探讨定义,并构建一个 AI 代理团队,用于完善您的简历和求职信。

在 2024 年,代理 AI 是 AI 社区中最热门的话题之一,这是有充分理由的。基础模型在推理和规划方面变得越来越复杂。有了这些能力,我们可以利用大语言模型来将给定任务分解为较小的部分,逐步执行它们,并反思它们的结果,从而创建AI 代理。
如果您对 AI 充满热情,或者喜欢玩语言模型,或者从事机器学习工作,那么如果您想跟上最新的 AI 成就,就有必要全面了解 AI 代理以及它们在实践中的表现。
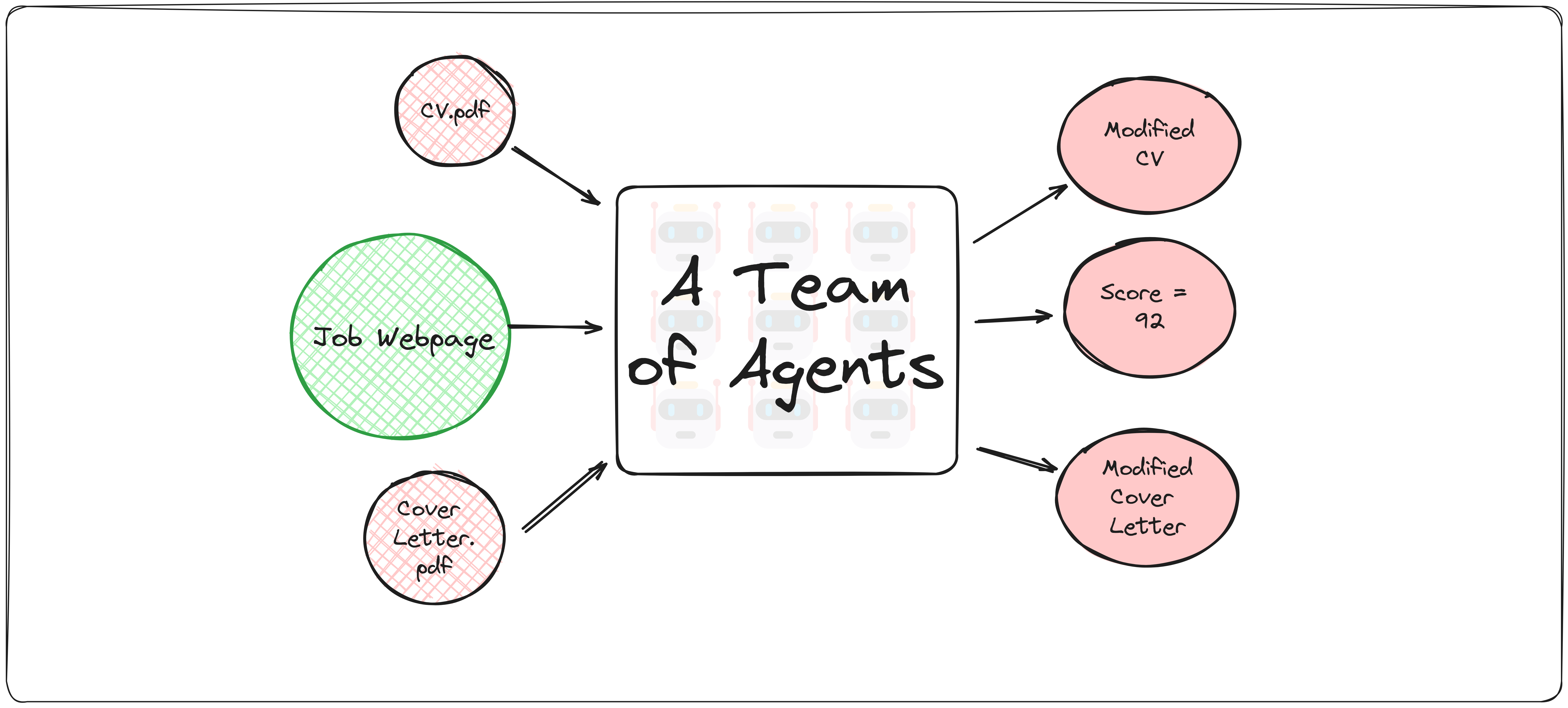
如果您像我一样正在找工作,您会知道为每个申请的工作写求职信或调整简历以突出工作要求是一个繁琐的步骤。对于我的 AI 代理实现,我将开发一个 AI 代理团队,他们合作完成以下任务:
-
提取工作描述中的关键信息
-
修改您的简历和求职信以符合工作要求
-
从招聘人员的角度评估最终结果,并给出一个从 0 到 100 的评分
在本文中,我们将介绍协作 AI 代理是什么,代理与大语言模型的区别是什么,并通过一个实际实现来展示创建 AI 代理可能比您想象的要简单得多。
