在过去的6个月里,我一直在使用GPT和其他AI即服务提供商构建LLM驱动的应用程序。在这个过程中,我制作了一系列插图,以帮助可视化和解释一些一般性的架构概念。
下面是第一批,希望以后能添加更多。
目录
- 基本提示
- 动态提示
- 提示链
- 无幻觉的问答(RAG)
- 向量数据库
- 聊天提示
- 聊天对话
- 压缩长讨论
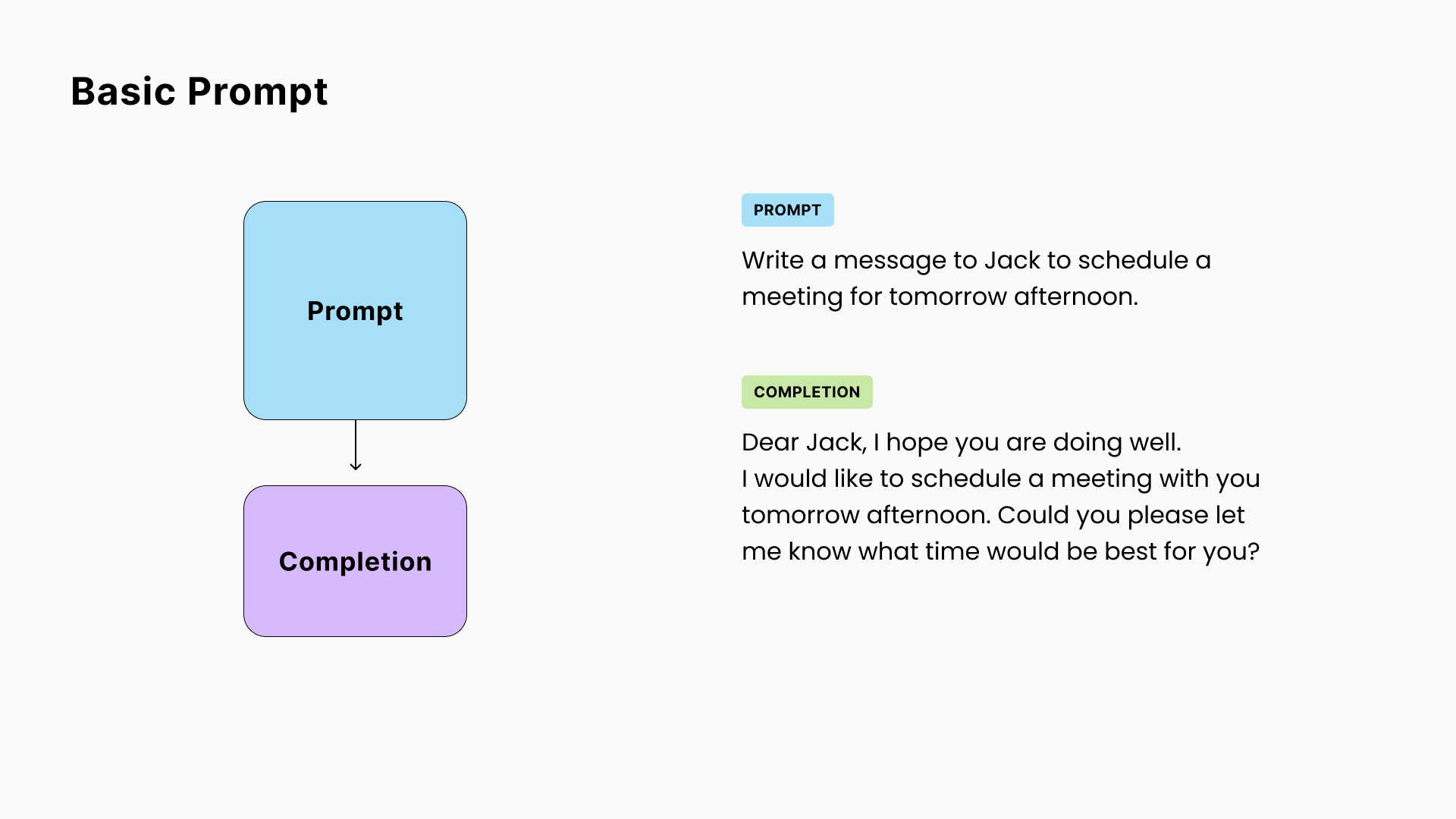
1. 基本提示
最基本的LLM概念:
- 你向模型发送一段文本(称为“提示”),
- 它返回另一段文本(通常称为“完成”)。
需要记住的一点是,从根本上讲,LLM只是在尝试计算上最有可能的下一个单词来完成你的提示。因此称为“完成”。这是理解和利用这些模型的行为的关键。
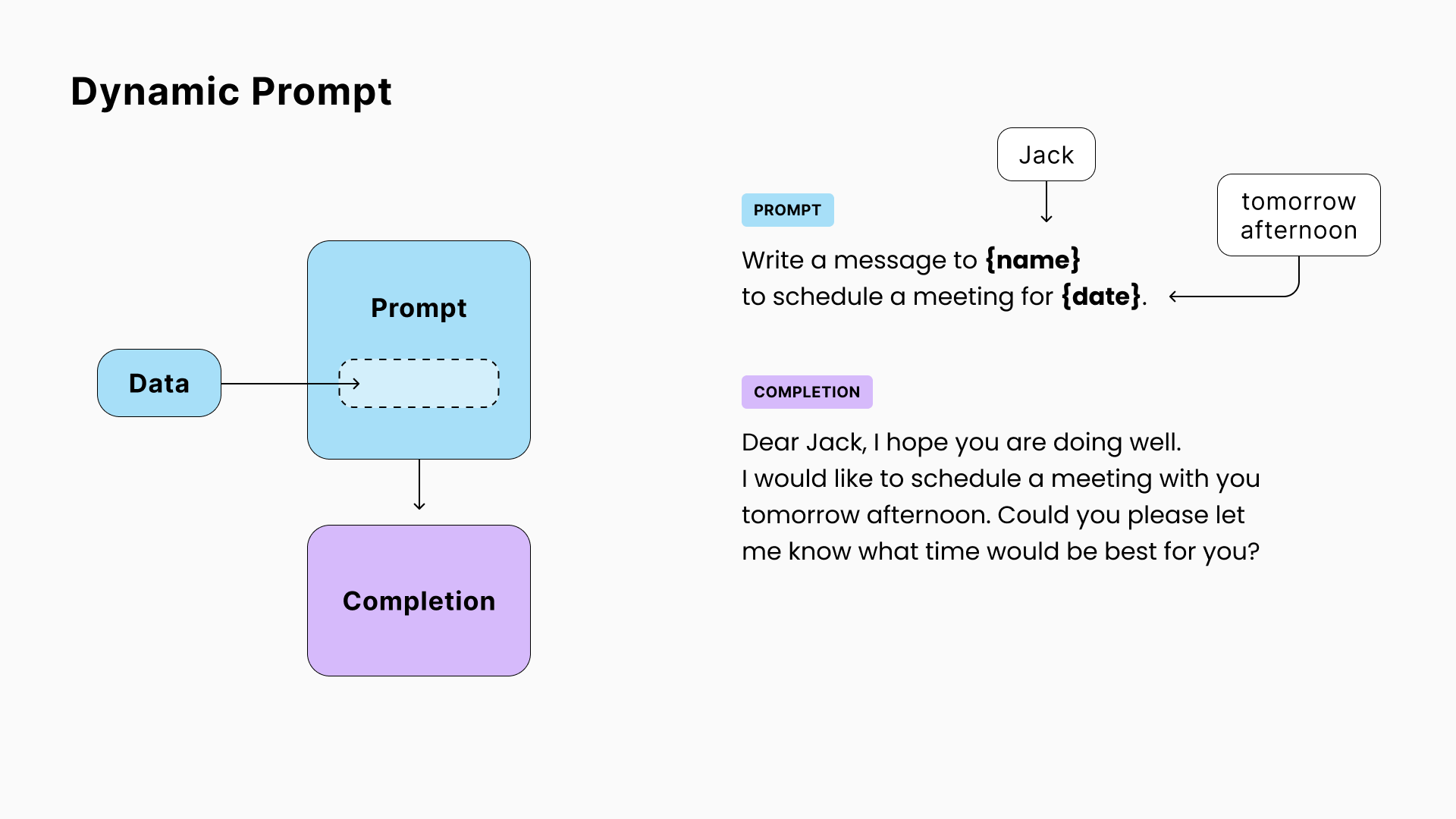
2. 动态提示
LLM应用程序中的一个常见做法是创建一个“提示模板”,然后在将最终提示发送给LLM之前,动态替换其中的部分内容。
