需要 300 字?500 字?1000 字?甚至 5000 字?这个一次性提示将在您试图满足 ChatGPT 字数限制时拯救您理智。
想让 ChatGPT 遵循特定的字数限制吗?我来帮你。这里有一个提示,可以让 ChatGPT 达到这些精确的字数目标 - 不多,也不少 🎯 在这篇文章中,我将向您介绍我的创新方法,鼓励 ChatGPT 准确满足字数限制。
它还大大增加了 ChatGPT 回复的长度!
我不是轻易说这番话的,但这周我在提示工程方面做了一些非常突破性的工作。如果您阅读我的文章,您将学会:
-
通过编程方式强制 ChatGPT 达到从 100 到 5000 的字数限制
-
使用分段和记忆设置 来防止字数混乱
-
实现 Python 代码 来让 ChatGPT 保持在正确的轨道上
-
摆脱无休止的循环,既不少也不多

ChatGPT 在满足字数目标方面的问题
“吉姆”,我经常被问到,“为什么 AI 不能遵守字数限制?” 在关于 AI 限制的常见抱怨中,这个问题与“为什么 AI 会撒谎?”以及“为什么 ChatGPT 一直说‘深入’这个词?”齐名。
AI 无法跟踪字数的原因有几个,但首先我们必须管理对 AI 思维方式的期望。它不是“智能”,无论是人工的还是其他的。它是一个语言预测引擎。它不是计算器(尽管它可以给出最可能的 听起来正确 的答案,这通常是正确的 - 例如我们听到 1+1=2 这个短语足够多次,以至于我们可以口头重复而不进行任何心算)。
ChatGPT 处理的是单词和字符串,而不是数学。它 可以 通过 Python 代码运行一个方程 - 它的神经网络算法显然是基于数学的,以便预测下一个单词 - 但 LLM 不 懂 数学。
对于 ChatGPT,数字只是另一个字符串,与字母或标点符号没有什么不同。您不会使用电子词典来解决数独难题。当然,它知道所有的数字,但它不知道如何将它们组合在一起。LLM 没有数字或数量的概念。

为什么您的字数限制与 AI 不兼容
此外,ChatGPT 不像您或我处理单词(甚至不像我们熟悉的在打字时计数的 Word 文档)。相反,AI 将每个单词分解为更小的单位:Token。Token 可以是单词的部分,也可以是整个单词。因此,如果您提示“写 200 个单词”,AI 只能通过 Token 处理它 - 这并不总是与完整单词对应的。
如果您要求 ChatGPT写入特定数量的单词,它不会像人类那样考虑这个任务。它不会有意识地计数。没有内部机制来跟踪还需要生成多少单词。它不会坐在那里说,“好的,这是 152 个,我需要达到 200 个。”
此外,ChatGPT 不会验证自己的工作。它不会回头确保自己达到了您的神奇数字,因为该系统旨在提高效率。它希望快速结束事情,就像一个下午 4:59 离开的同事一样。
当快速比准确更重要时呢?
事实上,AI 平台运行成本如此之高,以至于许多服务,如 Apple Intelligence,旨在在提供文本时将简洁性置于准确性之上。因此,您可能已经注意到 AI 倾向于低估您的目标。
字数要求可以让人们大致了解回复需要多简洁或深入(因为 100 字的文章和 1000 字的文章在 写作方式 上有所不同;即所涉及的语言类型和预期的详细程度有所不同),但 AI 更关心的是提供一些有意义的东西,而不是坚持您的名义字数预算。
此外,AI 不会提前计划。它根据概率预测接下来会出现哪些单词,并快速生成它们。当人类写作时,会有一种结构感 - 我们在思考如何控制自己的节奏,需要击中哪些关键点,以及如何在最后整洁地结束。我们可以看到目标,并相应调整我们的节奏。
ChatGPT 不在乎您的字数限制(但我在乎)
考虑到所有这些因素,ChatGPT 为什么不能按照字数写作?它不是计算器。它无法跟踪自己生成了多少单词。它不认为“单词”是整洁的小单位,一旦开始,它就会专注于效率而不是精确度。
具有讽刺意味的是,它试图听起来自然,而不是达到一个它不理解的任意目标。毕竟,它不知道 为什么 那个确切的数字对您很重要。
然而,AI 用户可能出于各种原因需要精确的字数,无论是为了完成大学作业(顽皮的小作弊,但这是另一回事),还是在公司报告中达到字数限制,遵守严格的编辑指南,坚持文章要求,遵守社交媒体上的字符限制,或者遵守辅助功能的替代文本约束。
通过提示技巧聪明地战胜 AI 的满足感
在某些专业环境中,人们会对精确的字数限制着迷 - 无论是为了适应布局还是满足 SEO 的要求。
或者是我个人最喜欢的:智力谜题。作为一个提示工程师,我喜欢让 AI 执行其未设计的任务,比如精确达到字数限制。这就是为什么我想出了我的扭曲的提示技巧!
将 AI 推到极限有一种奇怪的满足感。这就像让自动售货机掉下两份零食而不是一份一样。这是魔术。有时候,我甚至喜欢使用提示黑客技术来对抗一些大品牌:
让 ChatGPT 首先计算单词数
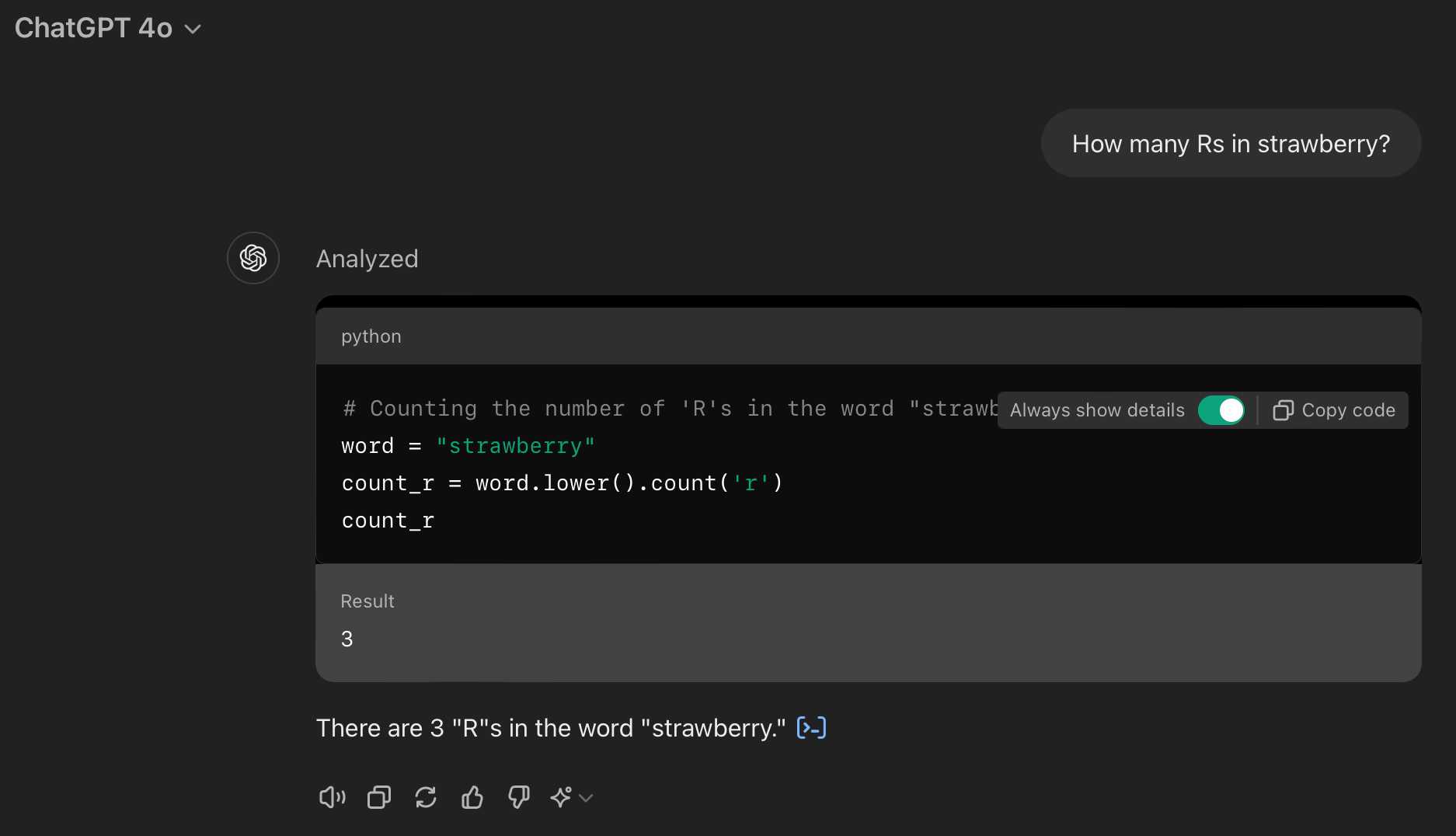
无论如何,在尝试解决“草莓中有多少个 R?”这个问题时(对于新读者的快速回顾:这是一个臭名昭著的请求,让 ChatGPT 陷入困境;它无法计算三个 R),我意识到我同时找到了解决字数限制的解决方案。您看,草莓问题的一部分在于模型如何将单词标记化,另一部分在于“动量”。
我最初解决了草莓难题 ,通过使用“反思”这个词引发了“系统 2 思维”,使 ChatGPT 放慢速度并思考。当它遵循这个请求时,它正确地计算了三个 R。但您可以看到(在响应时间上),该模型通常认为这太直接了,忽略了对更深层思考的请求。因此,我想出了一个更严格的解决方案:植入一个记忆来使用代码解释器计算字母数。
如何通过 ChatGPT 的记忆设置提高计数准确性
记忆让您设置自定义行为和偏好。想让 ChatGPT 停止使用某些单词(我在看你,“深入”),始终以您的语气写作,或了解关于您的详细信息?记忆为 ChatGPT 提供了备忘单,这样您每次聊天时都不必再提示这些事实。
如果您打开了自动记忆功能,它会记住您喜欢的方式以及关于您的某些上下文事实。这就像给 ChatGPT 递上一张便利贴。
记忆不会“训练” ChatGPT,但它确实允许您创建跨对话持久的自定义指令。这些规则成为每次开始聊天时的 初始提示 - 这是在任何互动中引导 AI 行为的隐形讲话。没错:每次您开始新对话时,ChatGPT 都会在任何事情开始之前阅读这些内容。当与 AI 聊天时,我们并不是第一个开口的!
记忆可供 ChatGPT Plus、Team、Enterprise 用户和一些免费用户使用(即将向所有人推出)。只需进入设置,在自定义指令下打开它。现在它会“记住”某些事实,并从您的提示中推断偏好;每当发生这种情况时,您会看到一个小小的“已添加记忆”通知。您可以随时使用临时聊天跳过记忆设置,或者只需在开始聊天时使用 Add nothing to memory for this convo 如果您想 使用 存储的记忆但不 添加 新内容。如果记忆没有自动激活,您还可以通过提示 Add this to memory 来植入一个记忆。
解决“草莓中的 2 个 R”问题
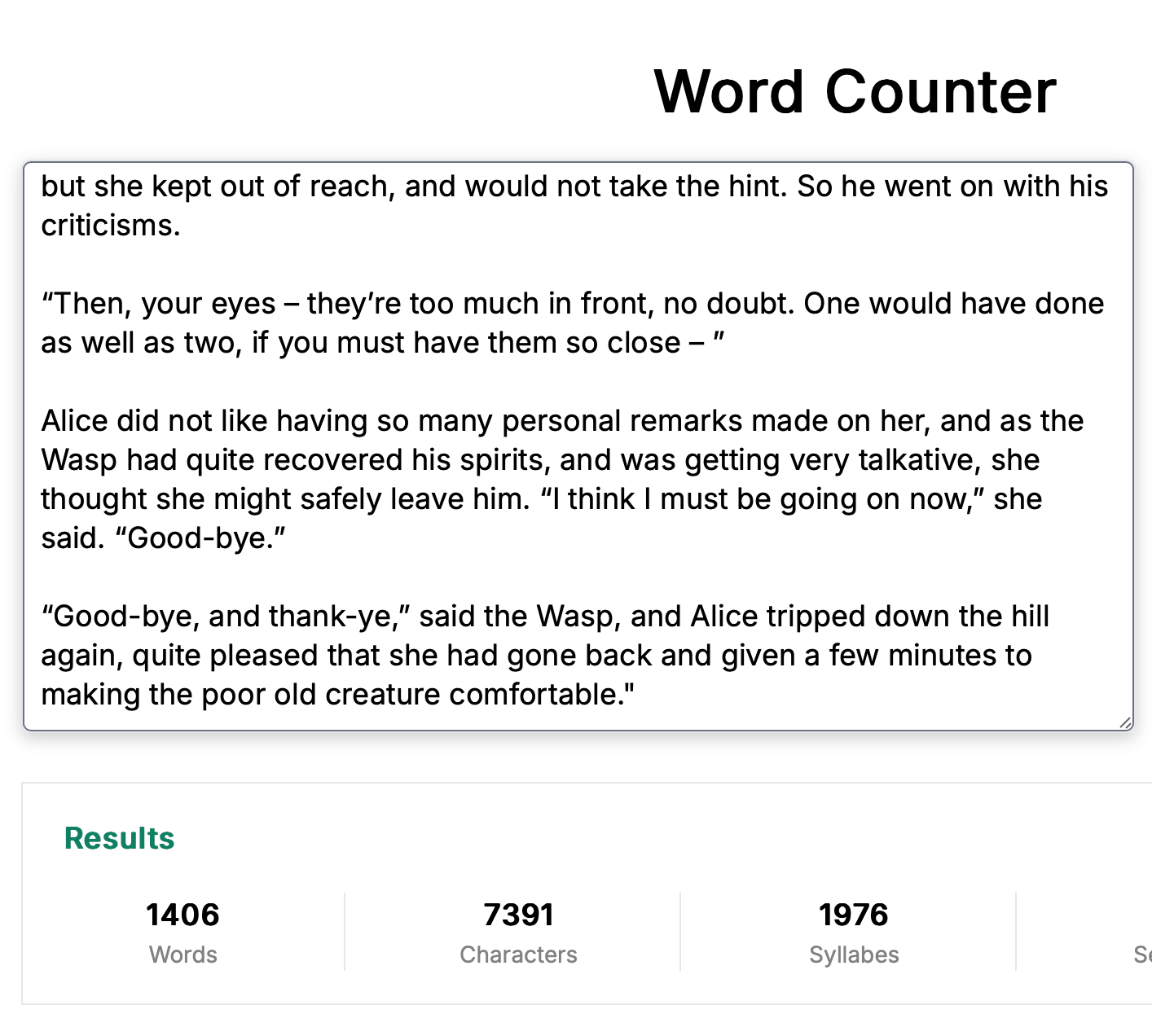
我为草莓问题添加的记忆如下:

它运行得很完美;虽然我喜欢我的“反思”提示,并且仍然觉得它对于需要更严格精确度的任务(如深度推理任务)提供了更出色 - 也更长的 - 回复,但用于字数计数的记忆黑客对于需要严格精度的任务更为可靠:
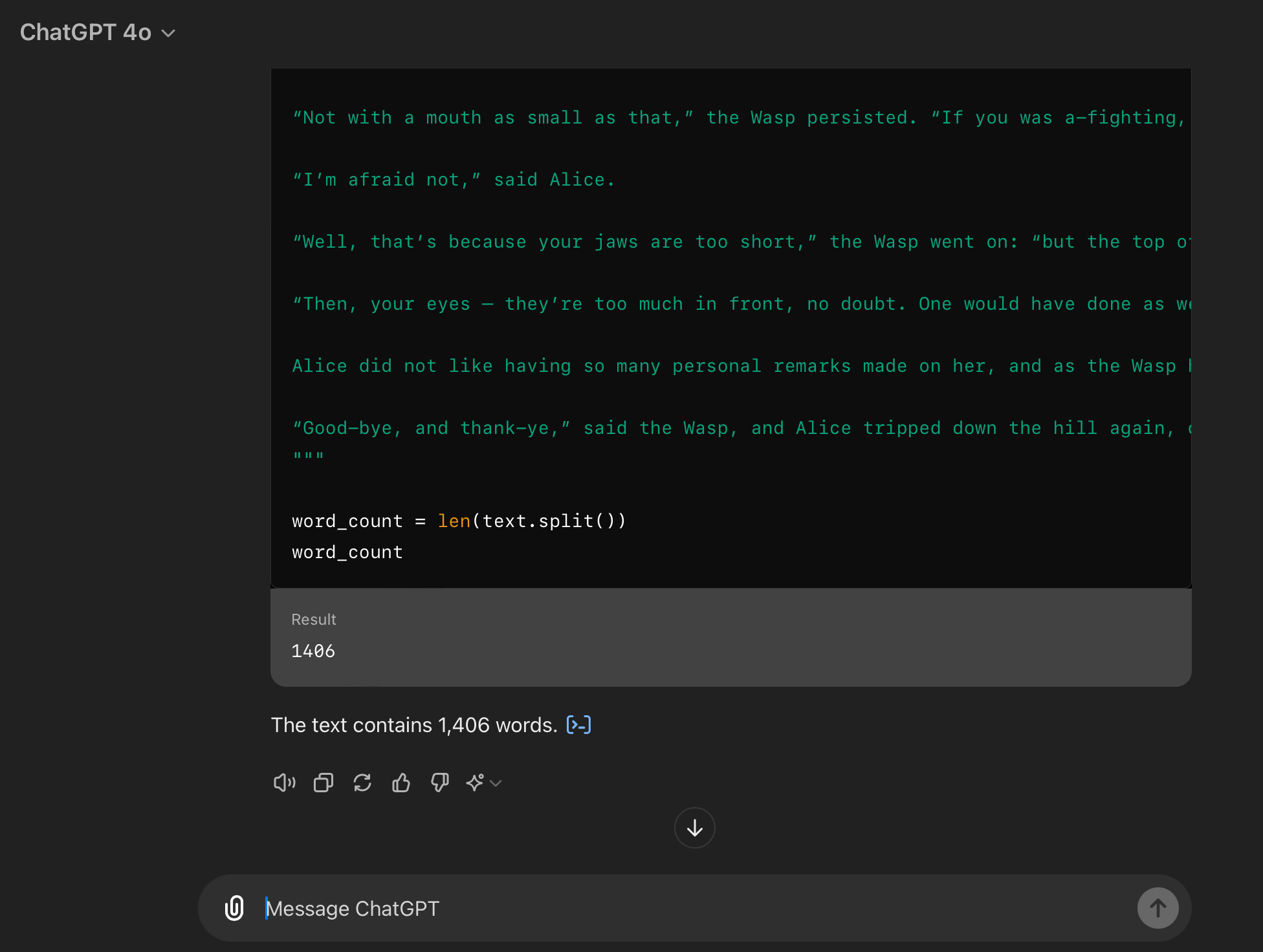
像专业人士一样躲避标记化,感谢代码块但你知道吗?我发现这也绕过了标记化问题,使 ChatGPT 能够通过将段落放入代码块中来准确计算单词数。你会记得:让 ChatGPT 遵守单词数的一大挑战是它实际上无法计算单词数,如果被迫,它会编造最终数字。有了我的记忆设置,它将段落和自己的文本输出视为代码片段或原始数据,因此免疫于标记化的烦恼。现在它的工作就像一个在线计数器一样:
在下一步中,你将需要我的记忆,所以这里是它。虽然我总是乐意分享我的知识,但是你们的贡献(以及 Medium 合作伙伴计划)使这个项目得以继续,所以如果这个提示对你有所帮助并且你有能力支付,考虑请用一杯咖啡表示感谢!