简化的 AI 代理
AI 代理是一个旨在完成一组特定任务的目标导向工具。虽然 AI 语言模型是为特定提示生成响应而创建的,但 AI 代理通过决策和任务执行来解决复杂问题,从而在更广泛的范围内发挥作用。它们根据任务进行推理,并利用其可用工具执行较小的议程以完成任务。
AI 聊天机器人会说话,AI 代理会行动。
无论是在客户服务、金融还是软件开发领域,AI 代理都是为了一件事而生:自动化。希望 AI 代理能帮助个人和组织处理单调的日常事务,以更低的成本解决较不具创造性的议程。
由大语言模型驱动的 AI 代理
尽管 AI 代理与大语言模型有很大不同,大语言模型是我们 AI 代理的大脑。代理需要大语言模型才能智能地做任何事情,推理并规划它们的下一步。这意味着您使用的大语言模型将完全改变代理的行为。这就是为什么 AI 代理话题的兴起是由 Gen-AI 的激增所可能带来的。
注意:今天我们听到的 AI 代理与传统文献和教科书中的含义有些不同。如果您只是搜索 AI 代理,您会发现对它们是什么的定义各不相同,这可能会让人感到困惑。我们今天使用的 AI 代理,也是 AI 社区的热门话题,是我们在本文中讨论的基于大语言模型的代理。
在核心层面,自主 AI 代理受益于三个组件:
-
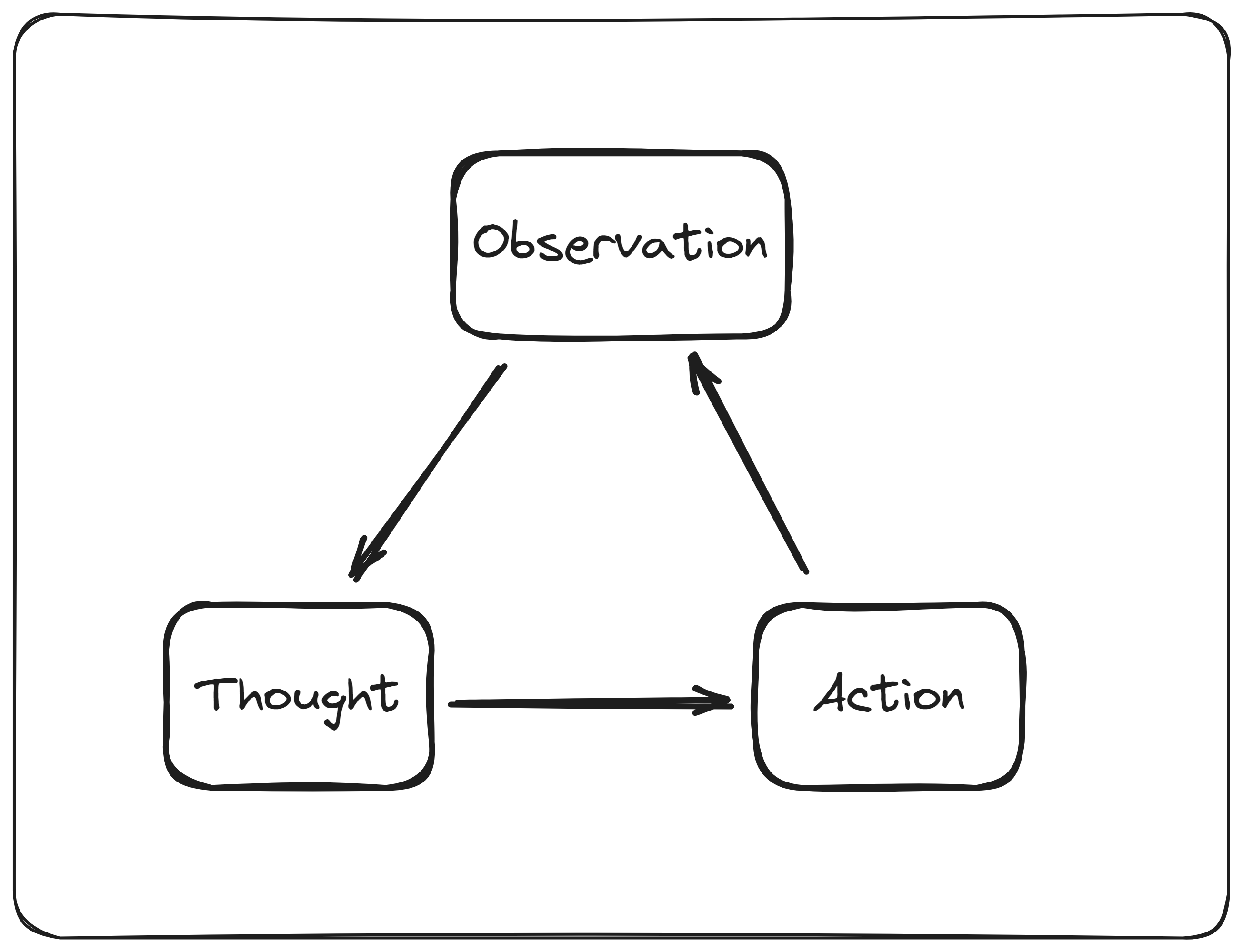
规划:作为代理的核心功能,允许它将目标分解为较小的步骤,并逐个处理它们。他们规划的另一个方面是自我反思他们的行动并从中学习。代理如何进行自我反思在很大程度上取决于实现方式,但可以将代理的自我反思过程想象为图 4 中显示的一般概述。
-
记忆:要从过去的错误中学习,您必须记住它们。记忆是代理存储和稍后检索信息的组件,以完善其行动。
-
工具使用:简单的大语言模型和 AI 代理之间的一个关键区别因素是它们使用工具的能力。使用工具可以简单到调用 API,或使用 Python 函数读取或写入一些文件。
多代理协作
有什么比一个单一代理更好?许多代理!
拥有一个 AI 代理是一回事,但拥有多个 AI 代理彼此协作,分解任务并执行它们是另一回事。
但为什么我们需要多个代理?