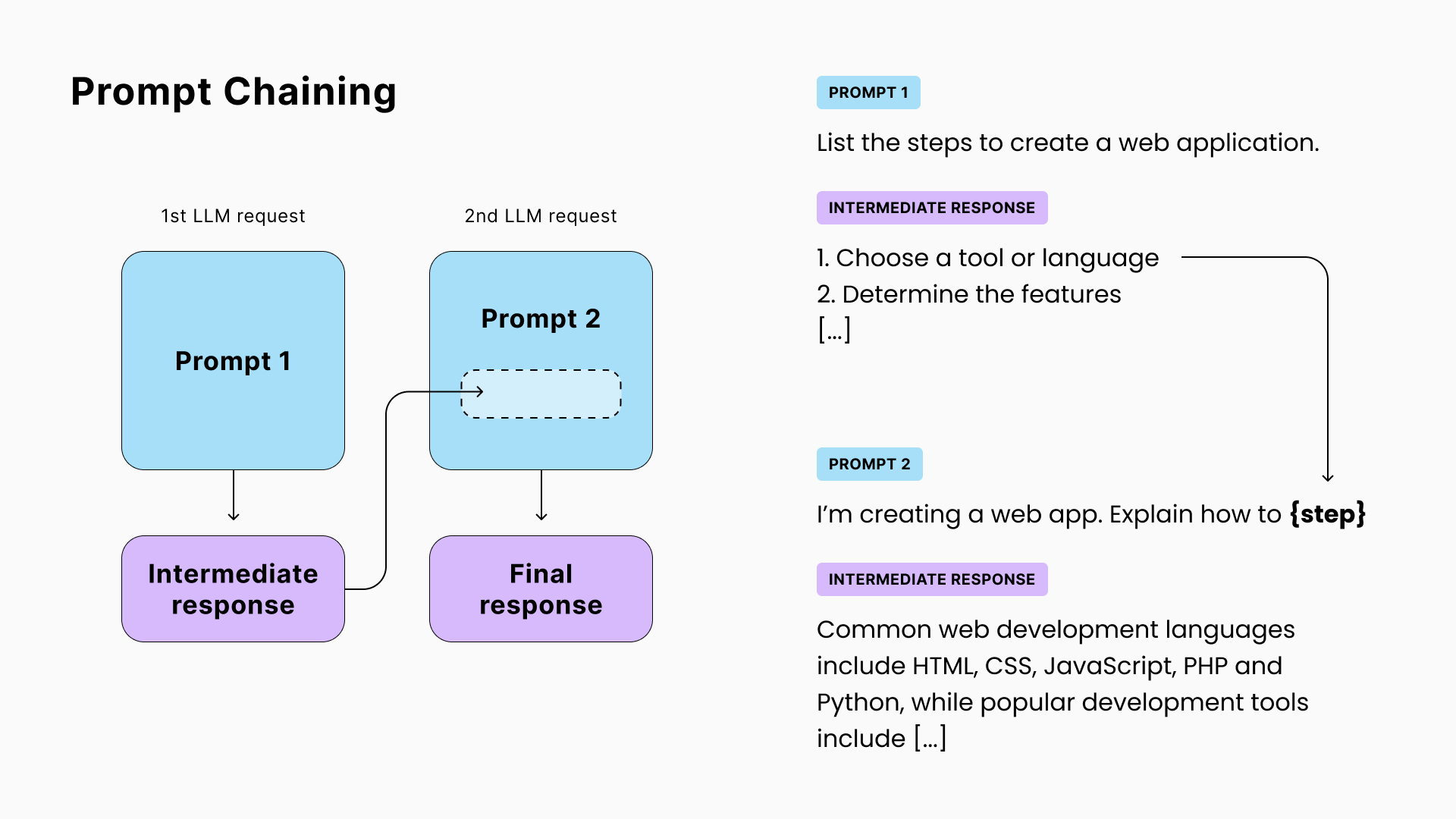
3. 提示链
在某些情况下,单个LLM调用可能不足够。可能是因为任务太复杂,或者完整的响应无法适应上下文窗口(模型每个请求可读和写的最大标记/单词数)。
这时候可以使用提示链:将第一次调用的响应合并到下一次调用的提示中。
4. 无幻觉的问答(RAG)
由于LLM是凭直觉回答问题的,它们有时会给出错误答案,称为“幻觉”。这对于与事实相关的用例(例如客户支持)是一个问题。