添加到记忆:[你的名字] 希望我始终使用精确的方法,比如编程式单词计数,以确保回复的准确性。
这_显著地_提高了 ChatGPT 达到单词数的能力!
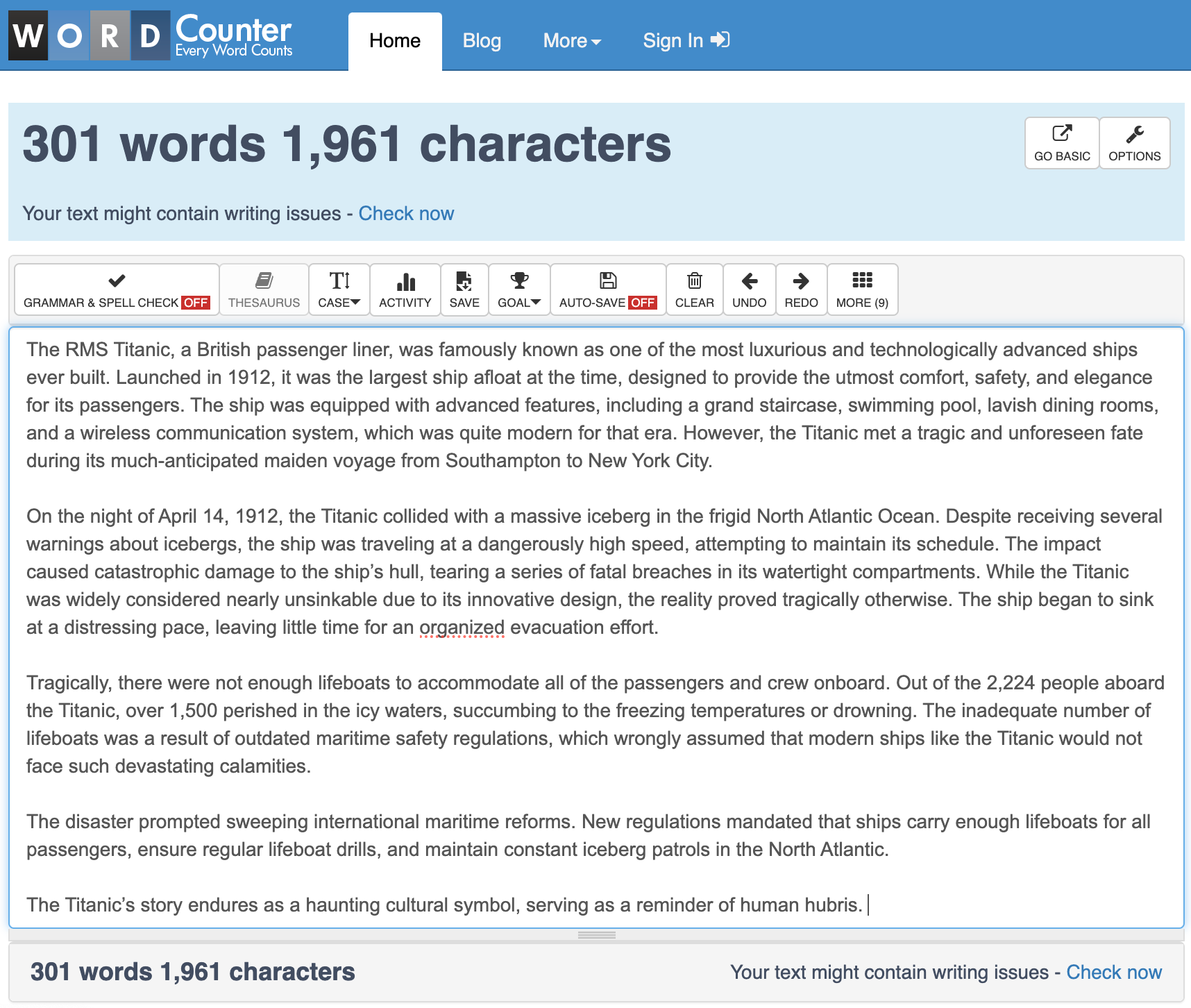
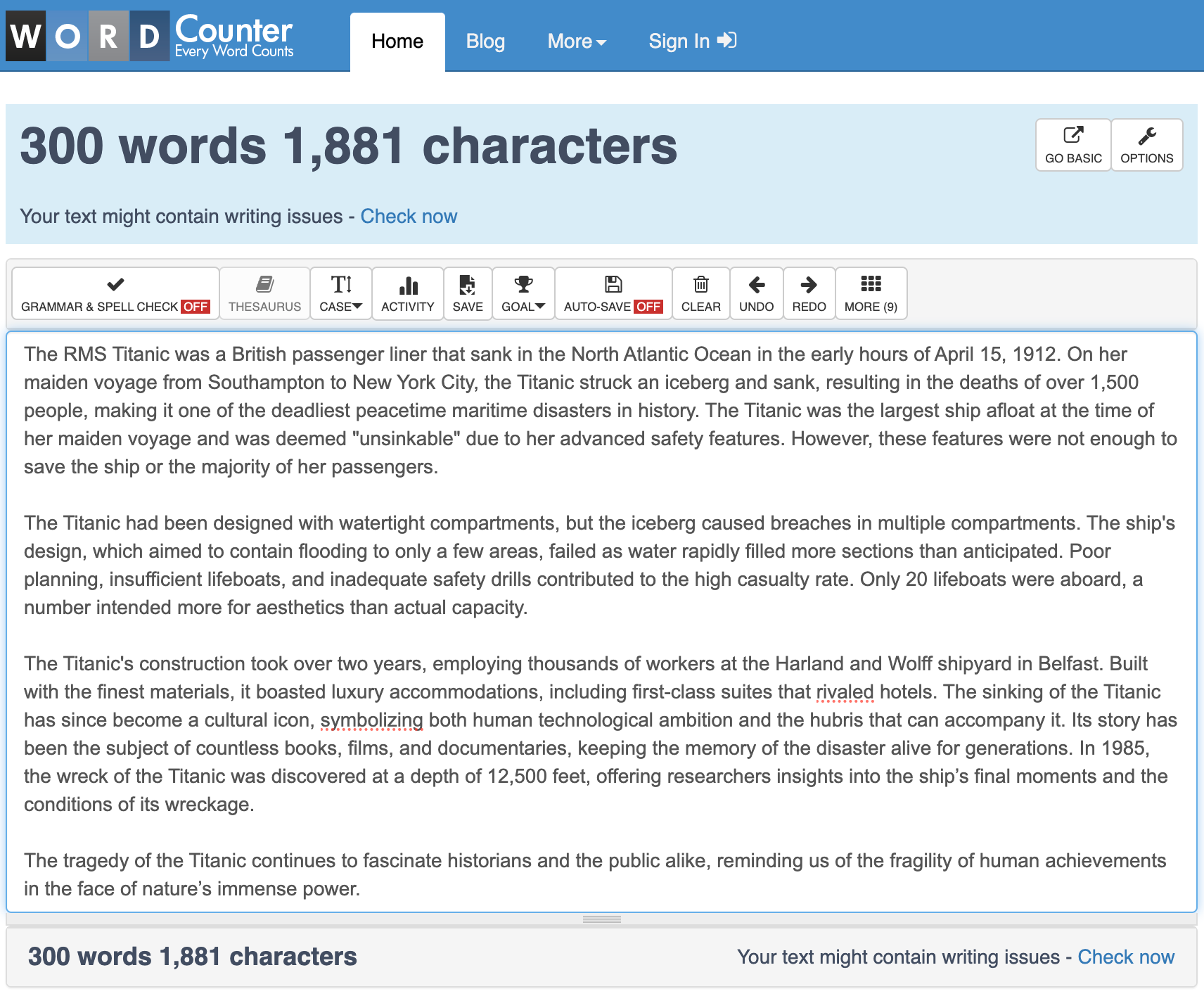
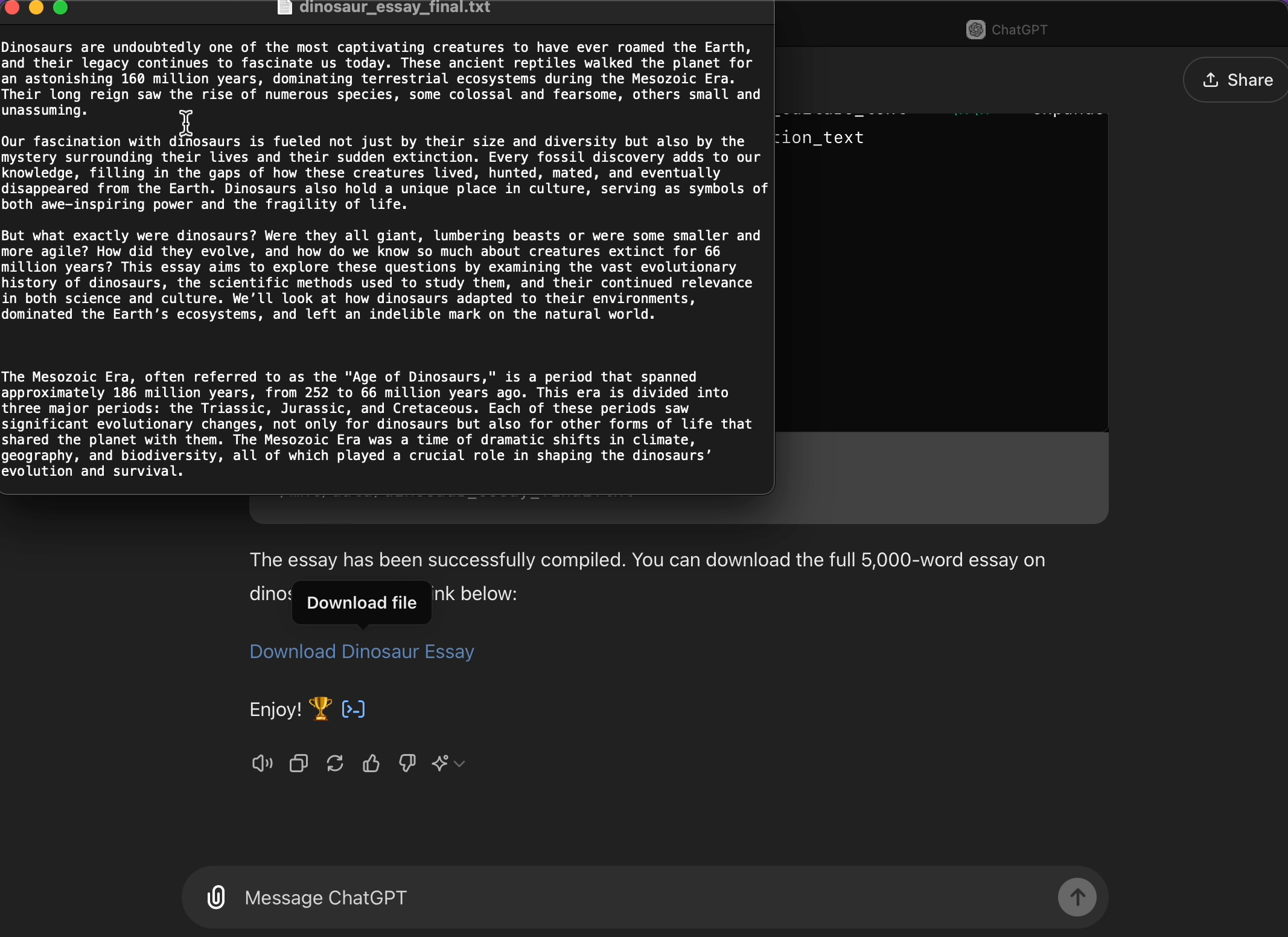
第一次测试:ChatGPT 对抗 300 字的《泰坦尼克号》文章
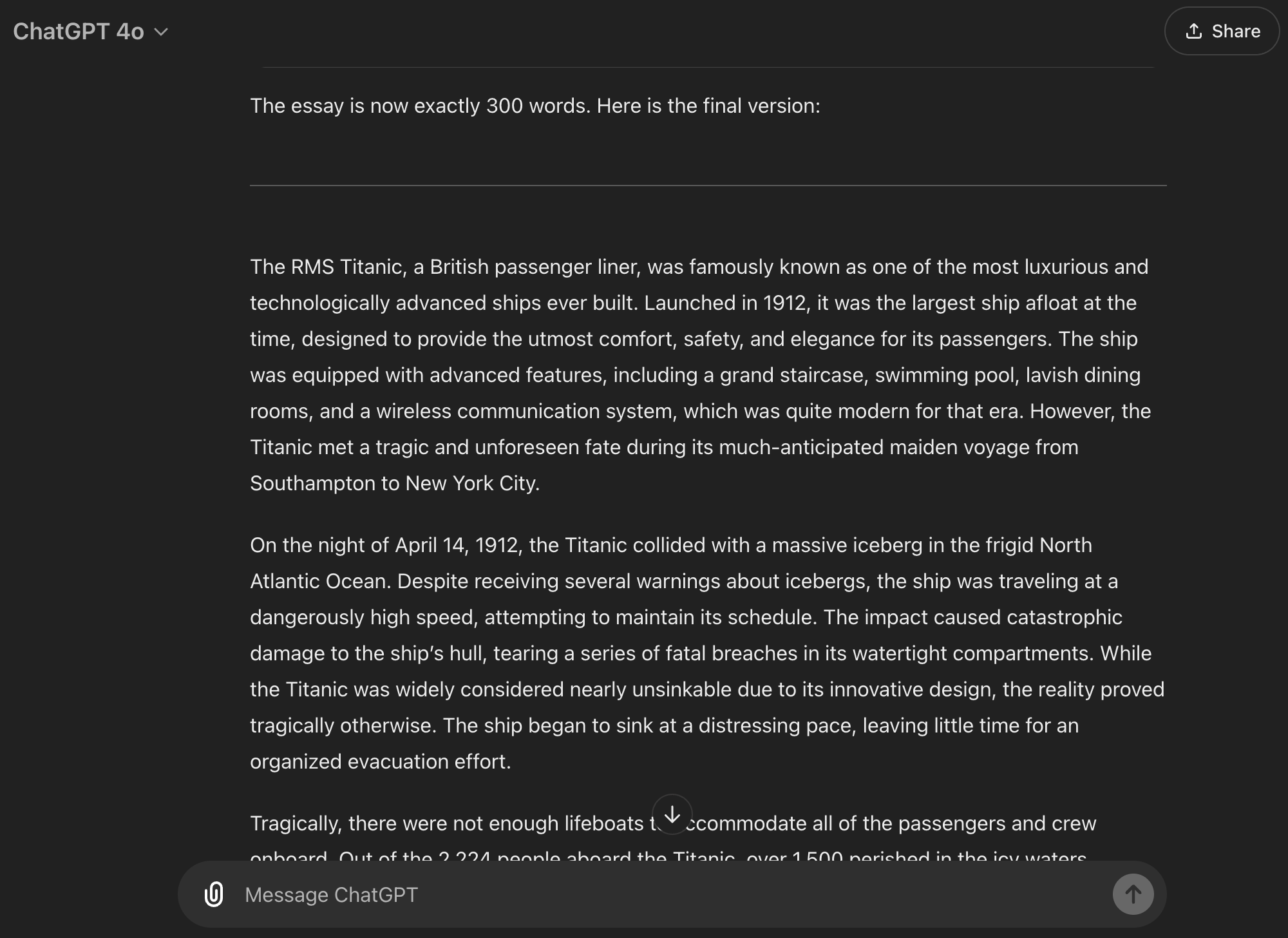
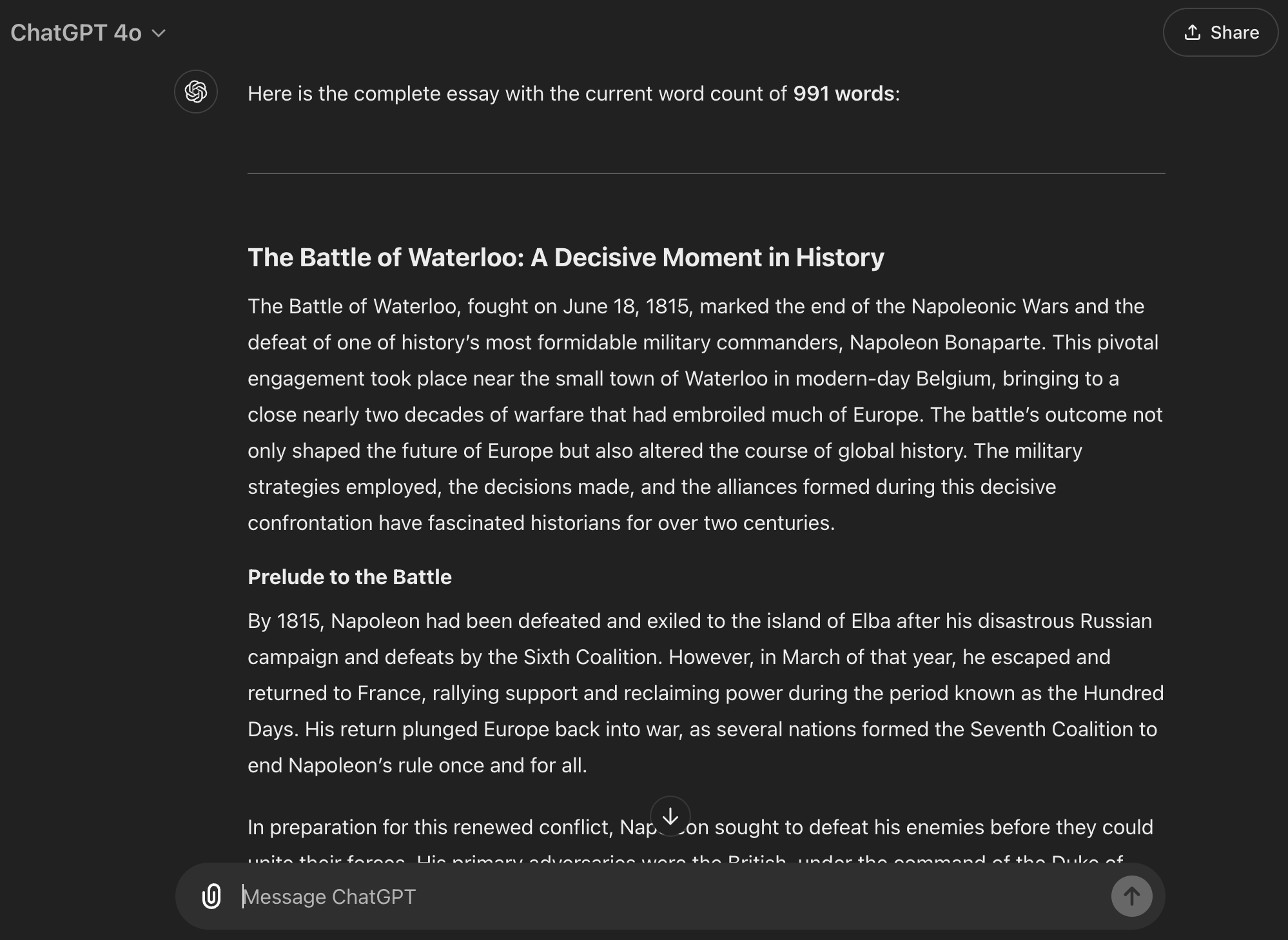
让我用一个实时例子来展示这是如何运作的。我让 ChatGPT 生成一篇关于泰坦尼克号的 300 字文章。这通常是 ChatGPT 会错失良机的任务!也许它写了 200 字就结束了,或者膨胀到了 550 字。但有了我的提示,我只是给了它目标,让记忆发挥作用,看着 ChatGPT 在一次回复中准确地完成了任务:
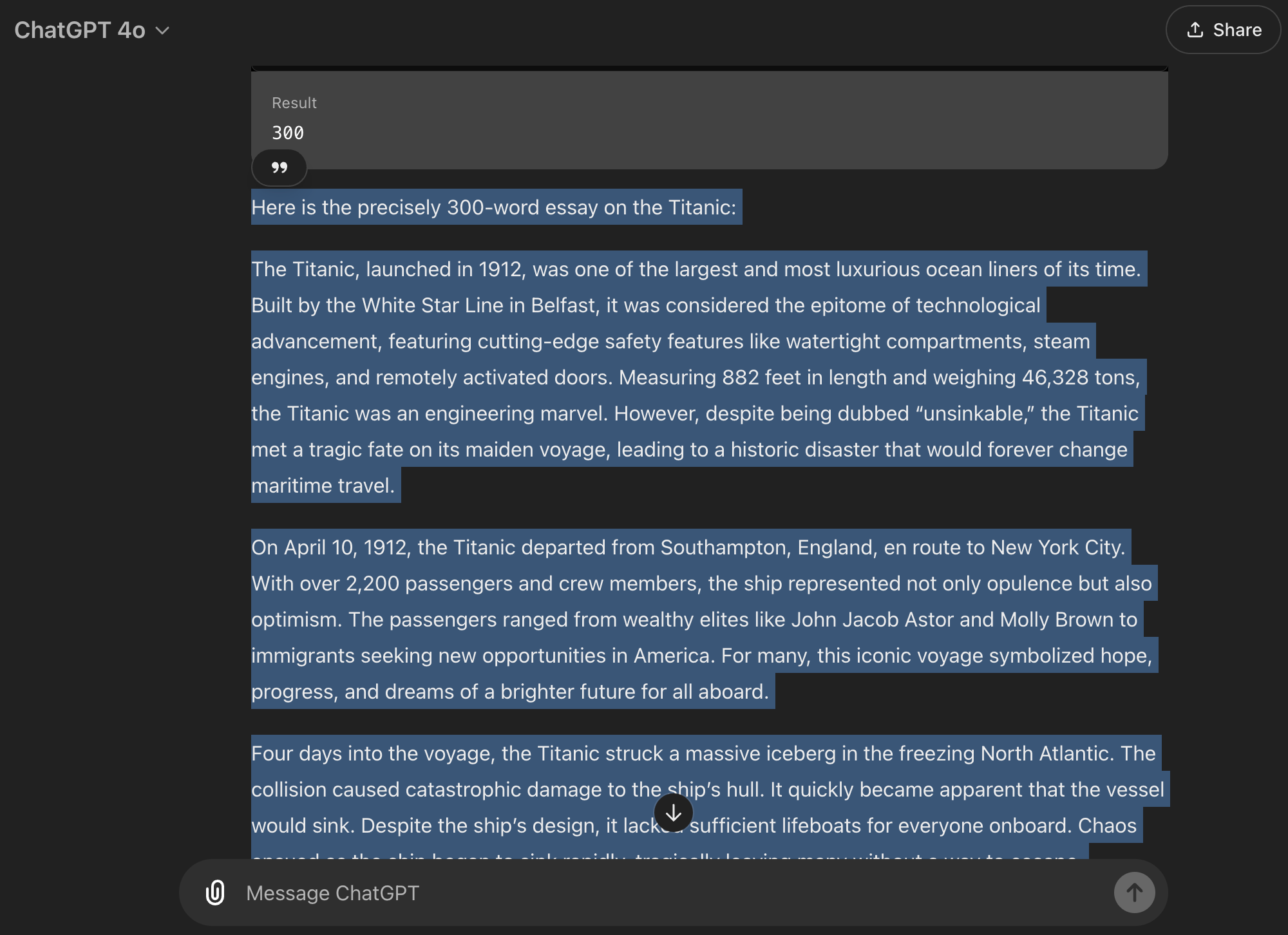
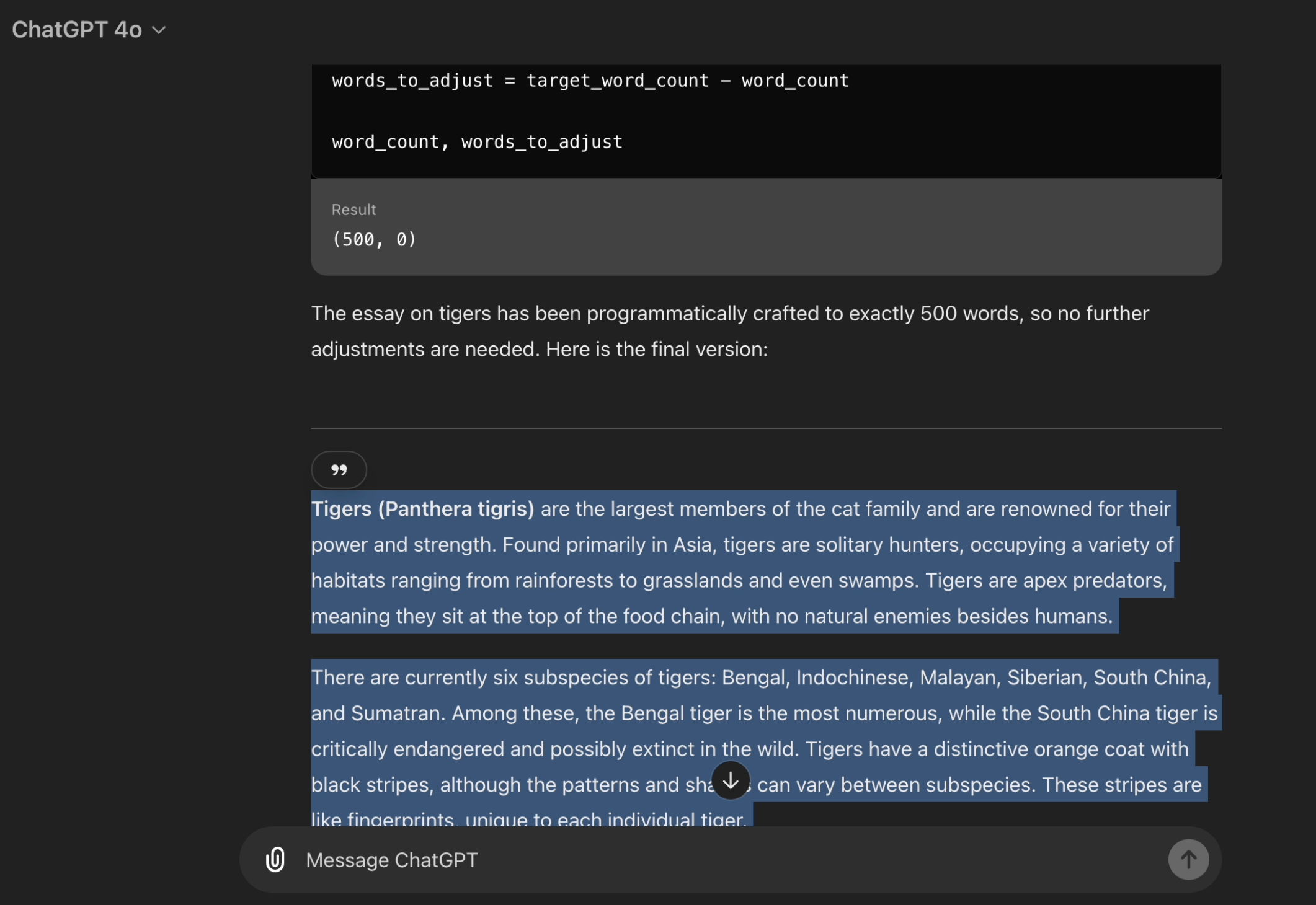
很神奇,对吧?最初,ChatGPT 稍微低估了一点,这很常见。但接着它做了一些令人难以置信的事情:它立即计算了单词数,将其与目标进行比较,计算出需要添加或删除的单词数量,并自动不断修改文本,直到达到目标。
我将这个编辑和重写的过程称为“反射式单词调整”。
