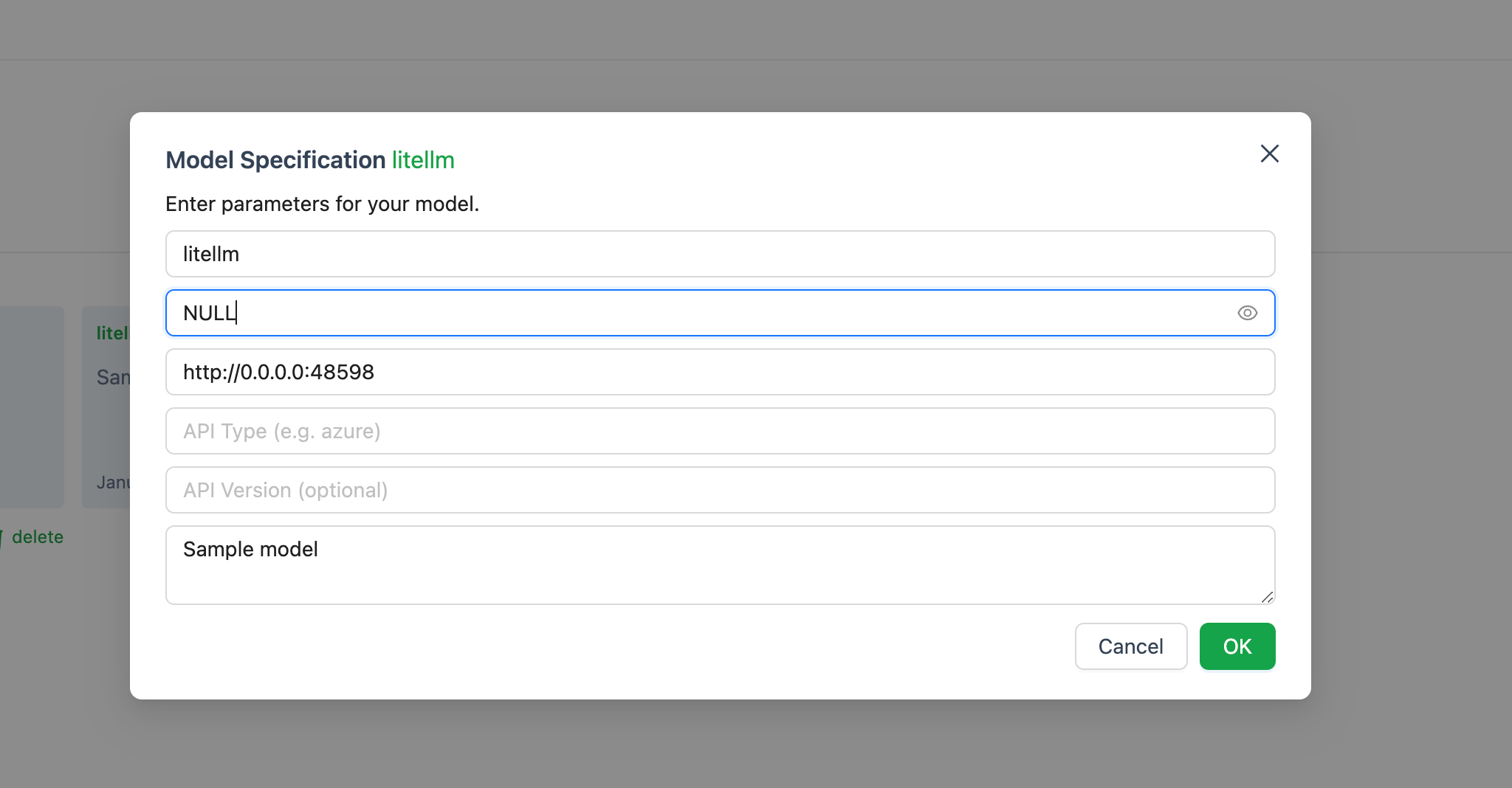
http://0.0.0.0:48598
地址可能对你来说有些不同,但没关系。将其复制并粘贴为基本URL。在API密钥区域,输入NULL。如果不这样做,可能会出错。
其余的流程与OpenAI的教程相同。
3.OOS本地模型
下载、运行和与本地模型交互的最佳最简单的方法是通过LM Studio。你应该选择适合你系统的正确安装包,下载并安装它。
完成后,你应该选择一个要下载和运行的本地模型。
现在,这实际上是一个棘手的部分。
正如你可能在我的crewai文章中所读到的,让本地模型实际上遵循你的指令并以代理方式行动比你想象的要困难得多。具有超过13B参数的较大模型将具有更好的推理能力,如果你能运行它们,就不要浪费时间在这些较小的模型上(而且,你很幸运)。
为什么本地模型会遇到困难?