当将目标分解为较小部分时,您会得到需要不同技能集的子目标。这就是您需要多个代理的地方。一个代理团队,每个代理都有特定的角色和技能集,确保每个子目标由自己的代理处理。
您甚至可能需要为每个代理提供不同的大语言模型,以便更适合分配给该代理的任务。为编程能力创建的代理可能需要完全不同的大语言模型,而为写文章的代理可能需要完全不同的大语言模型。
代理的特点
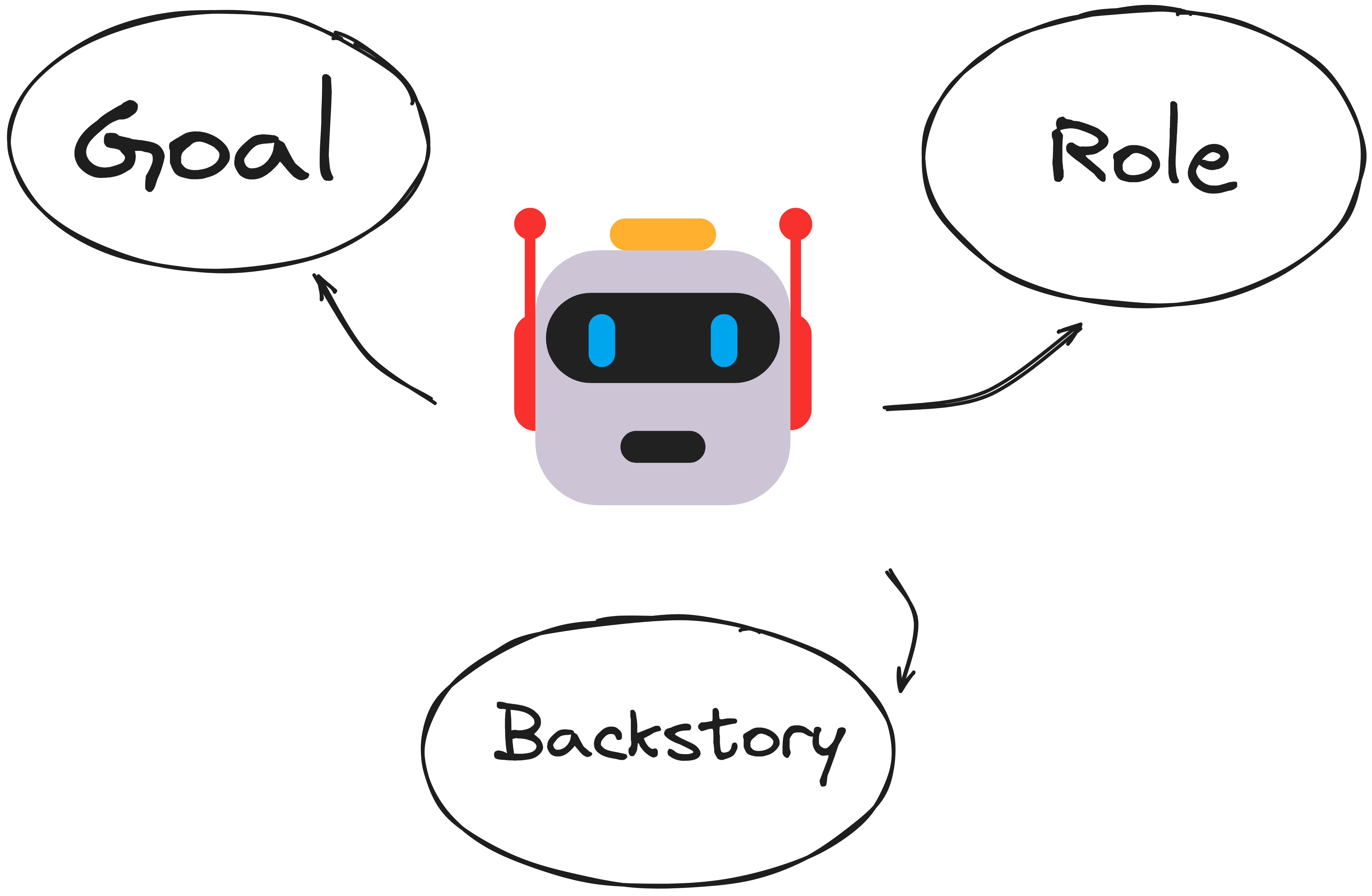
您如何定义代理在很大程度上取决于您使用的实现或库。一般来说,代理可以归结为三个主要元素:
-
目标:代理旨在实现的具体目标。这塑造了它的决策框架。例如,“编写易于理解的面向对象 Python 代码。”
-
角色:代理的功能。它是谁?调试器、数据科学家、销售营销人员等。
-
背景故事:代理的背景。解释了目标、角色以及代理擅长的内容。背景故事的一个示例可能是,“您是一名资深 Python 程序员,专门编写优化的、文档完善的代码及其测试用例。”
多代理所需的条件
多代理的实现细节有一些微妙之处需要考虑。想象一个团队的人们共同努力实现相同的目标,一个餐厅厨房中的一组厨师团队就是一个例子。

您需要一位主厨来领导团队。团队成员需要彼此交流。您需要他们能够将完成的工作发送给其他厨师,以进行食物准备的下一步。这只是许多事情中的一个例子,用于使多个代理共同协作完成共享任务。
通常,对于多个代理,您需要:
-
信息共享:代理需要将其结果传递给彼此,并分享他们的发现。一个代理的完成工作可能是另一个代理开始任务的输入。
-
协作:代理应该能够互相帮助并在需要时委派其工作的部分。在简单情况下,这可能不是必需的,但在复杂流程中,这是非常必要的。
-
管理代理:控制代理之间任务的流动,使它们保持在控制之下。
代码实现:帮助您申请工作的代理
现在让我们创建我们的代理团队。有多个库可以让您开发 AI 代理,例如 LlamaIndex 或 LangChain。我将使用 CrewAI,因为它具有易于使用的工作流程和高度抽象。它是免费使用的,同时在为您的代理提供足够控制的同时,可以避免在简单项目中出现不必要的复杂性。
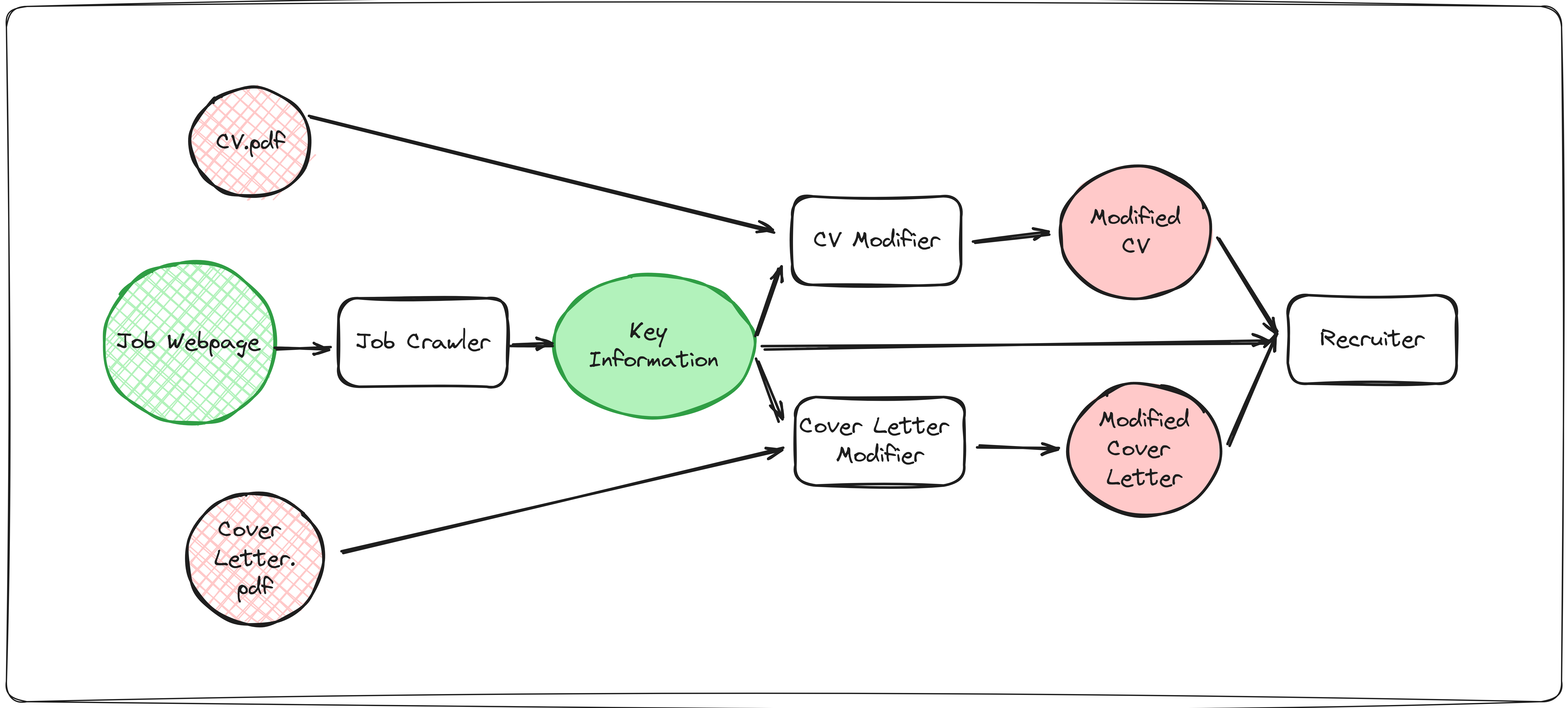
我将创建一个代理团队,帮助我根据给定的工作描述修改我的简历和求职信,评估最终结果,并查看我获得面试机会的可能性有多大。为此,我将创建四个代理:
-
职位爬虫:此代理将接收工作发布的 URL,爬取网页,并提取有关工作要求、资格等的关键信息。
-
简历修改器:根据职位爬虫提供的工作关键信息,此代理将阅读我的简历并进行增强,以更好地符合工作描述。
-
求职信修改器:与简历修改器相同,但是用于我的求职信。
-
招聘人员:充当招聘人员,分析我的修改后的简历和求职信。它将给我反馈,还会给出一个范围为 [0–100] 的评分。