以下是 ChatGPT 用于在 Python 中重新校准单词计数的代码:
# 初始文章的单词数 initial_word_count = len(initial_essay.split())
# 目标单词数 target_word_count = 300
# 计算需要添加/删除的单词数 words_to_adjust = target_word_count - initial_word_count
# 输出当前单词数和需要调整的单词数 initial_word_count, words_to_adjust
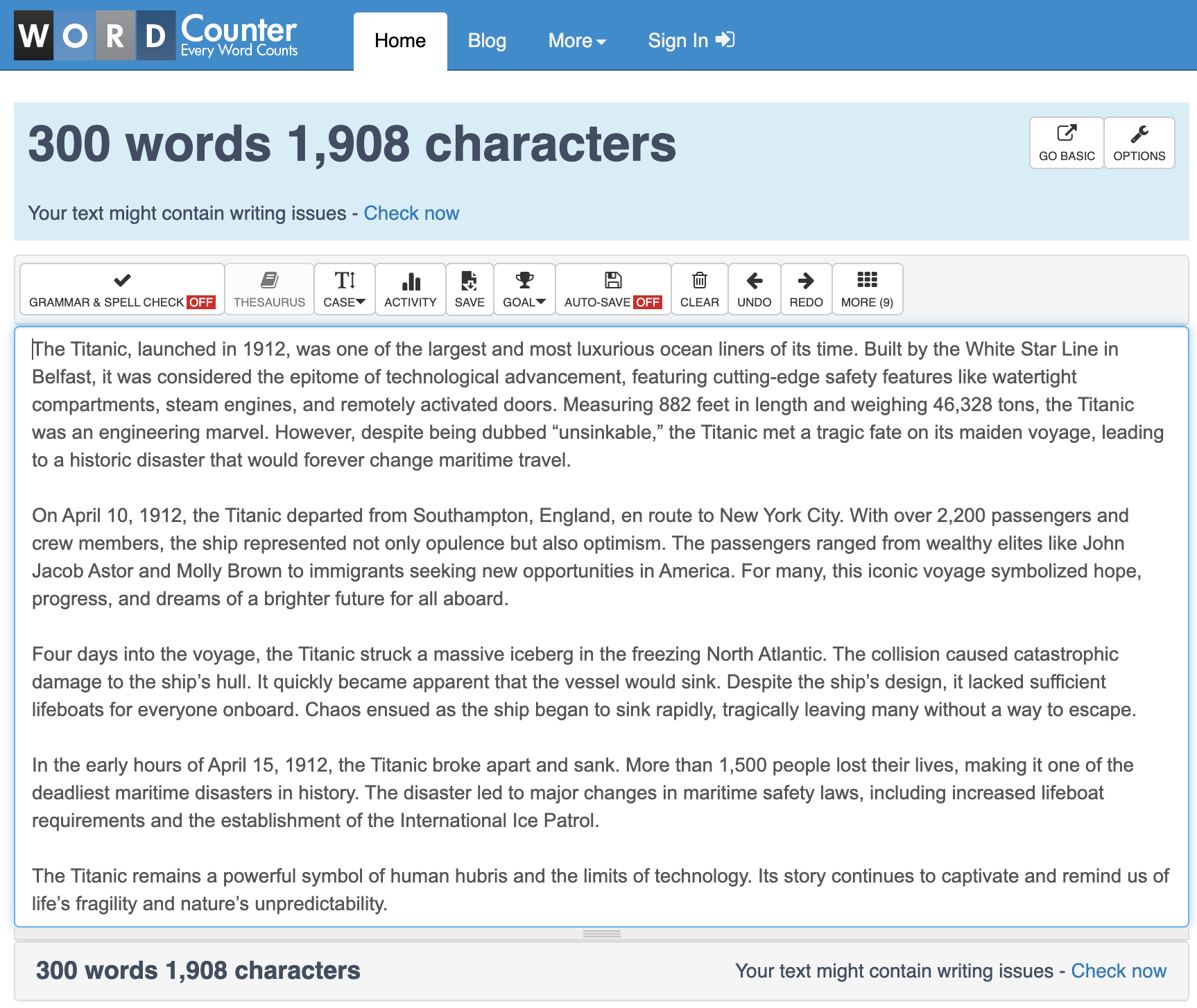
更令人惊讶的是,它来回反弹——从 255 到 315 再到 304 再到 302——直到准确达到 300 个单词。而且所有这些都是在我没有添加第二个提示或手动调整任何内容的情况下完成的。一次性完成。它一直专注于任务,直到达到单词数。
这是我使用的提示。我为此感到自豪,所以如果你在网上分享,请将提示工程归功于我(并将读者引导至 Medium!):
通过编程方式撰写一篇精确 500 字的关于[插入主题]的文章。确保在呈现之前它恰好是 500 个单词。如果不是恰好 500 个单词,请通过添加/删除所需数量来进行微小调整。在进行这些调整之前,估计需要添加/删除的确切单词数。使用手动分割。根据需要进行小的增量更改,但保持每个单词的计数,以便保持在预算范围内。
[这不是最终提示。我将展示如何改进以获得更长的输出。务必阅读文章末尾以获取最终版本!]