然而,尽管LLM在事实方面表现不佳,但在数据提取和改写方面表现出色。缓解幻觉的解决方案是向模型提供多个资源,并要求它通过这些资源找到答案或以“我不知道”回应。
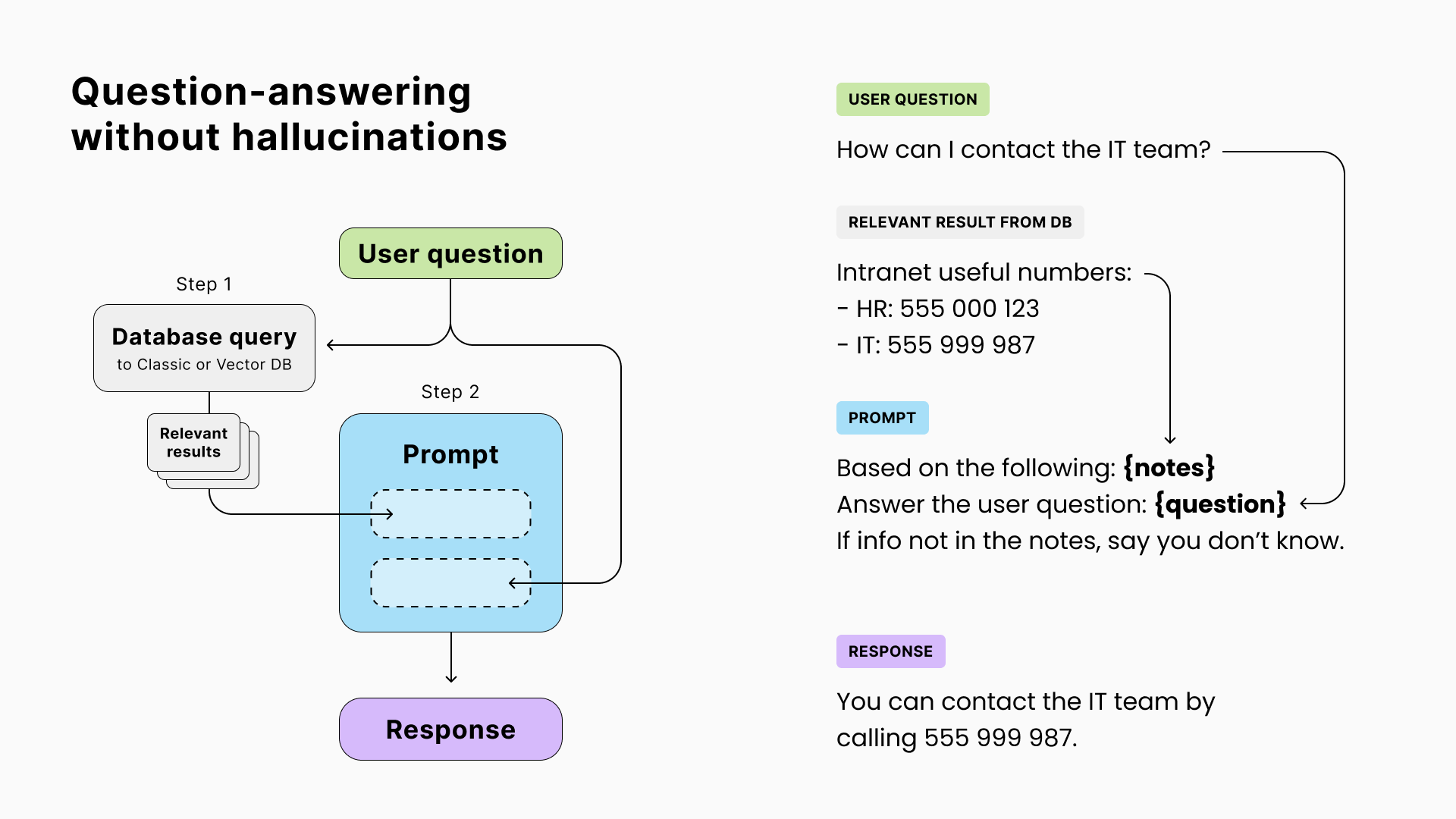
检索资源以增强提示和改善输出的技术被称为RAG(检索增强生成)。
5. 向量数据库
使用传统数据库和逐字匹配来检索与上述用例相关的资源可能很具有挑战性。同一个词在不同的上下文中可能有不同的含义。