对于大语言模型,我们将使用 gpt-4-turbo。但是,使用 Ollama,您可以在100% 本地和免费运行大语言模型。在本文中,我不会详细介绍,但要了解如何在您的计算机上本地运行 LLama-3、Mistral、Phi-3 等模型,请阅读这篇文章:
接下来,我将加载我的 OPENAI_API_KEY 并初始化我的 model。这个模型是我们代理推理的支柱:
from dotenv import load_dotenv
from crewai import Agent, Task, Crew, Process
from langchain_openai import ChatOpenAI
from langchain.tools import tool
import re
# 从您的 .env 文件加载 OPENAI_API_KEY
load_dotenv()# 代理模型
```python
model = ChatOpenAI(model_name="gpt-4-turbo", temperature=0.8)
我们还需要定义两个代理需要使用的工具。工具是代理用来执行特定任务的工具。为代理编写自定义工具就像编写一个简单的 Python 函数一样简单。你只需要用 langchain 的工具装饰器将其包装起来。这个项目中我们需要的工具是一个用于通过给定的 URL 获取页面内容的工具,以及一个用于阅读 CV.pdf 和 Cover Letter.pdf 内容的工具。
from langchain_community.document_loaders import PyMuPDFLoader
import requests
# 用于加载和阅读本地 PDF 的工具
@tool
def fetch_pdf_content(pdf_path: str):
"""
读取本地 PDF 并返回内容
"""
loader = PyMuPDFLoader(pdf_path)
data = loader.load()[0]
return data.page_content
# 用于加载网页的工具
@tool
def get_webpage_contents(url: str):
"""
读取给定 URL 的网页并返回页面内容
"""
try:
response = requests.get(url)
response.raise_for_status() # 检查 HTTP 错误
return response.text
except requests.exceptions.RequestException as e:
return str(e)