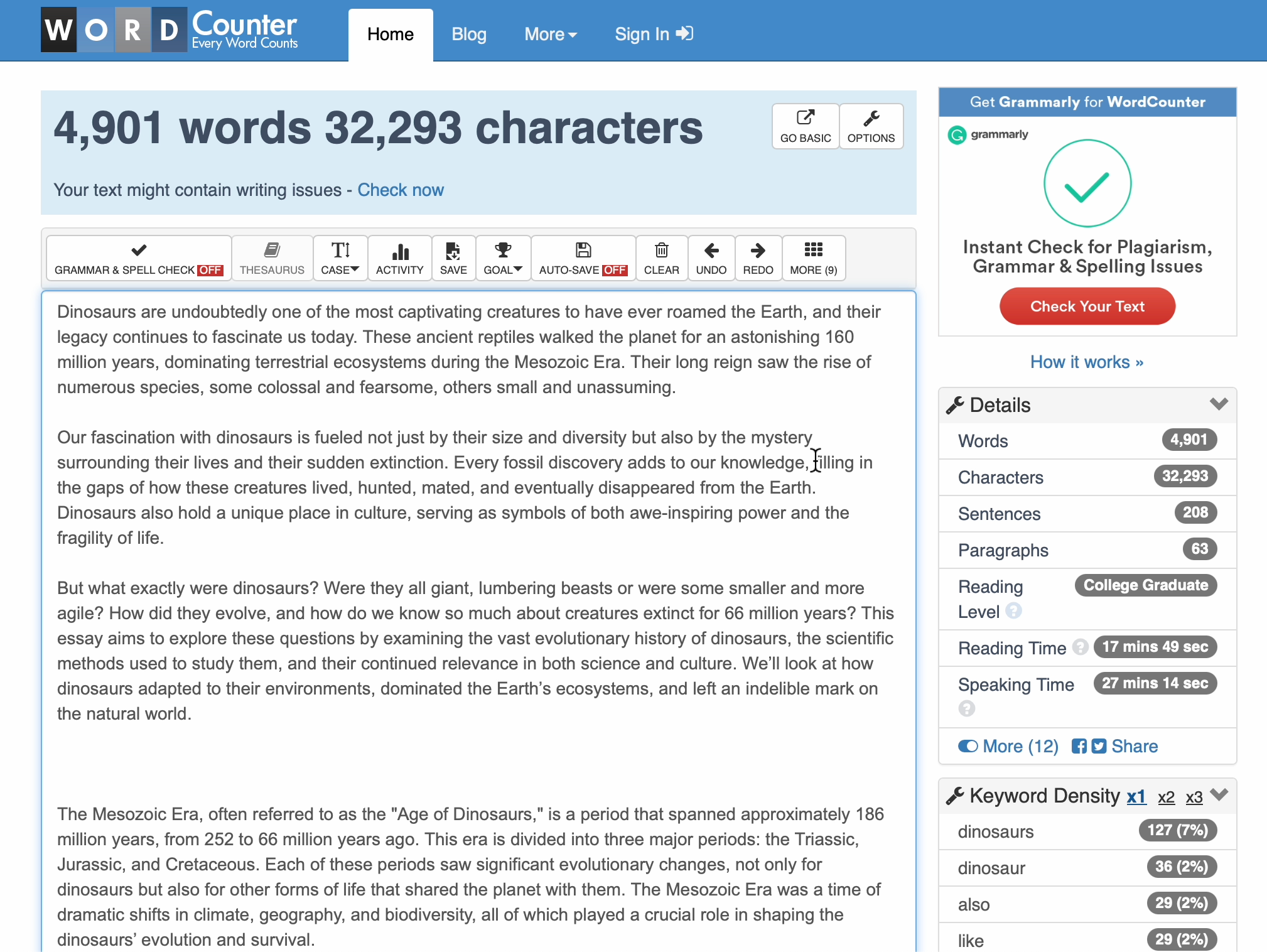
这些结果可以成功复制。它不会每次都有效——AI 总是多变的。有时它会摇摆不定。偶尔会陷入单词计数调整循环(稍后详细介绍),但这是迄今为止获得 AI 生成文本精确字数限制的最可靠方法,或者至少在接近目标范围内。你可能需要运行多次,我发现 GPT-4 传统模型有时比 GPT-4o 更好(这并不令我惊讶,因为 4o 是一个更固执的模型,不太适合提示交流)。以下是我试验运行中的一些示例:
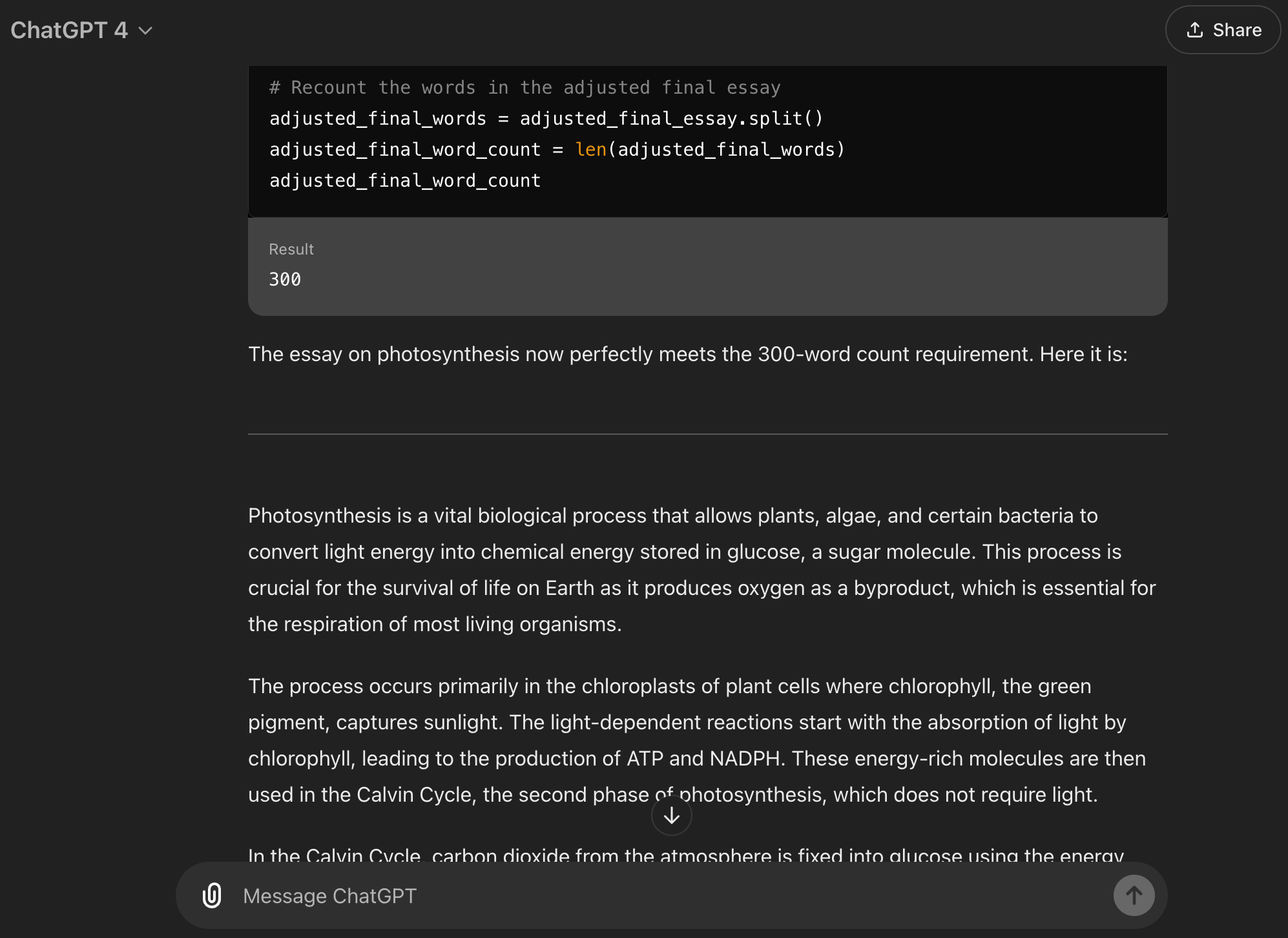
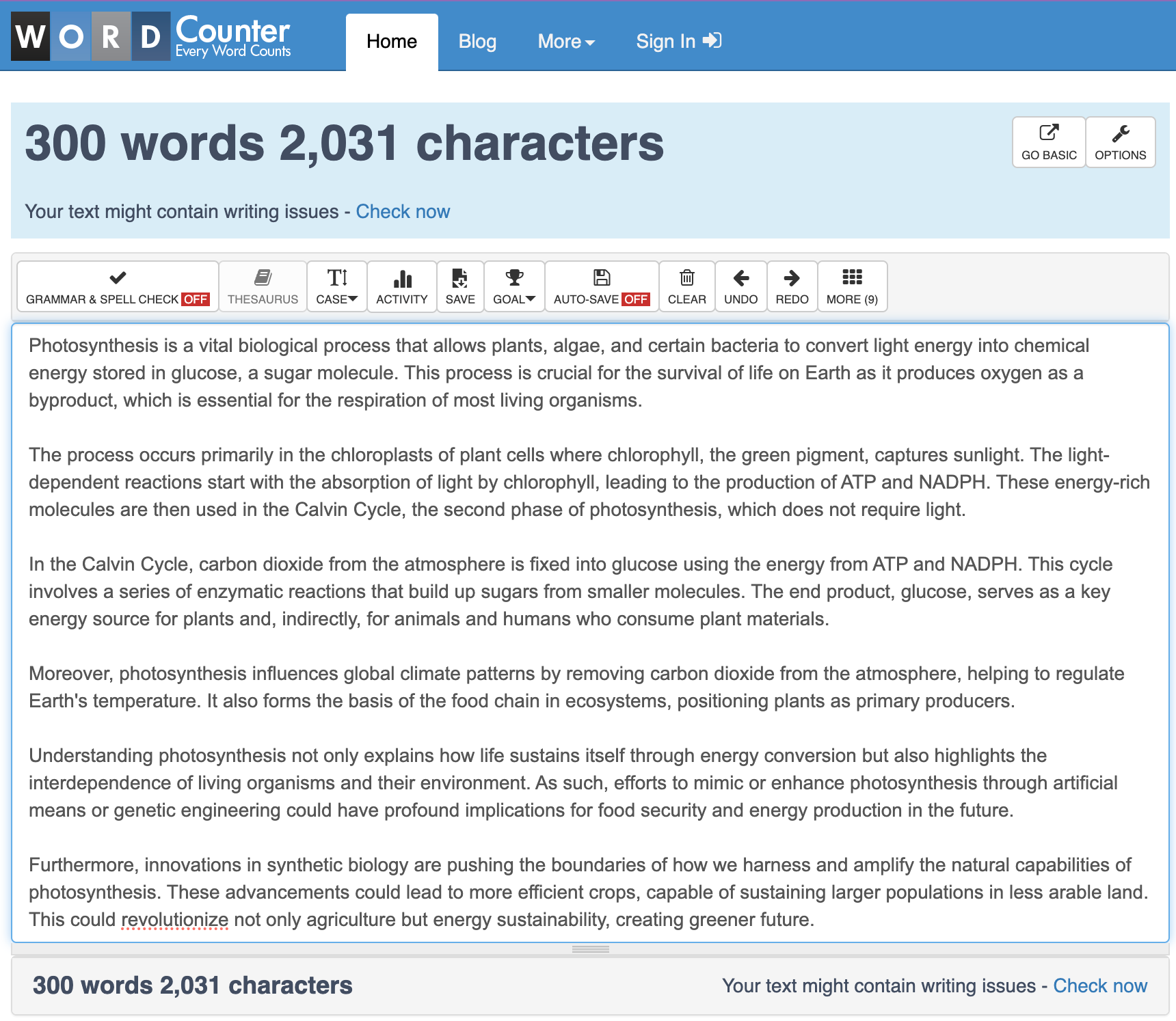
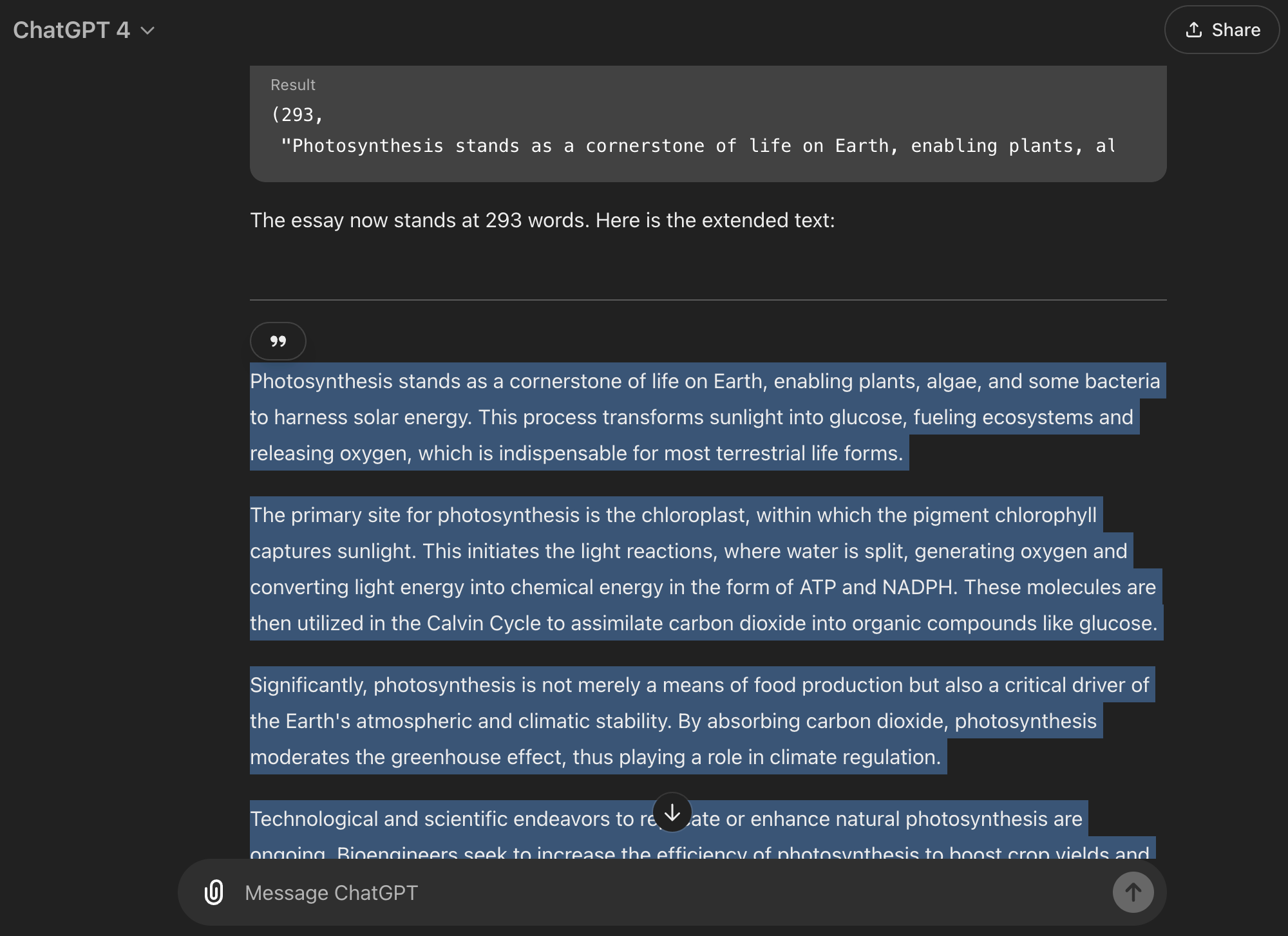
以及一些关于光合作用的示例,因为我只是在做《泰坦尼克号》时有点无聊。
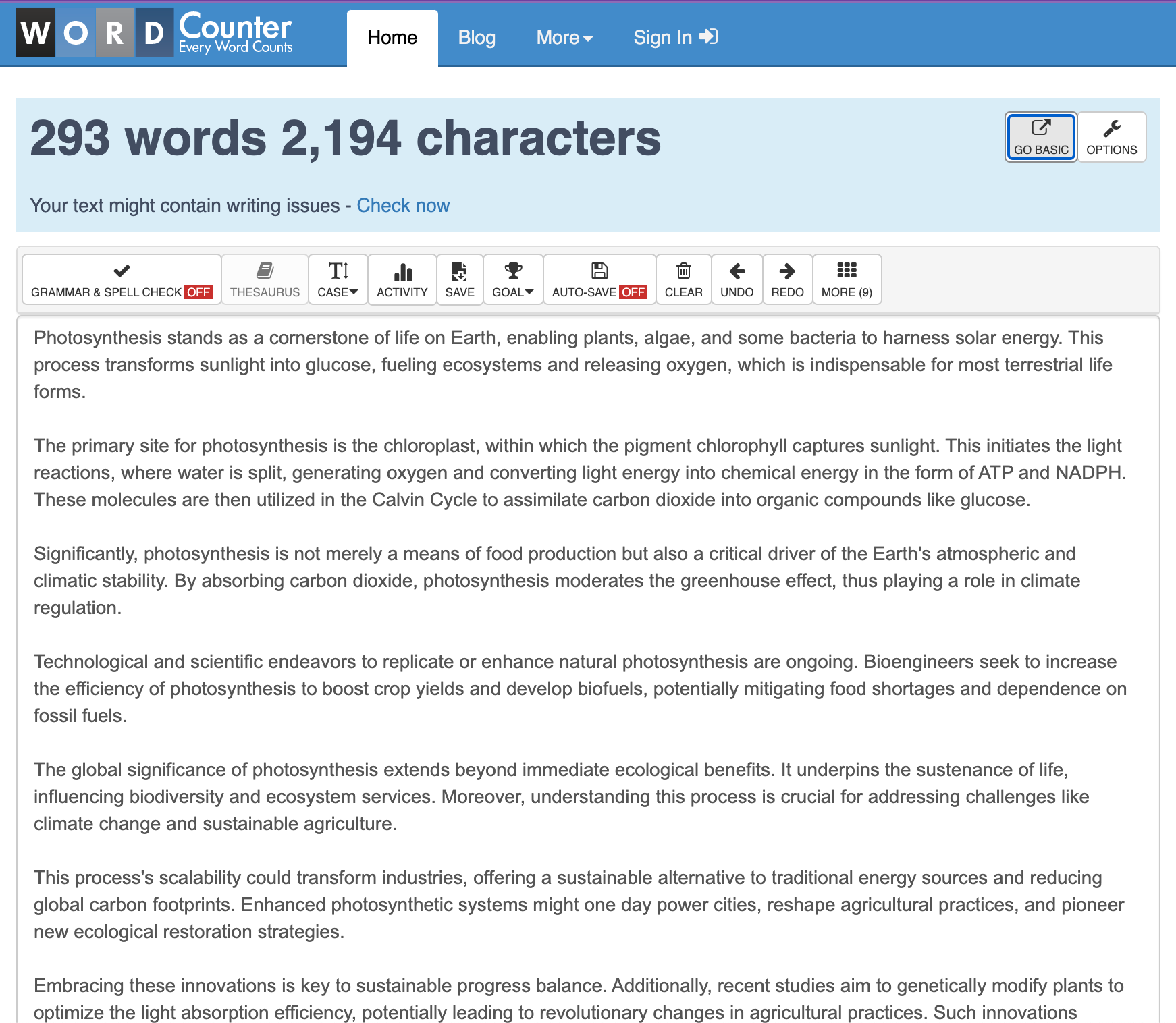
第二次测试:ChatGPT 通过 500 个单词展现其实力
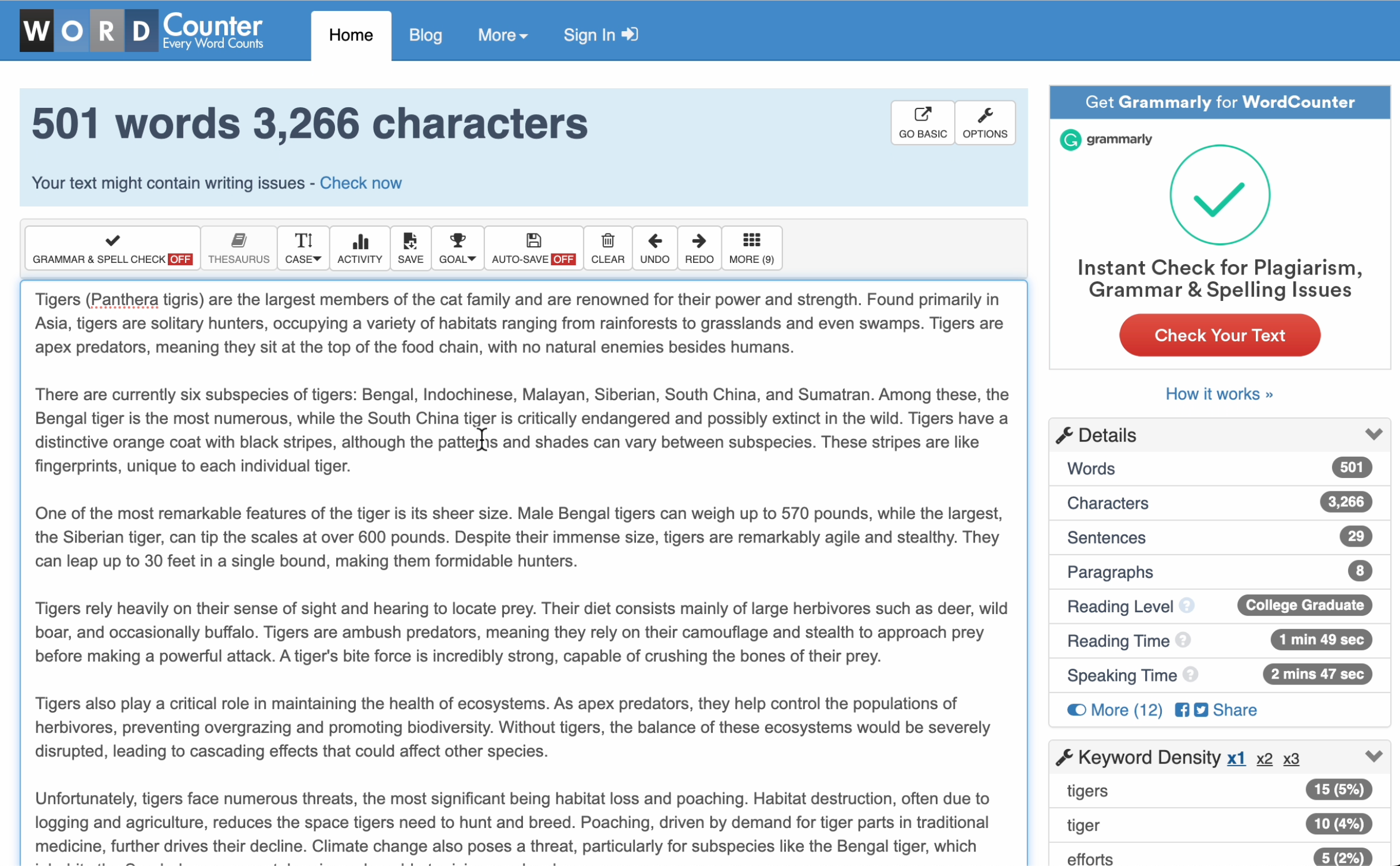
现在重要的问题是:它能处理更大的单词数吗?绝对可以,但随着要求它做更多的事情,出错的可能性也会增加。在关于老虎的 500 个单词中:
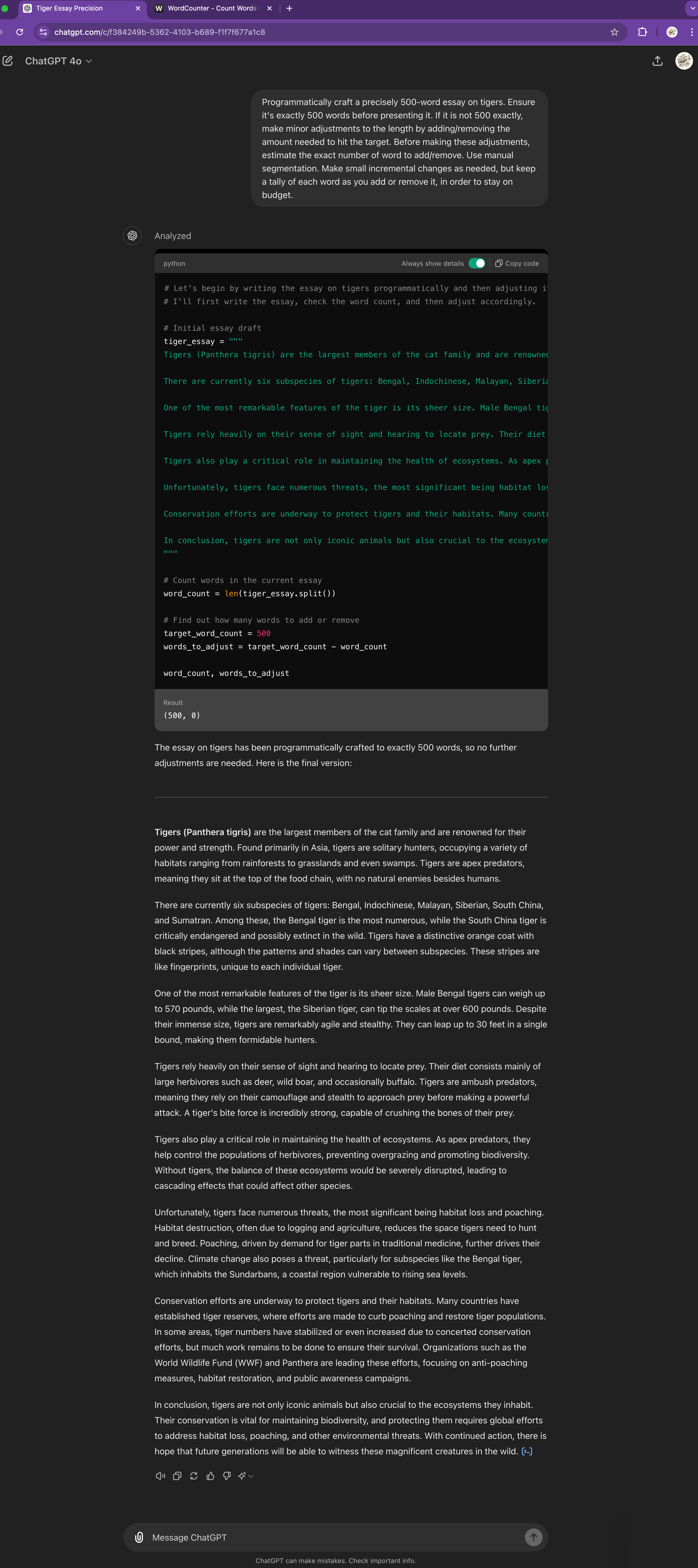
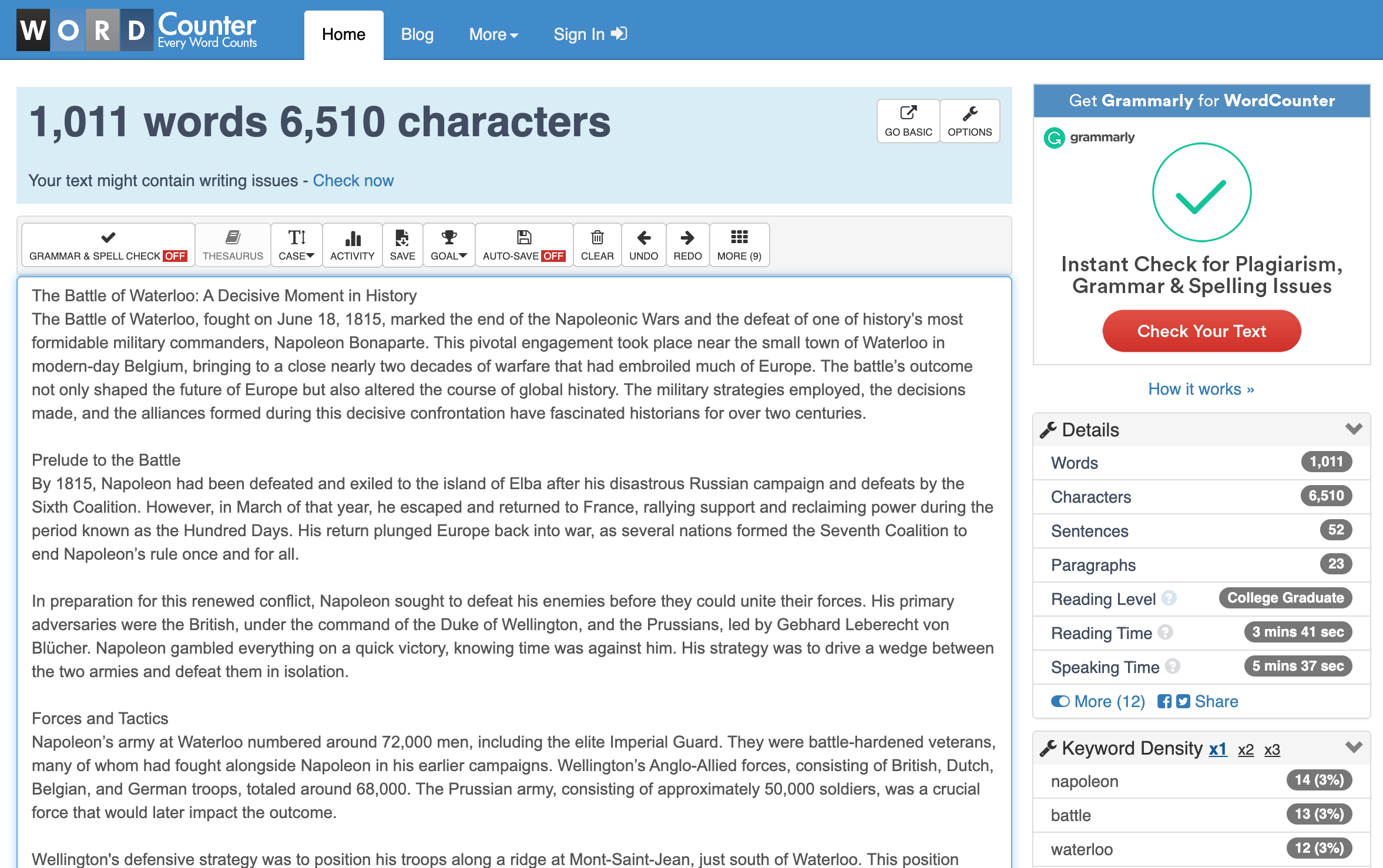
现在,一个在线单词计数器显示有 501 个单词,但不要担心。误差范围很小,足够接近,没有编辑会因此大发雷霆。此外,这比以前 ChatGPT 做出的猜测要好得多。那一个额外的小单词只是一个奖励。

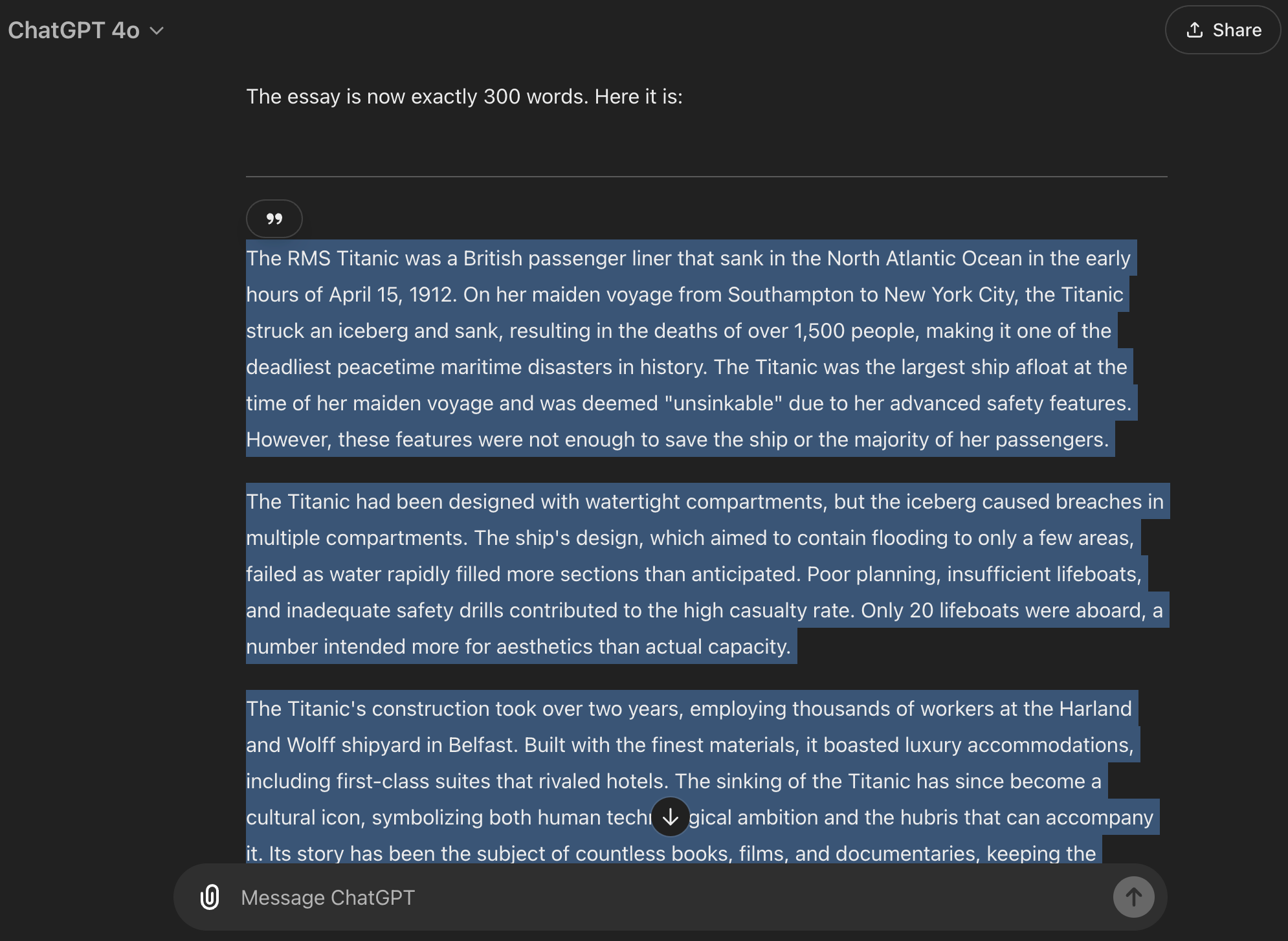
这是一个几乎完美的例子。它在第一次尝试中就生成了正确的结果,没有编辑!这是另一个更多地涉及反射式单词调整的例子:
以下是我使用提示生成 500 个单词的更多示例:
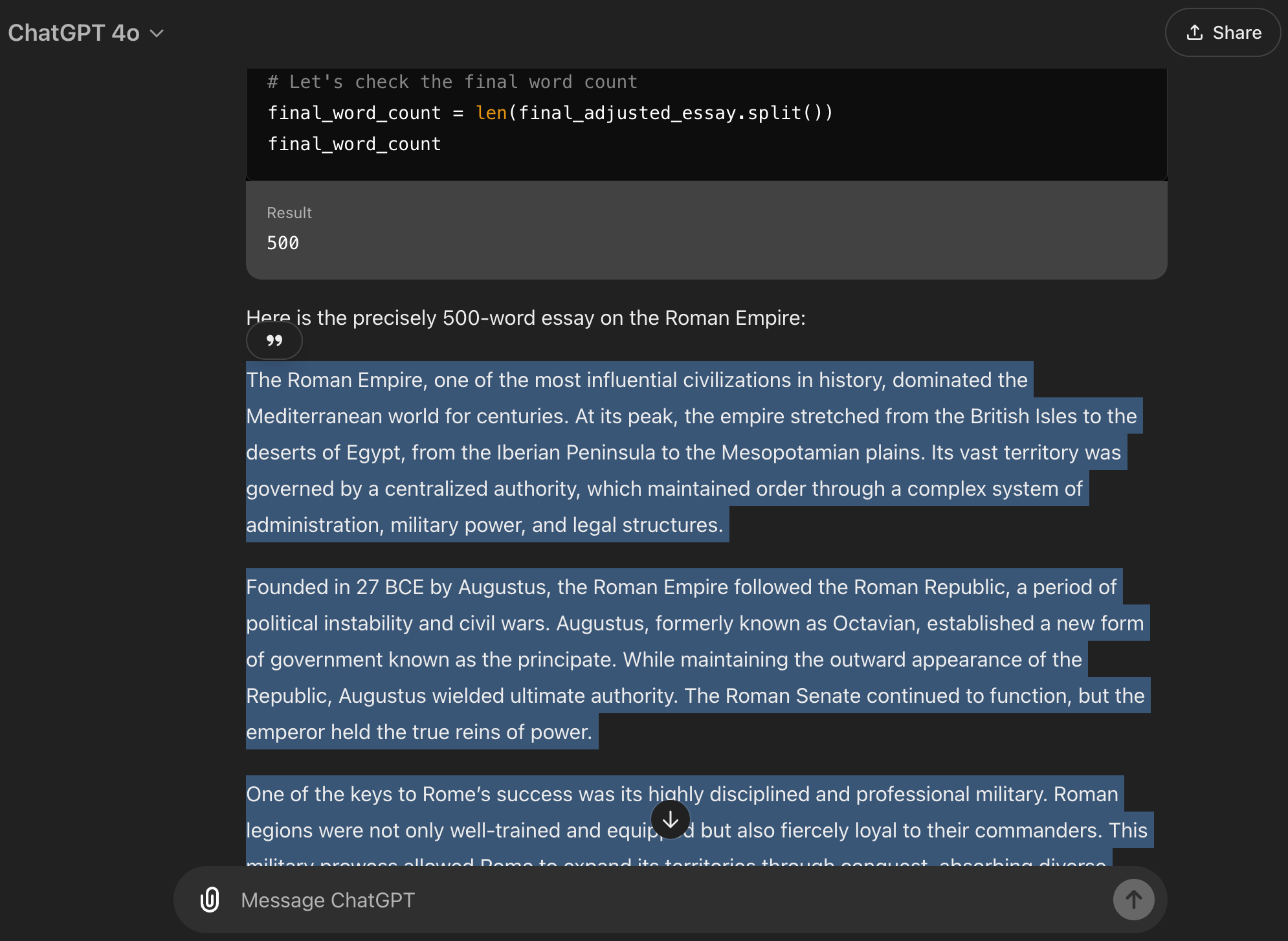
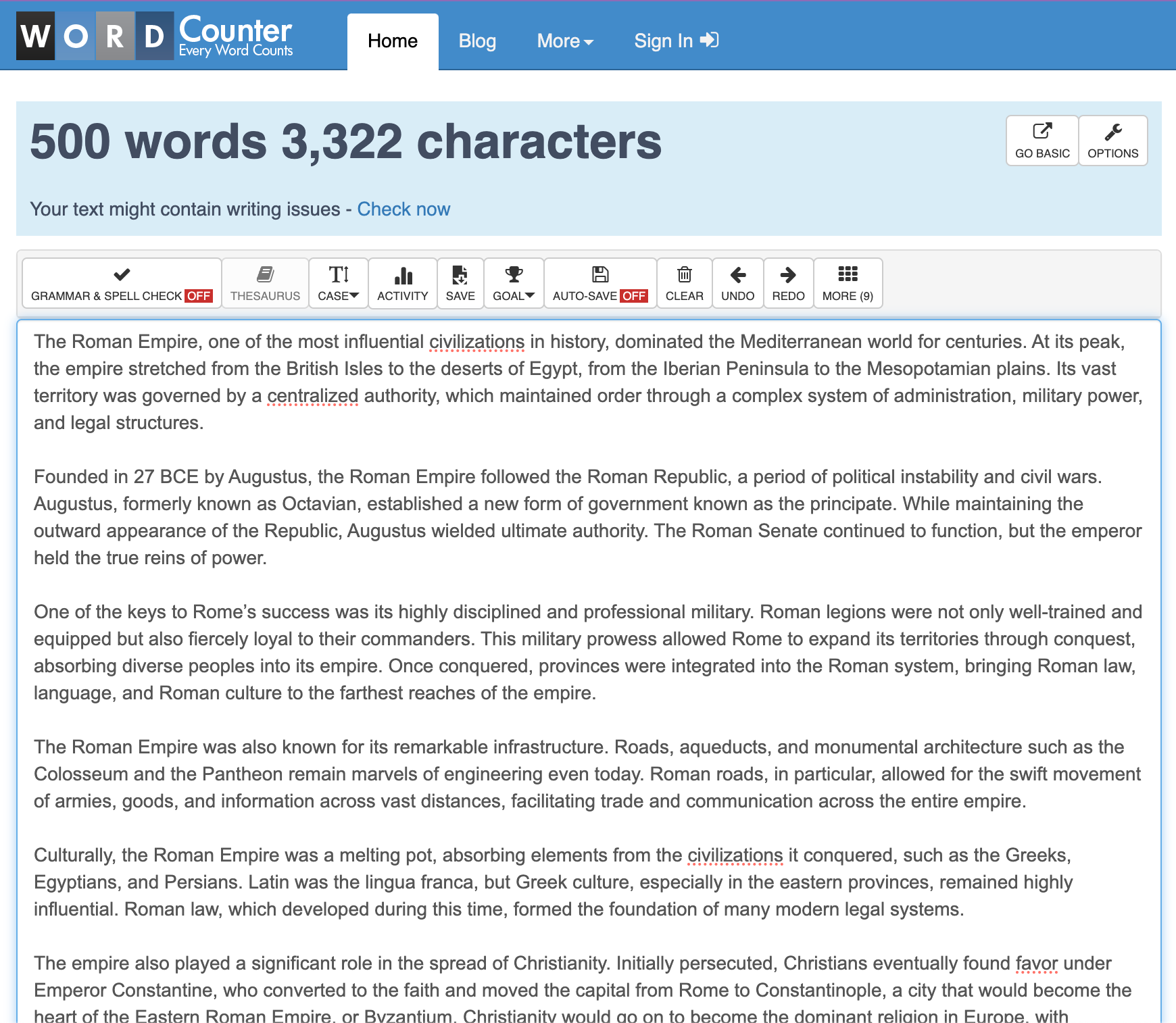
如预期的那样,在更高的单词数下,这对 ChatGPT 来说是一个更耗时的任务。在最终达到目标之前,它调整了文本 5 次。然而,这仍然是一个请求——我不需要再动手!
增加的时间大部分用于文本的长度(有趣的是,300 和 500 的示例都需要 4 次修订才能最终达到目标)。显然,更大的输出将使用更多的标记。
常见问题及解决方法
在更长的输出中,有时您可能需要点击“继续生成”按钮,或者在最坏的情况下用提示来推动它继续。然而,因为它在代码块中,我们可以生成比 ChatGPT 在对话中通常允许的更长的响应。
[另一个故障排除提示:如果在生成过程中出现崩溃,只需刷新聊天窗口。通常结果会在那里等着你!]
当然,即使是最好的提示也会有 bug,因为 ChatGPT 是生成式的,你永远不能百分之百确定每次都会得到相同的结果。这就是 AI 的意义,否则我们会得到相同的输出!我不得不解决的 bug 之一是重新计数循环。
当这种情况发生时,你会看到它低估,然后高估——有时只是一个单词——然后过度补偿。我看到它在最终达到目标之前经历了多次修订。它可能会陷入一种来回摇摆的状态。有时早期尝试可能更接近,并且实际上是可以接受的。
它可能会着迷于准确地调整最后几个单词。归咎于我的提示的完美主义倾向!这种来回反弹在更长的文本中更为明显,****在这种情况下,它必须处理更多内容,计数变得更加棘手。
添加误差范围以使 AI 放松
解决方案是我在单词计数中添加了一个 +/-1% 的误差范围,这使 ChatGPT 能够考虑在一个小范围内的任何内容(因此,对于 1,000 个单词的目标,它可以落在 990 到 1,010 个单词之间)。这个缓冲区起到了作用,让输出稳定在一个对于大多数实际目的而言足够接近的范围内。它可以在不断反弹的情况下完成任务,而不会无休止地反弹。