在向量数据库中,项目(单词、句子或完整文档)通过表示它们的含义的一系列数字进行索引。
这些数字是多维空间中的坐标(通常具有1500个以上的维度)。其中一些维度可以捕捉“自然←→合成”、“正面←→负面”、“多彩←→平淡”或“圆←→尖”的概念。
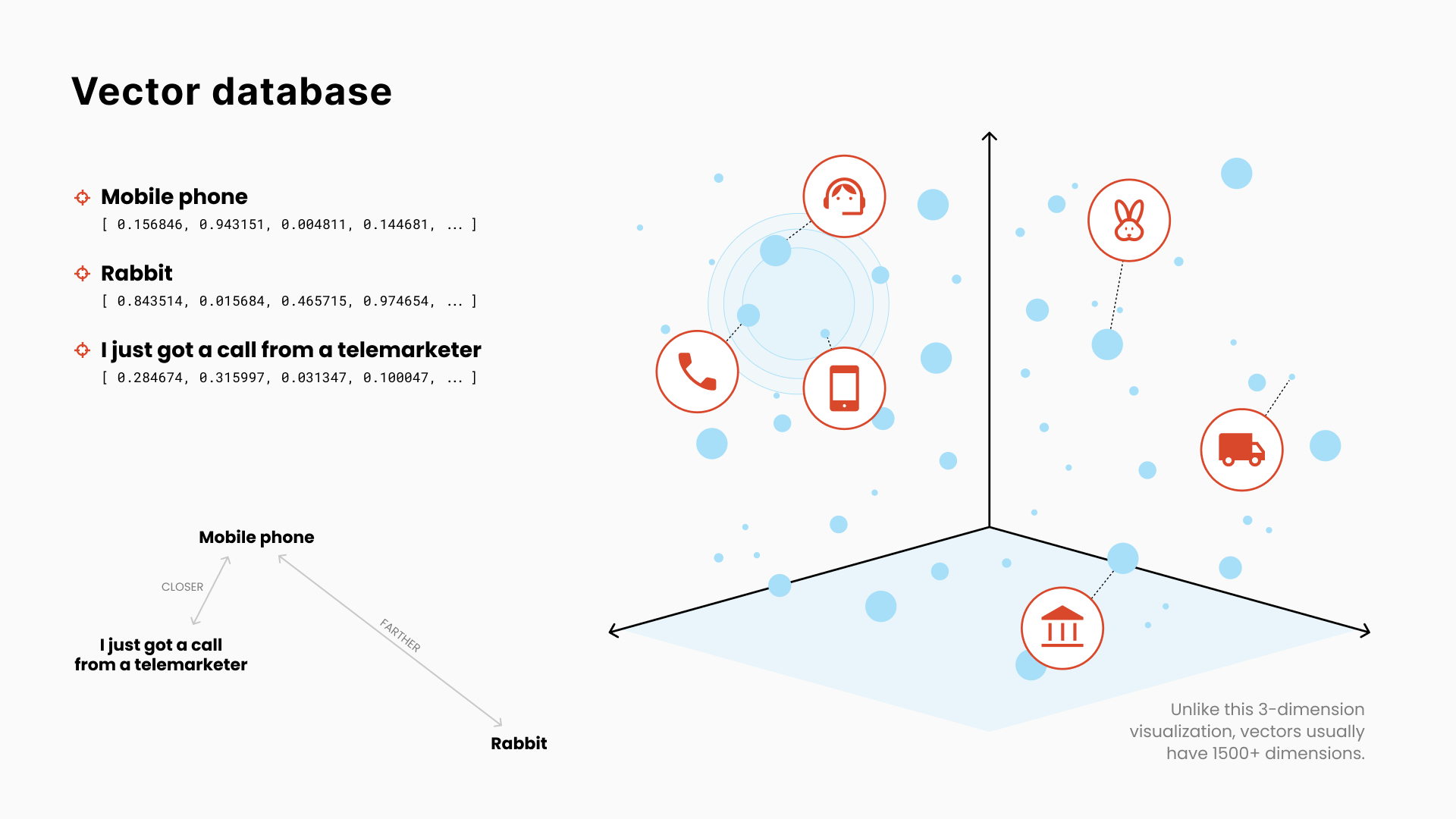
然后,使用几何学,可以计算两个项目间的含义距离,并基于我们的输入找到最接近的匹配。
6. 聊天提示