有了我的模型和所需的工具,接下来是定义我的代理。CrewAI 中的代理需要三个主要属性,角色、目标 和 背景故事。对于每个代理,我们将指定一组所需的工具。代理还可以选择将其任务的一部分委托给其他代理,但由于这个项目并不那么复杂,我们为所有代理将 allow_delegation 设置为 False。
job_crawler = Agent(
role='职位描述爬虫',
goal='提取相关的职位描述、要求和资格',
backstory='擅长解析 HTML 并从中提取重要信息',
verbose=True,
tools=[get_webpage_contents],
allow_delegation=False,
llm=model
)
cv_modifier = Agent(
role='简历撰写员',
goal='撰写一份出色的简历,增加获得面试机会的可能性',
backstory='擅长撰写最受招聘团队和人力资源部门欢迎的简历',
verbose=True,
tools=[fetch_pdf_content],
allow_delegation=False,
llm=model
)
cover_letter_modifier = Agent(
role='求职信撰写员',
goal='撰写一封引人入胜的求职信,提高获得面试机会的可能性',
backstory='擅长撰写最受招聘团队和人力资源部门欢迎的求职信',
verbose=True,
tools=[fetch_pdf_content],
allow_delegation=False,
llm=model
)
recruiter = Agent(
role='招聘经理',
goal='分析候选人与职位描述的匹配程度,根据其简历和求职信',
backstory='经验丰富的招聘经理,专门给求职者提供反馈',
verbose=True,
allow_delegation=False,
llm=model
)
现在我们需要列出我们的任务。任务是您希望特定代理执行的具体工作。我将为每个代理分配一个任务。我将解释我的任务描述,以及我希望任务输出的具体内容。
def extract_job_information(page_url):
return Task(
description=f"给定此 URL: {page_url},提取职位描述和与职位相关的信息",
agent=job_crawler,
expected_output="职位描述的关键要点、要求和所需资格",
)
def cv_modifying(cv_path):
return Task(
description=f"阅读此本地路径的简历: {cv_path},然后修改技能的关键点和顺序,以突出工作所需的内容。\
不要添加任何额外技能或新信息,保持诚实。",
agent=cv_modifier,