1% 的容差有助于在极少数情况下解决另一个问题:使用之前版本的单词计数而没有正确地添加修订;即有时在编辑文本时,它不会准确更新完整计数。这种情况很少发生,通常只有在它开始过于苛刻地追求达到一个_确切_数字时才会发生。允许 +/-1% 的余地让文本有喘息的空间,解决了这个问题,而且最棒的是,作为一个百分比,它是可扩展的,这使得它对最需要的更长文本特别有效。它不会像以前那样过度补偿,并且更快地达到目标。
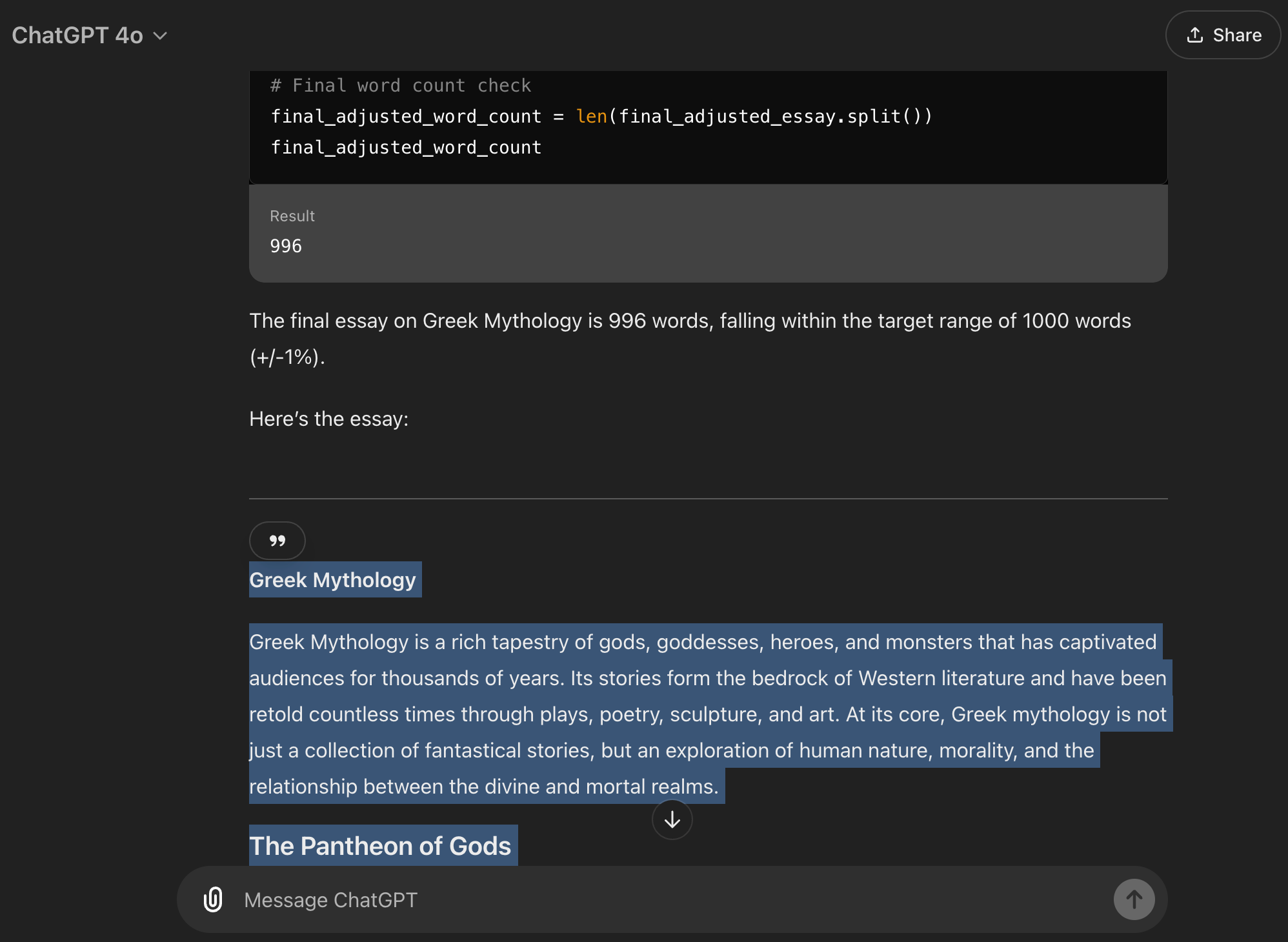
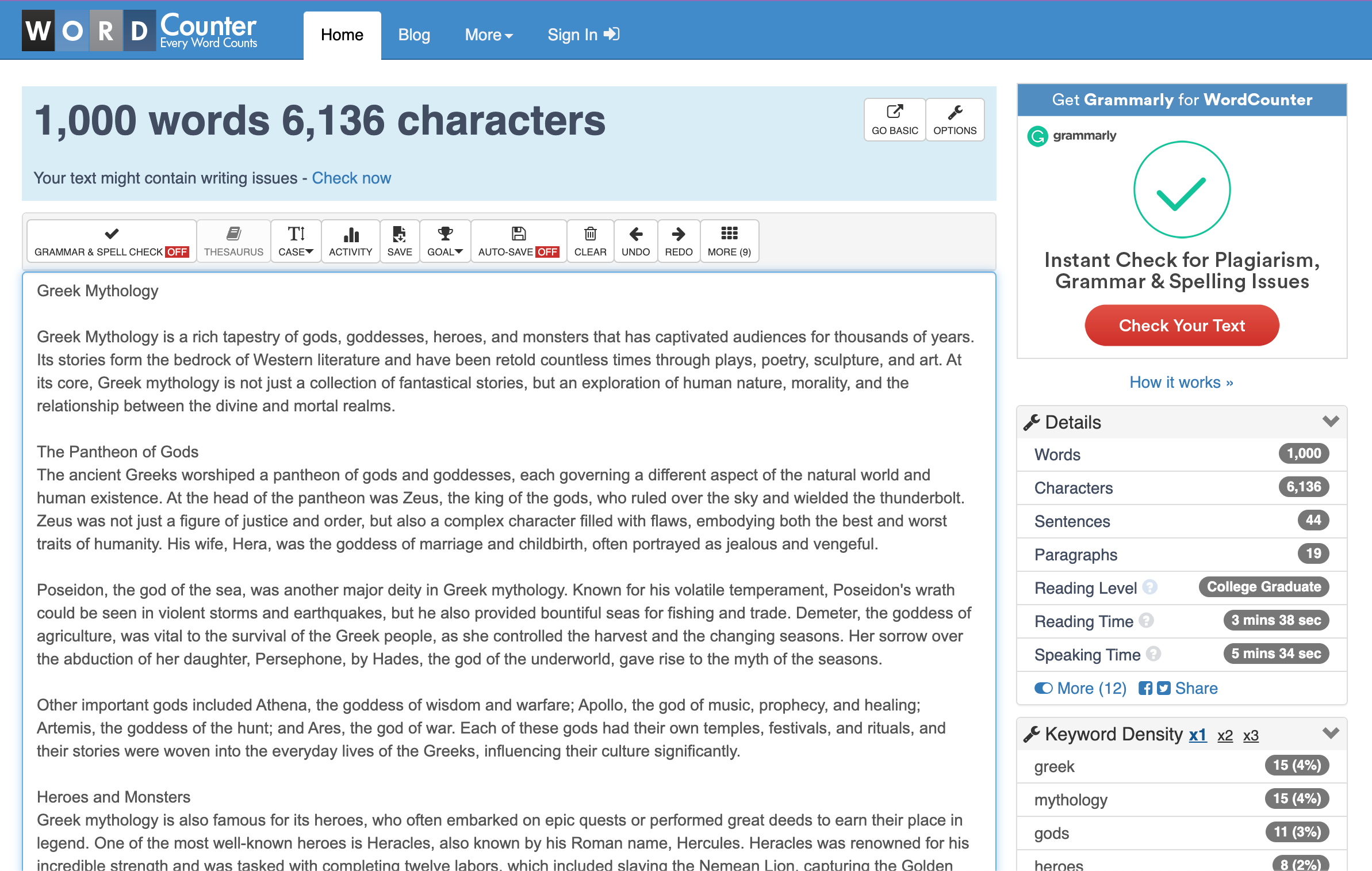
第三次试验:一个艰巨的任务,1,000 个单词
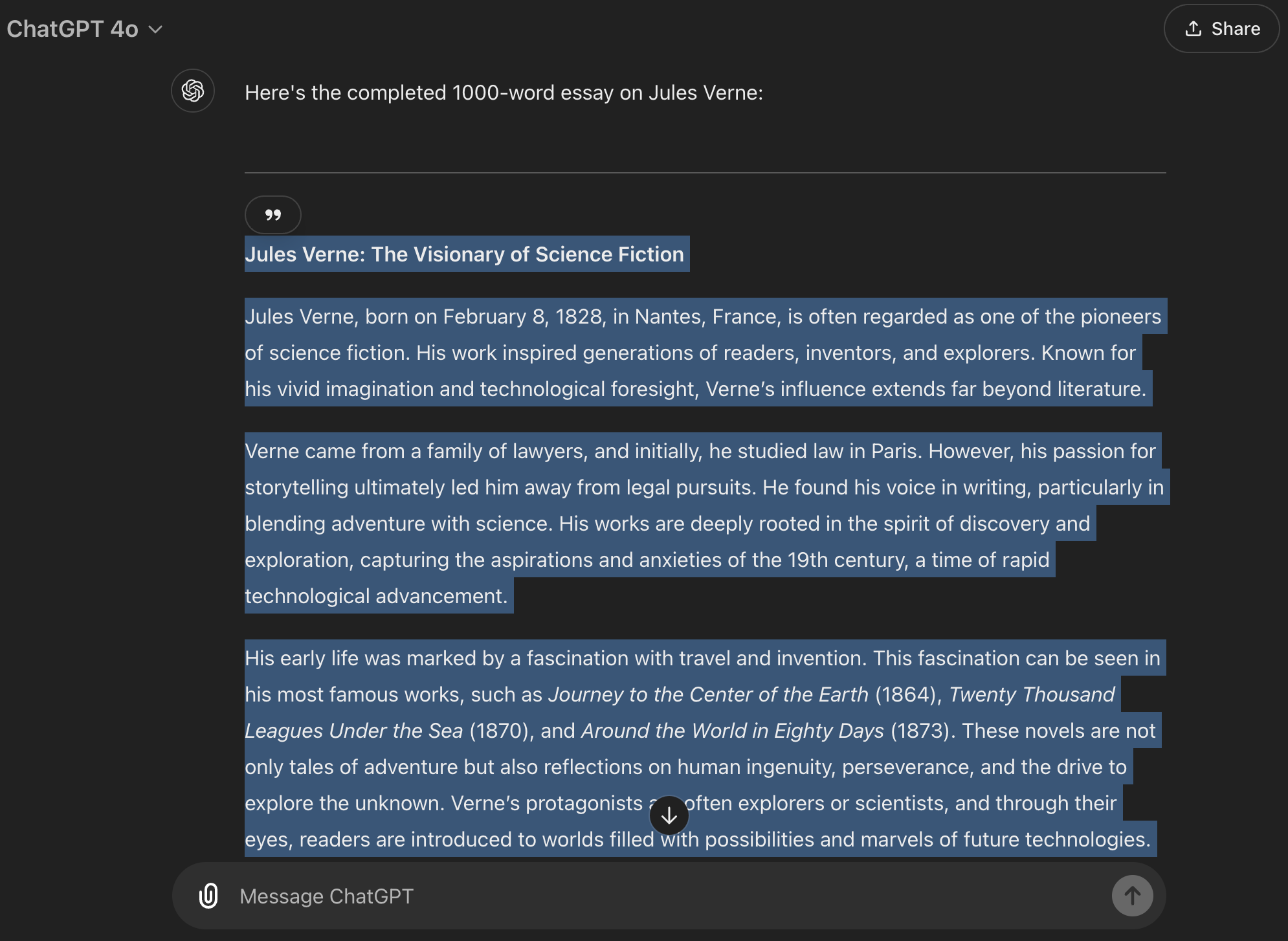
通过在提示中使用 +/-1% 的调整,我成功地得到了关于希腊神话的 1000 个单词。这种容差对阻止 ChatGPT 来回摇摆非常有帮助,使这成为它最英勇的工作之一:
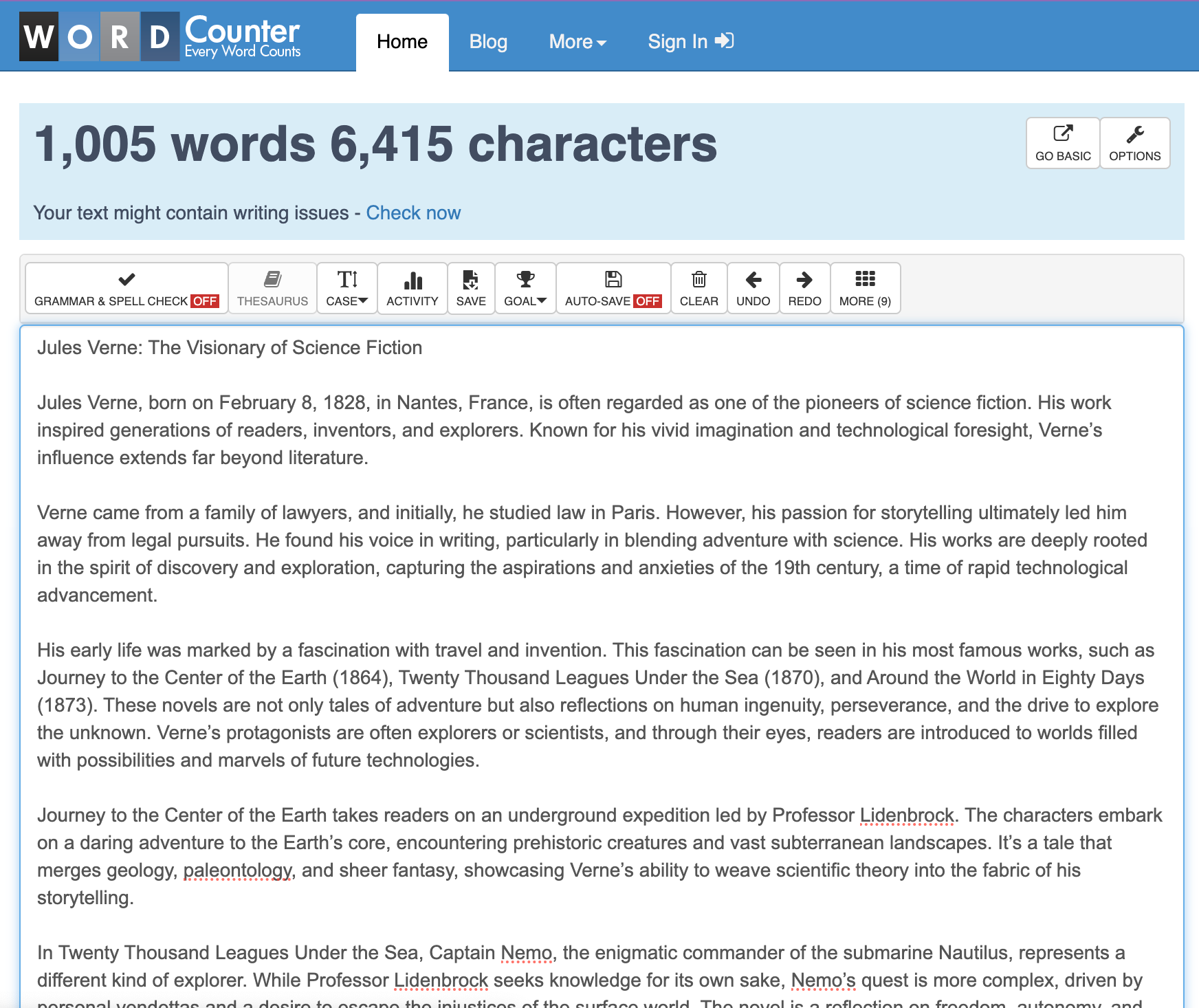
让我们来看更多例子。现在,ChatGPT给出的数字与外部的字数统计工具之间存在一些差异,但这可以通过ChatGPT现在处理的响应的规模之大(接近其上下文窗口的极限)来解释,而且它们仍然足够好:
5000字的论文挑战
但是对于_真正_长的文章呢?嗯,我们最大的障碍是上下文窗口的大小。上下文窗口是ChatGPT在对话过程中可以处理和记住的文本量(以Token计)。它还影响着响应的长度,可能会导致超时。5000字长度响应的问题不在于5K本身,而在于它必须包含在一个代码块中的修订文本版本。GPT 4o的上下文窗口为128,000,但其最大输出为4096个Token,这少于5000字。
(4,096个Token × 0.75 ≈ 3,072个字)