除了认知能力有限之外,大多数本地模型没有针对函数调用进行微调。这是什么意思呢?
“函数调用”意味着模型可以与某些外部功能或工具进行交互以执行特定任务。这不仅仅是根据其训练生成文本。
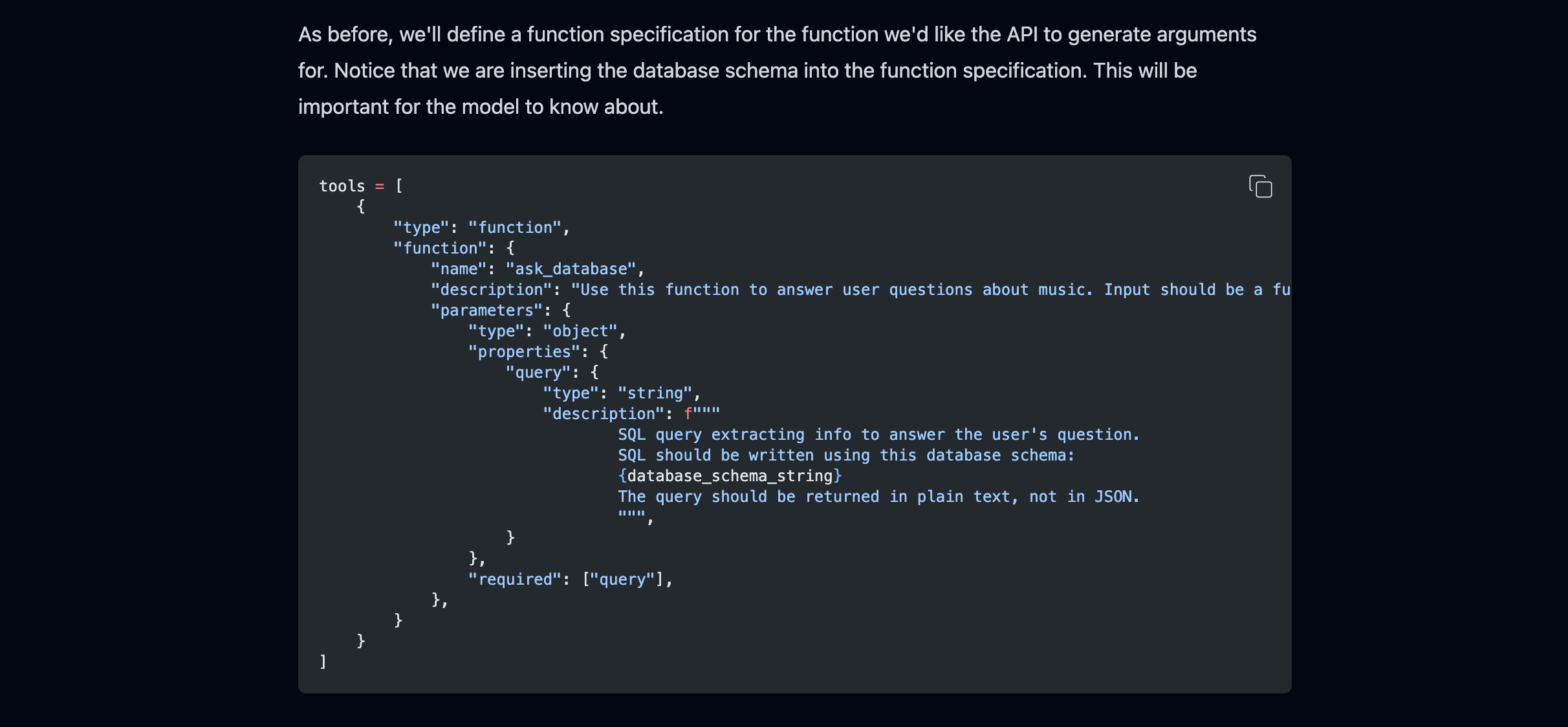
例如,ChatGPT不仅可以聊天。如果你要求它创建一个图表、翻译文本或生成图像,它可以调用特定的函数,类似于使用特殊的工具或技能来完成。这些函数就像它在生成文本响应之外拥有的附加能力。
那么有没有一个本地模型可以进行函数调用呢?