由OpenAI引入的流行的_GPT-3.5-turbo_模型采用了稍微不同的格式来表示讨论的聊天提示,其中完成将是序列中的下一条信息。
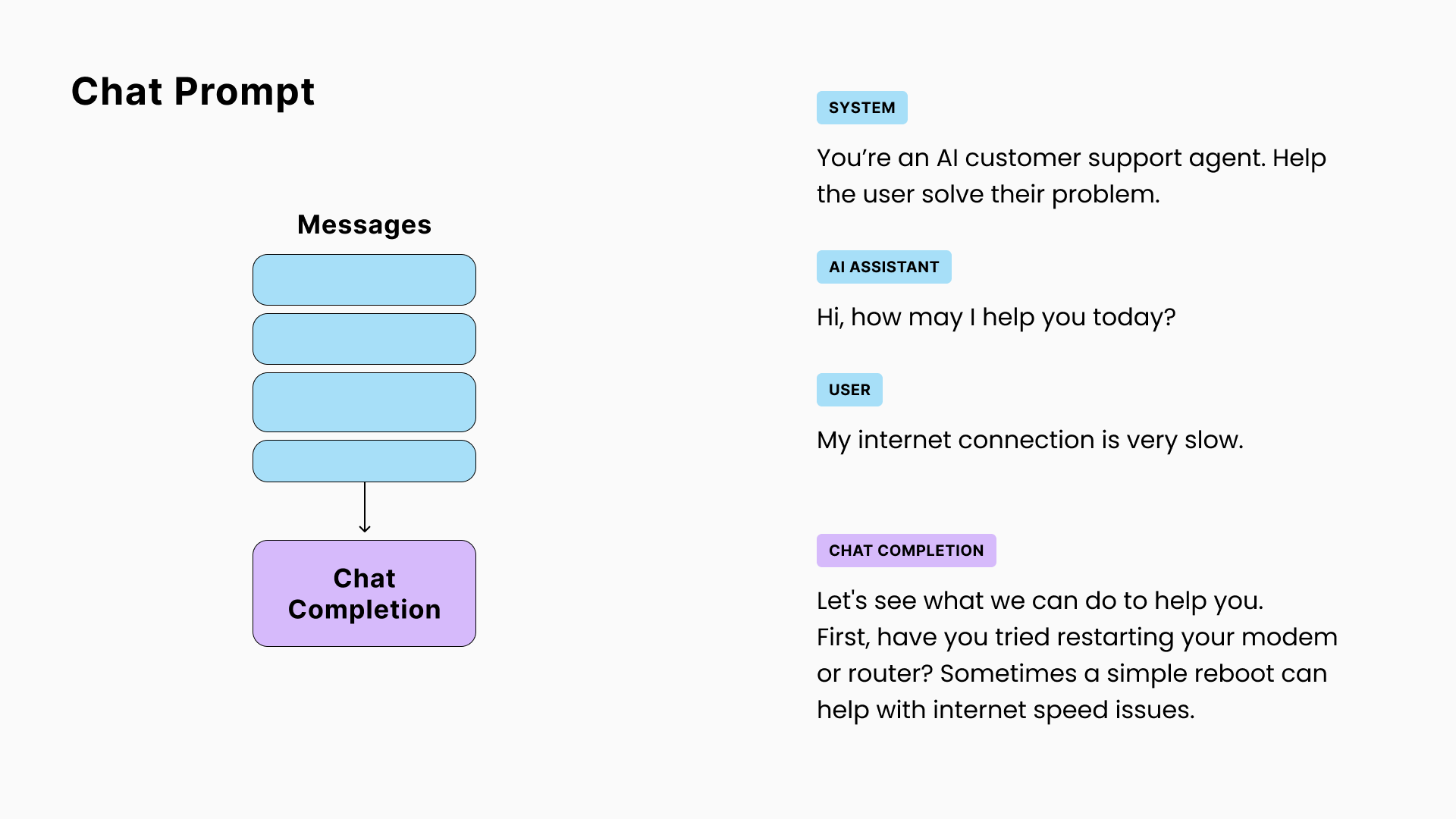
☝ 需要注意的是,虽然GPT的聊天API期望一个角色/消息序列并且被微调(优化)以适应该特定结构,聊天提示等同于以下格式的文本提示:
SYSTEM: 你是一个AI客服代理...
AI: 你好,有什么我可以帮忙的吗?