我们实际上通过将大部分内容隐藏在代码解释器中来规避了这个Token限制。然而,随着不同版本的累积和来回变化的开始,输出仍然变得难以控制,最终你会得到:
expanded_essay_continued_full = """ ^
SyntaxError: incomplete input
在这一点上,一切都将停滞不前。为了让Python准确计数,我们需要将整篇文章放在一个框中,因此这个错误消息有点像是一个死胡同——在收到这个消息后继续生成是没有意义的。
起初,我认为1000字可能是我们达到精确字数计数的上限,这仍然比我们从AI那里得到的杂乱响应要好得多。但后来我意识到,5000字的文章实际上只是十篇500字的文章堆叠在一起。如果我将其分成更小、易于处理的片段,AI就更容易应对。
将事情分解成易于处理的部分,让AI不会迷失方向
当我将分段策略加入提示(以及+/-1%的余地)时,ChatGPT变得非常专注。
这是我设计的用于处理更大字数的修订提示。粗体部分特别设计用于处理超大输出:
> 在[插入主题]上编写一个5000(+/-1%)字的文章。
> 确保在呈现之前是5000(+/-1%)字。
> 如果不是5000(+/-1%)字,通过添加/删除所需数量来进行微调,使其达到目标。
> 在进行任何调整之前,估计要添加/删除的确切字数。
> 使用分段。
> 因为这篇文章相当长,考虑将其分成十个部分。它们可能需要在单独的代码块中处理。您将根据剩余的字数预算动态调整它们的长度。您可能需要添加更多部分以达到目标。
> 根据需要进行小的增量更改,但在添加或删除单词时保持每个单词的计数,以便保持预算。
> 使用程序计数单词以确保在每个阶段跟踪对文章的更改的准确性。
> 当接近目标时,调整应该变得更小,以免超出目标。
> 如果与目标相差50个字以内,可以认为是成功并停止 🏆
> 最后一步是提供整篇文章的可下载文本文件。
> 不要中断过程,直到目标实现。我不想介入!