一些模型对包含函数调用示例的数据集进行了微调,比如这个数据集。
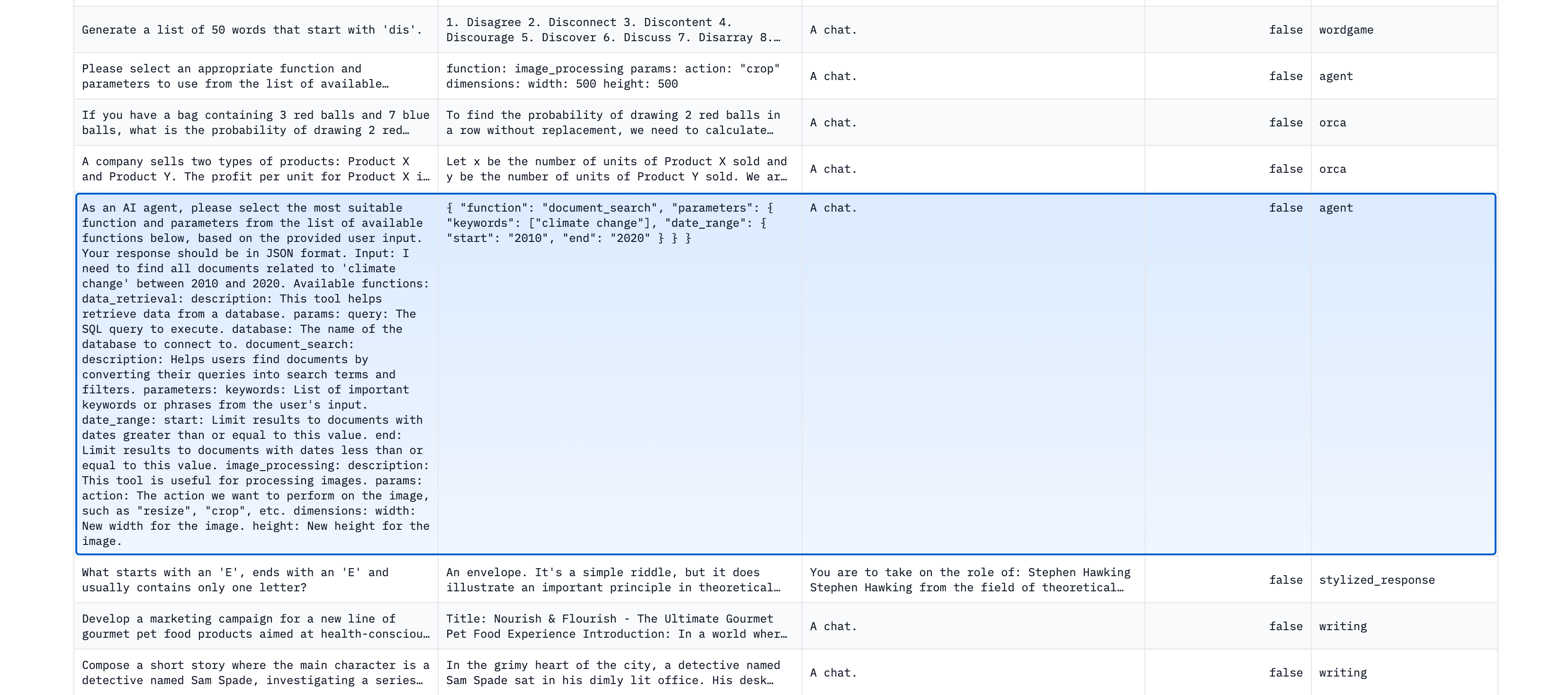
对这个数据集进行了微调的模型是theBloke的airoboros-mistral,所以你可能想要查看一下。它有70亿个参数,这意味着你可以在大多数消费级笔记本上运行它。这是一个成功使用外部工具的模型,尽管不是始终如此。
另一个针对函数调用进行微调的模型是这个微调的Llama 2。
找到并下载特定模型后,转到本地服务器选项卡(左侧的第三个选项卡,在聊天气泡下方)。你应该看到一个窗口,看起来像这样:
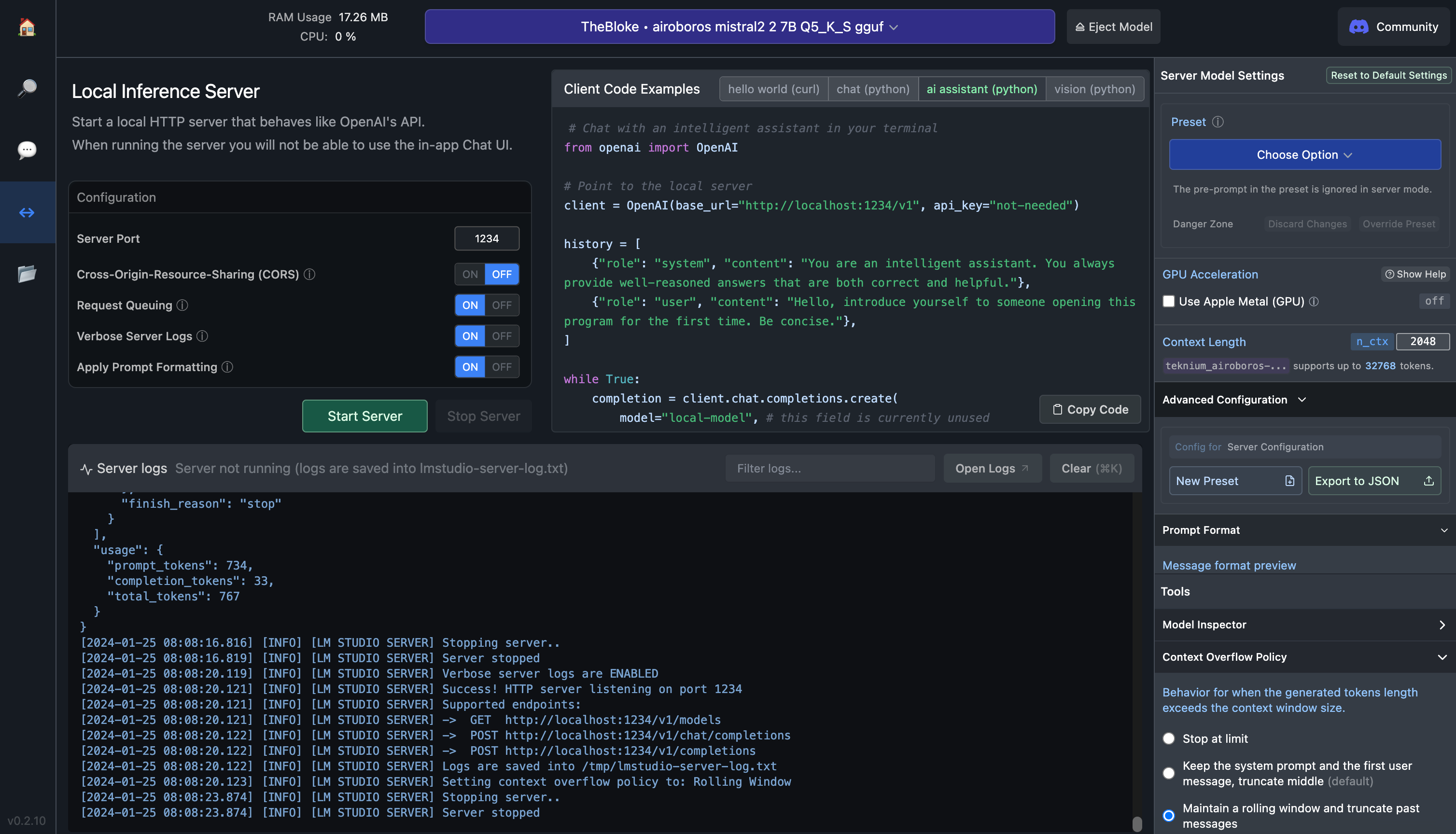
服务器端口对你来说可能会有些不同,但重要的是它不是与你用来运行autogen的服务器相同的服务器。如果服务器端口已经选中,请点击启动服务器按钮。此外,复制base_url值,如你在我的截图中看到的,它是在这一行中出现的值:client = OpenAI(base_url="http://localhost:1234/v1", api_key="not-needed").
再次转到AutoGen的模型选项卡,并添加一个新模型。LM Studio的服务器应该仍在运行。粘贴基本URL,并将API密钥写为NULL。
现在你可以与本地模型代理进行对话了!
可以在此链接上找到能够进行函数调用的本地模型的完整列表。
结论
Autogen是一个非常强大的框架,可以让你构建代理并使它们相互交互。但是,这些代理(如果它们由足够智能的模型驱动)还可以自己创建技能。从某种意义上说,它们具有_自我改进的能力_,你可以利用这些能力使它们更加高效。
你可以仔细制定提示,并让代理编写、分析和改进一些你可以保存为脚本的代码。我让代理编写了两个技能,一个是获取价格,另一个是分析趋势,它们都非常有效。