expected_output="经过修改的简历版本,量身定制以适应职位描述",
)
def cover_letter_modifying(cv_path):
return Task(
description=f"阅读此本地路径的求职信: {cv_path},\
然后根据 '职位描述爬虫' 代理提供的职位描述,\
修改以使其针对提供的职位描述。填写空白括号中的公司名称。\
不要添加任何额外技能或新信息,保持诚实。",
agent=cover_letter_modifier,
expected_output="经过修改的求职信版本,量身定制以适应职位描述",
)
evaluate = Task(
description=f"提供修改后的简历和求职信,以及职位描述的关键要点,\
根据候选人与此职位的匹配程度,给出一个 0-100 的评分",
agent=recruiter,
expected_output="得分范围为 [0-100]",
)
请注意,其中一些任务取决于另一个任务的输出。例如,我需要修改后的简历和求职信才能对它们进行评估。而且,除非“职位描述爬虫”代理成功地从网页中提取了职位信息,否则我也无法修改我的简历和求职信。
然而,您必须意识到,最终您正在从外部网站内容中提取关键职位信息。在个人或商业用途中使用此类工具时,最好遵守网站的权利/版权。
CrewAI 通过确保代理彼此共享所需信息来自动处理这一点。
现在剩下的就是创建我的代理团队,并让他们开始工作!
# 用户输入
cover_letter_path = r'求职信.pdf'
cv_path = r'简历.pdf'
job_url = [www.job.com]
extract_job_information_task = extract_job_information(job_url)
cv_modifying_task = cv_modifying(cv_path)
cover_letter_modifying_task = cover_letter_modifying(cover_letter_path)
# 创建团队
crew = Crew(
agents=[job_crawler, cv_modifier, cover_letter_modifier, recruiter],
tasks=[
extract_job_information_task,
cv_modifying_task,
cover_letter_modifying_task,
evaluate
],
verbose=2
)
# 让我们开始!
result = crew.kickoff()
这段代码块接受用户关于所需文件路径和网页的输入。然后我将使用之前定义的代理和任务创建我的团队,并让他们开始工作!