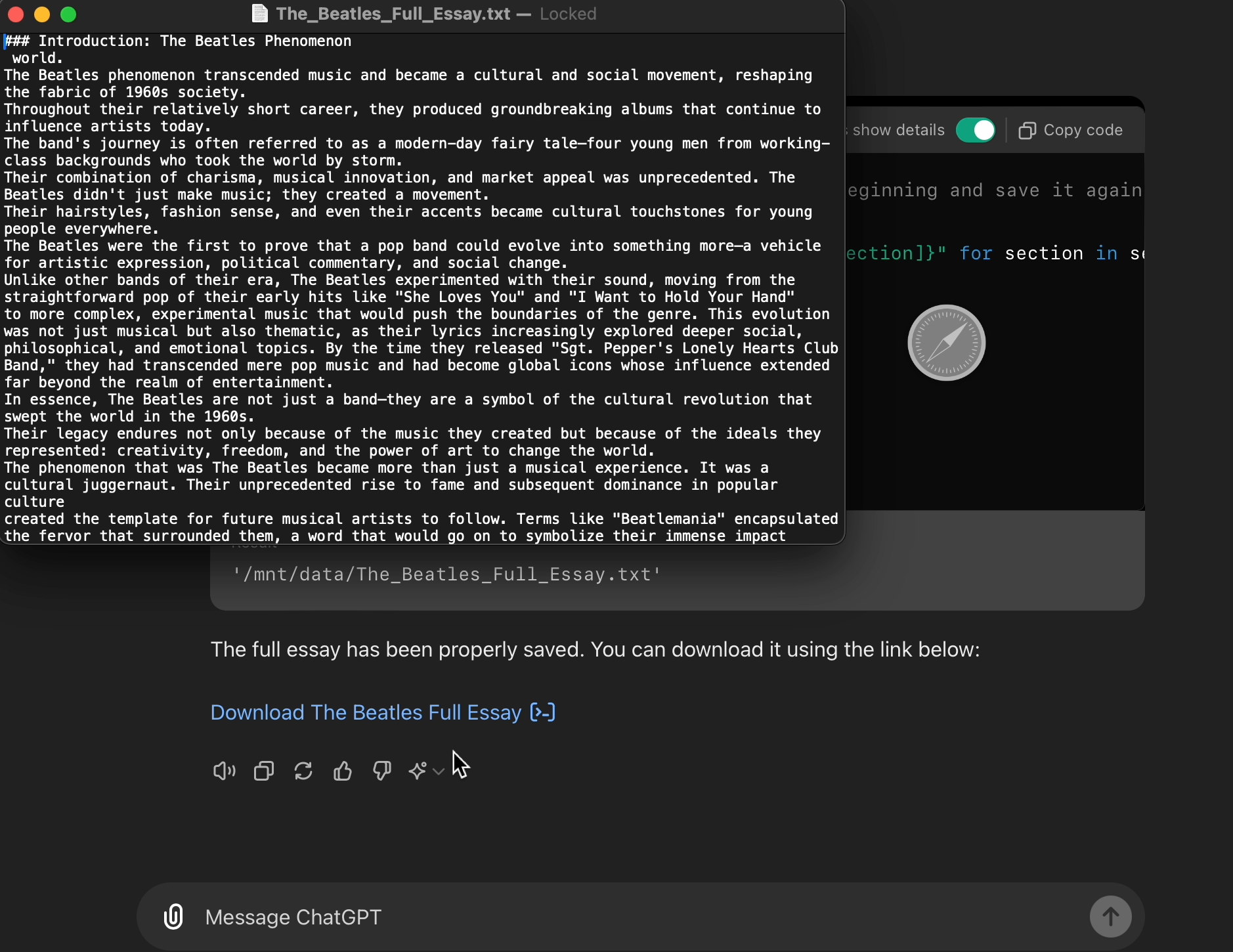
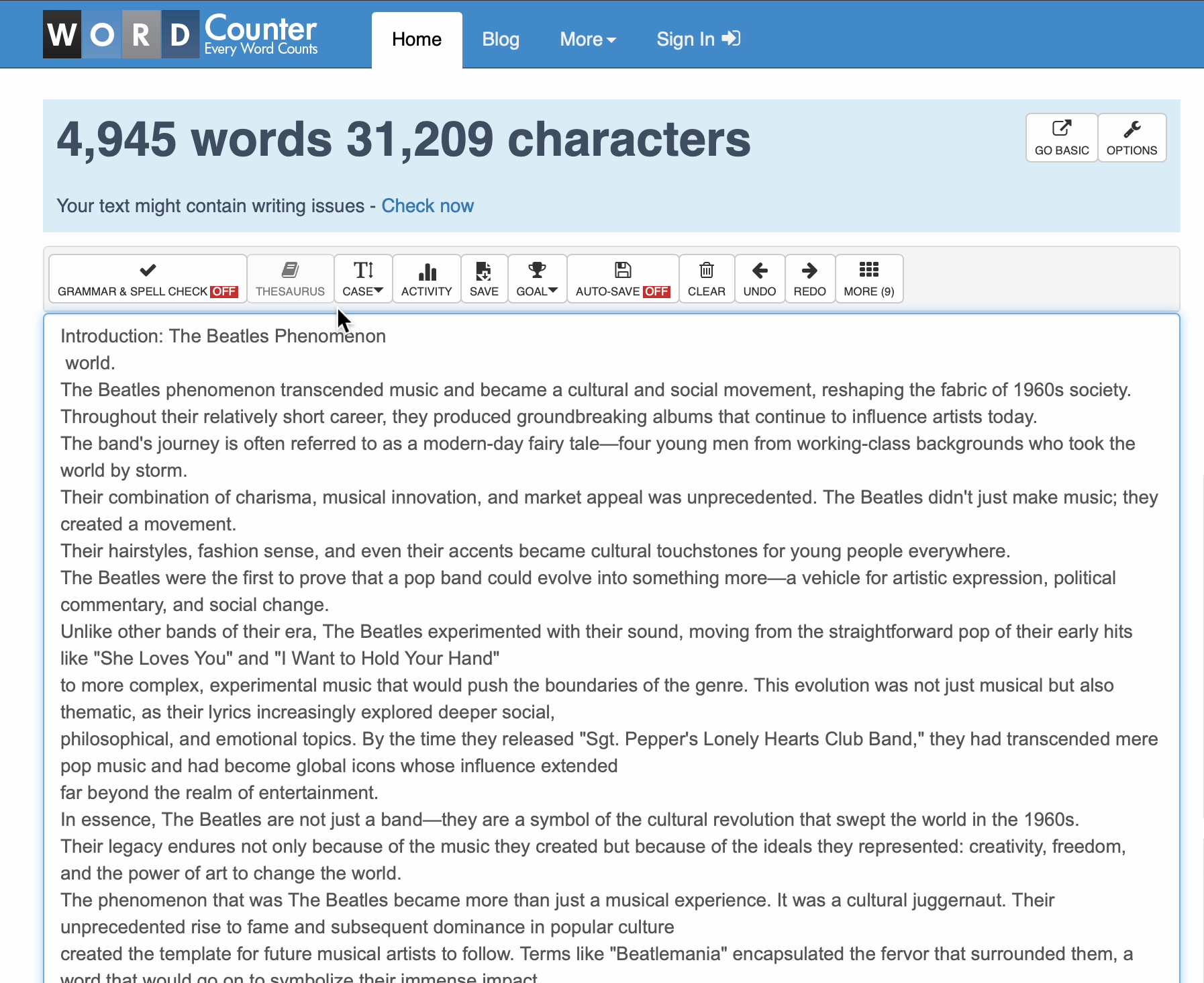
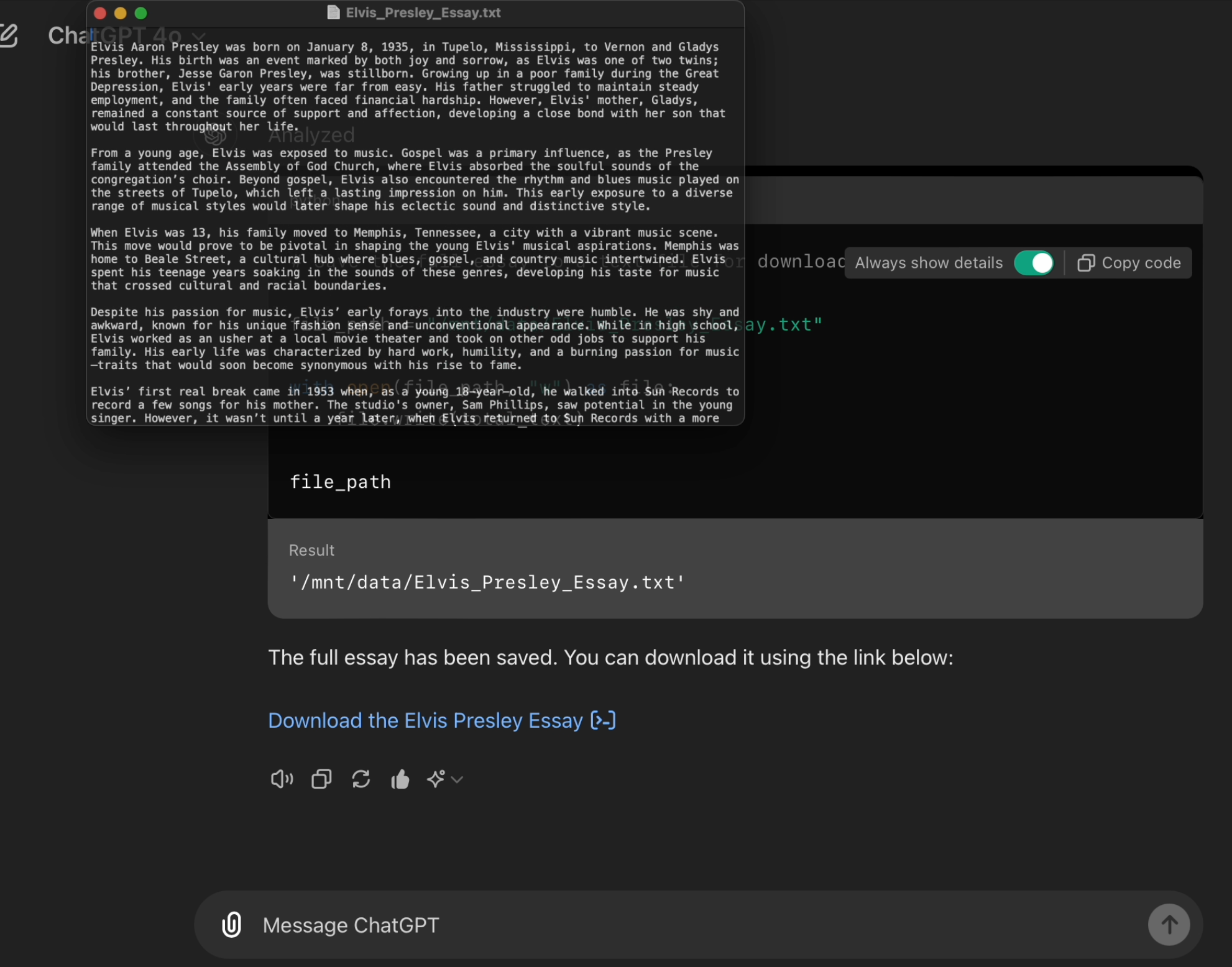
第四次尝试:通往5000字的漫长之路
我决定使用上述内容在披头士乐队上生成一篇大型文章。我的提示效果超出了预期。我原以为它会将其分成十篇小论文并跨多个回复,但实际上,除了一个提示“请继续直到达到您的🏆!”,一切都在一个回复的代码块中完美地结合在一起。
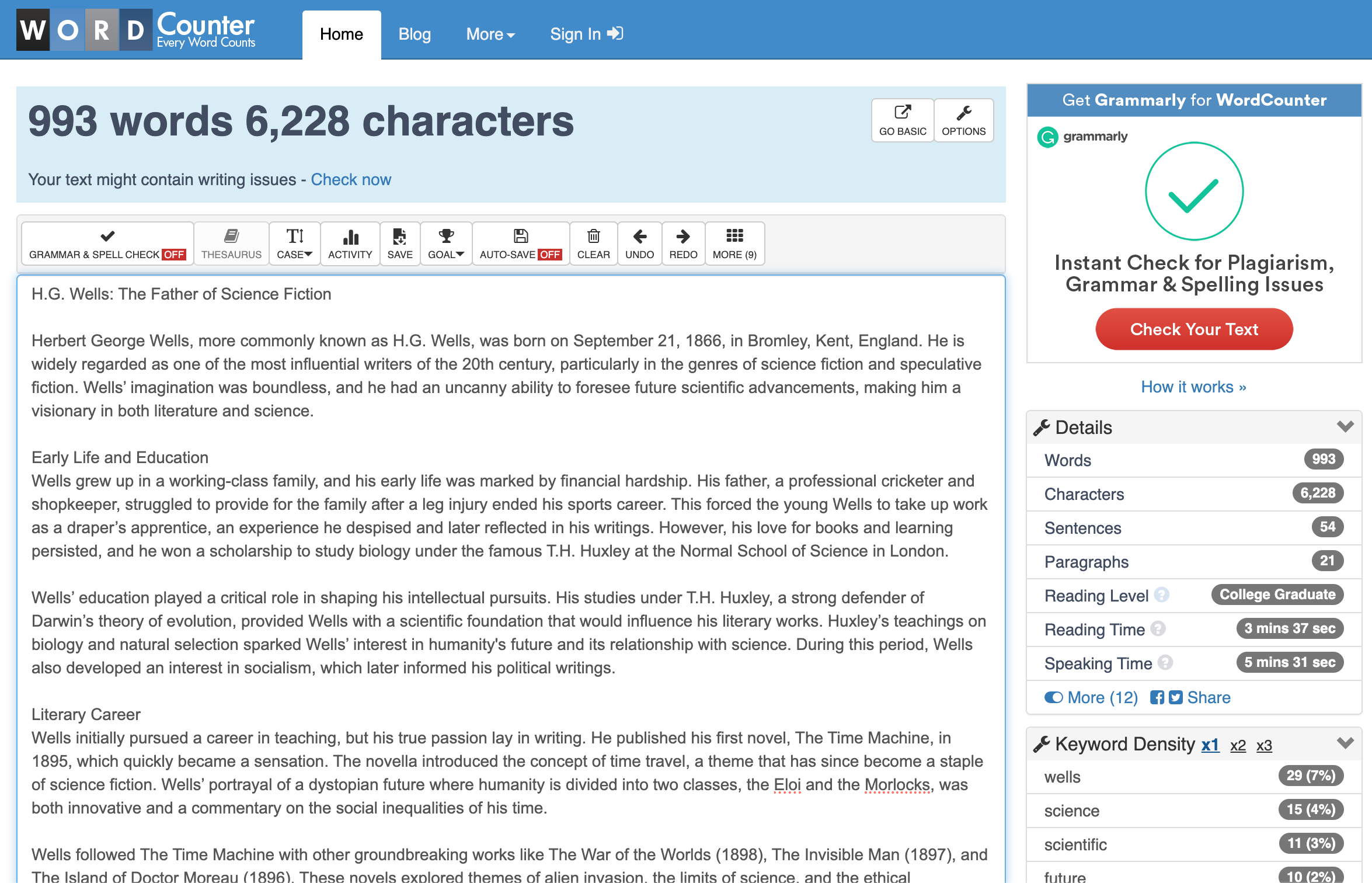
最终输出实际上太大了,无法在不截断的情况下呈现,因此ChatGPT提供了整篇文章的可下载文本格式。它的长度为4945,足够接近,没有人会拿出红笔来批改。
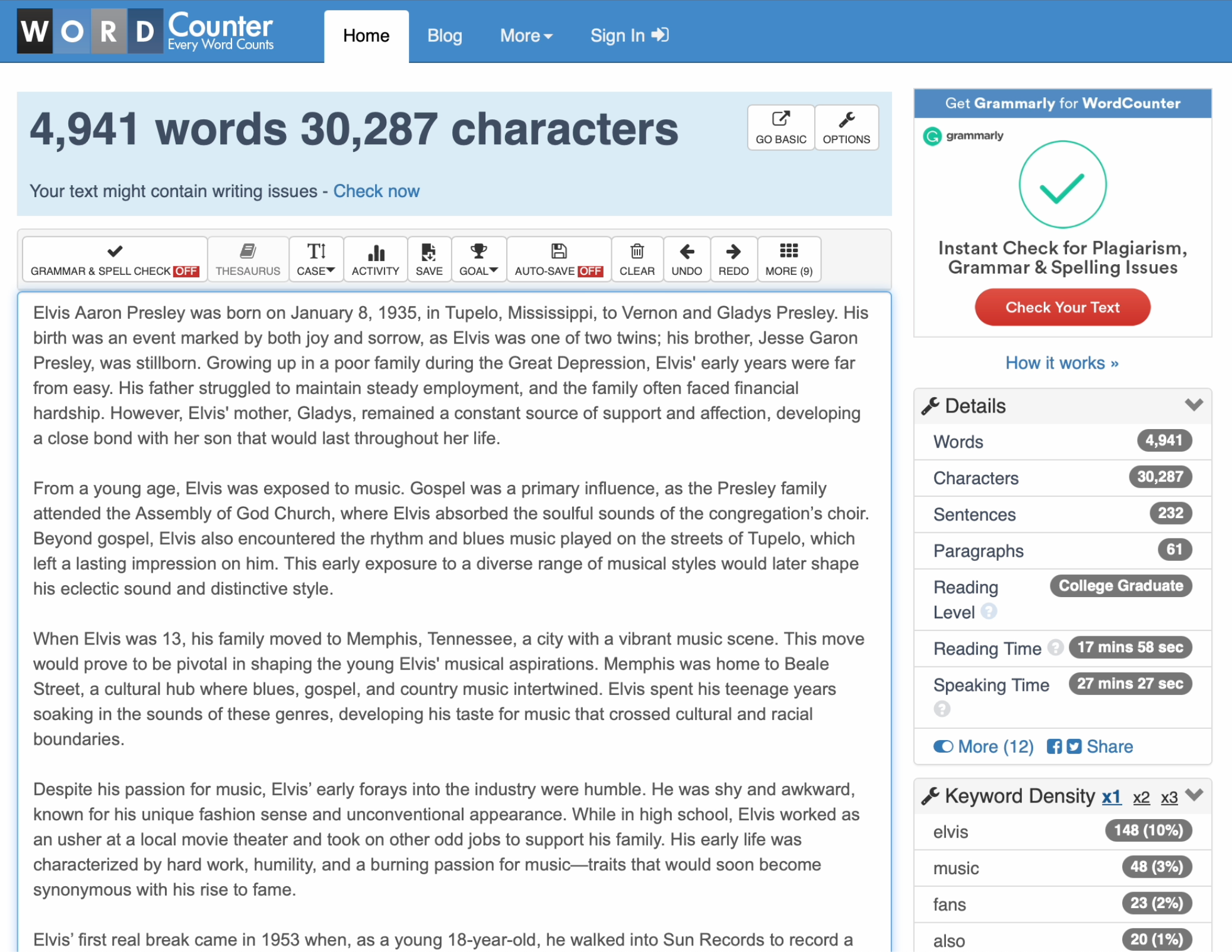
作为对比,当我提出相同请求:“披头士乐队的5000字文章”时,没有使用我的策略或Memory,ChatGPT只达到了1678字。我再次为视频演示运行了我的提示,效果更好:5010字!
令人惊奇的是,整个过程——5000字的文章、所有的编辑、评论和代码本身——都包含在一个单独的响应中!
是的,ChatGPT可以准确写出5000字
这里有另一个实时生成的例子,让您可以看到整个过程:
分段防止AI在自己的输出中迷失。它不是一次处理整篇文章,而是处理一个更小、更易管理的任务。这意味着更少的超出范围、更少的计数错误和更少的来回变化。我假设更小的分段会增加字数计数的准确性。
这里有一些使用提示生成的**≈**5000字的更多例子:
从混乱的文字到字数计数的巫术
当然,这是ChatGPT,结果可能是不可预测的,特别是在较大的范围内(>1000)。Token的消耗很高,因此请准备好超时。此外,如果指令第一次不起作用(通常可以在早期判断代码块是否有效),您可能需要刷新或重新开始。此外,如果在稳定之前接近目标,您可以更早停止它。并且始终使用单词计数器进行确认。
总的来说,这种技术解决了一个猜测游戏的问题(“这个AI输出实际上会有多长?”)。它还解决了一个被认为是不可能的提示难题。我们让AI做了一些它原本不应该做的事情,并克服了大语言模型的数值盲点。
最终,我让ChatGPT在固定的字数限制内工作。通过单词计数、Memory设置、代码解释器、分段和1%的容差,我们自由发挥的聊天机器人已经变成了一个字数计数的巫师。现在您可以放心,因为ChatGPT会像在乎一样计数。