USER: 我的互联网连接很慢
AI:
☝ 此外,由于OpenAI的聊天模型性能更好且更便宜,我们经常使用聊天模型来处理不涉及讨论的任务。您可以将指令放在第一个“系统”消息中,并在第一个AI消息中获取响应。
对于下面的所有示例,您可以互换地使用聊天提示和格式化为聊天文本提示。
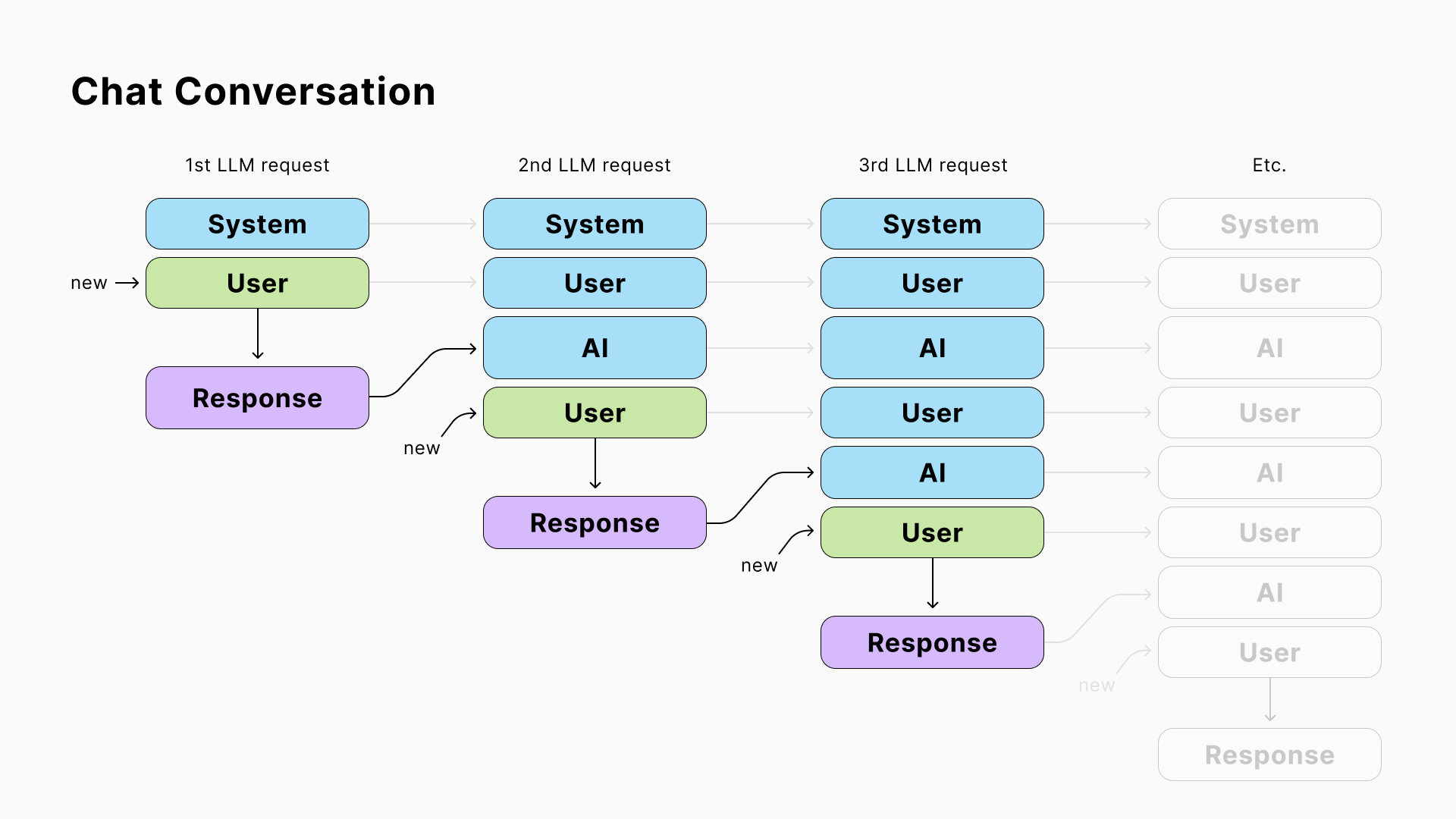
7. 聊天对话
LLM是无状态的,这意味着它们不会存储来自先前调用的数据,并将每个请求视为独立的。然而,当你与一个AI聊天时,它需要知道在你最后一个问题之前说了什么。
为了解决这个问题,您可以在您的应用程序中存储聊天历史记录,并在每个请求中包含它。
8. 压缩长讨论