结果是我们的代理所有思考过程和结果的长输出。为了简短起见,我将展示“求职信修改员”代理的思考过程示例:
> 进入新的 CrewAgentExecutor 链...
我需要阅读提供的 PDF 文件中的求职信内容,以了解其结构和内容。这将有助于根据职位描述对其进行修改。
操作:fetch_pdf_content
操作输入:{"pdf_path": "求职信.pdf"}
尊敬的招聘经理,
[为简洁起见,省略原始求职信]
谨致问候,
思考:
现在我有原始求职信的内容。我需要将这封求职信量身定制,以特别针对华为 AI4Sec 研究团队的职位空缺。我将调整内容以突出与提供的职位描述相关的经验和技能。
最终答案:
尊敬的招聘经理,
[为简洁起见,省略修改后的求职信]
谨致问候,
您可以看到代理与自身的原因,确定需要做什么,并使用手头的工具执行。
在我们的每个代理完成任务后,我们可以看到他们的输出以及他们的表现。

您可以看到,求职信修改员代理成功地修改了我的求职信以适应职位描述,甚至添加了一些在职位描述中强调的要点。然而,简历修改员代理的输出有些令人失望,需要对其代理和任务定义进行一些调整。
招聘经理代理还审查了我的修改后的简历和求职信,并为候选人的匹配程度打了92/100的分数:
根据对 Hesam Sheikh Hassani 的简历和求职信与 [故意排除] AI 研究团队 AI 研究员职位的关键要点的详细审查,我将候选人评分为 92 分。Hesam 在人工智能领域拥有坚实的学术和专业背景,特别是在机器学习和深度学习方面,这与 [故意排除] AI 研究团队的要求很好地契合。
他对大型语言模型(LLMs)的经验以及通过社交媒体和文章展示的有效传达复杂 AI 概念的能力尤为令人印象深刻,这与该职位直接相关。他在 Git、Linux、Python 和高级机器学习算法等对该职位至关重要的工具上的技术熟练度进一步增强了他的候选资格。
Hesam 之前的角色和项目,如 PFK 的农业分选机和他在 AI-on-Demand 平台上的工作,展示了他的领导能力和管理和执行 AI 项目的能力,这对 [故意排除] 的职位至关重要。他表达了对为 [故意排除] 的研究项目做出贡献和学习的渴望,以及他与 [故意排除] 的持续改进、AI 诚信和包容性核心价值观的契合,使他在文化和专业上都与该职位高度契合。
他的立即可用性和愿意搬迁也增加了他适合该职位的可能性,确保了对团队的顺利过渡和立即贡献。因此,鉴于 Hesam Sheikh Hassani 与 [故意排除] AI 研究员职位的技术和文化方面的强烈契合,我强烈推荐他担任此职位,评分为 92 分。
AI 代理修改简历和求职信的示例用例仅用于强调我们如何利用 AI 自动化重复任务的范围,并作为一个教育性示例。如果您想在实践中使用这类工具,最好牢记一些限制:
-
AI 生成的简历或求职信可能会被招聘人员视为警示信号。招聘经理可能会使用 AI 检测工具来淘汰这类候选人的申请。
-
诸如 ChatGPT 这样的 AI 工具仍然会陷入简历用语的陷阱。AI 在简历中的一些写作风格和词语选择很容易被察觉。诸如“深入挖掘”或“带头”之类的词语可能会暴露出生成式 AI 的文本。这种写作风格可能会使您的简历听起来不真实,缺乏共鸣。
-
AI 聊天机器人和大语言模型遭受幻觉的困扰。在这个例子中,幻觉可能意味着在求职信和简历中加入您实际上并不具备但受到职位描述启发的经验和技能。请仔细检查您的简历/求职信是否存在任何不切实际的修改。
牢牢掌握大语言模型的潜力使公司和专家处于更加优越的位置。其中一个引人入胜的能力就是 AI 代理。在本文中,我们介绍了什么是 AI 代理,它与大语言模型的区别,以及如何通过几行代码来实现它们以自动化我们的重复任务。