LLM在单个请求中可以读取和写入的标记(≈ 单词)数量有限,称为“上下文窗口”。
例如,如果一个窗口大小为4096个标记的模型接收到一个3900个标记的提示,那么它的完成将被限制为196个标记。
为了避免达到这个限制并减少API成本(因为提供商按照输入/输出标记收费),解决方案是使用中间提示来总结较旧的消息。
🧐 因为这个总结需要您进行第二次LLM请求,所以在经常做和不做之间有个权衡的余地。
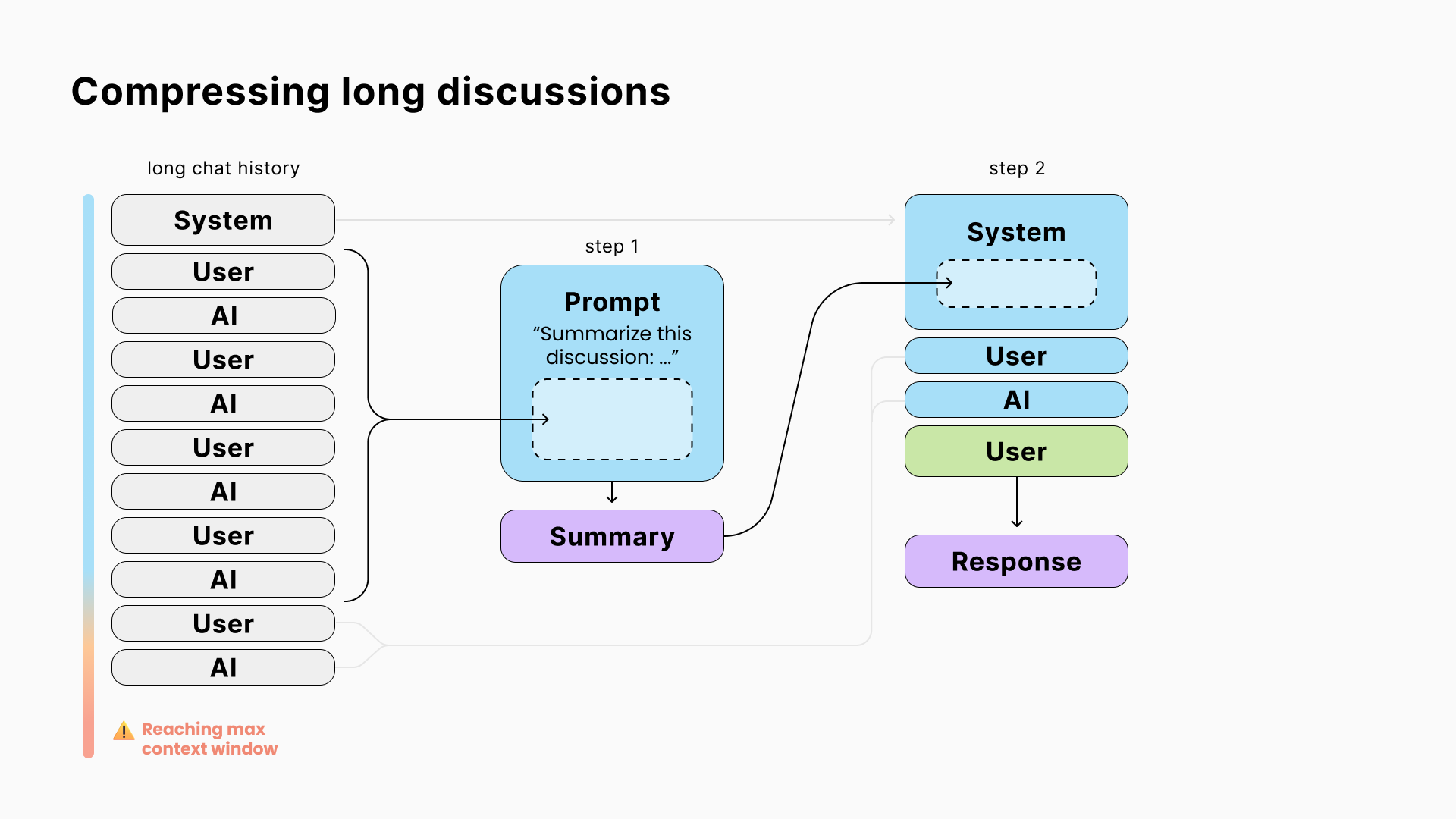
☝ 还要知道,更大的上下文窗口很少是解决办法。具有更大上下文窗口的模型更昂贵,更大的请求更慢,并且太多的上下文可能适得其反。
您可以阅读构建LLM动力产品的第2部分,探索如何为AI提供可以与之交互的工具。