我们创建了GPT Web App Generator,它允许您简要描述您想要创建的Web应用程序,然后在几分钟内,一个完整的全栈代码库,使用React、Node.js、Prisma和Wasp编写,将在您面前生成,并可供下载和本地运行!
我们将其作为一个实验开始,看看我们能否使用GPT在我们正在开发的开源JS Web应用程序框架Wasp中生成全栈Web应用程序。自从我们推出以来,仅仅几天内就生成了超过3000个应用程序!
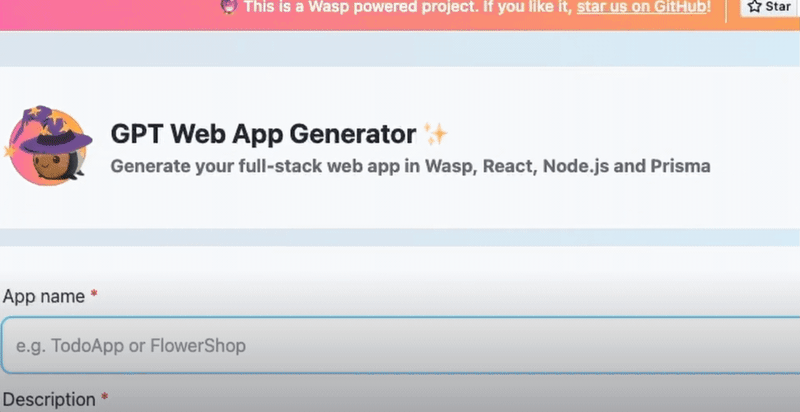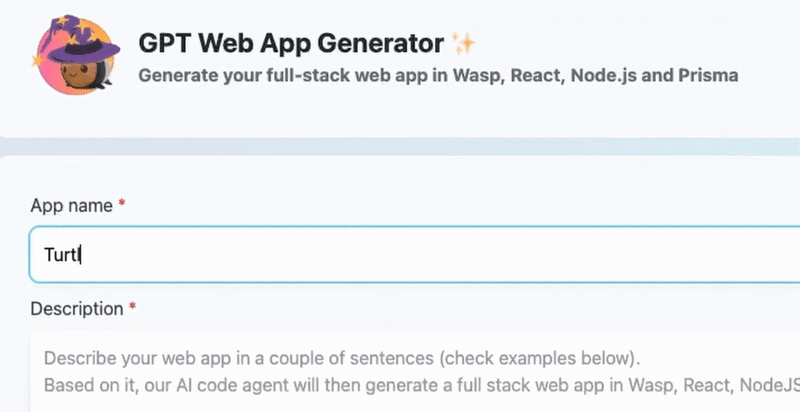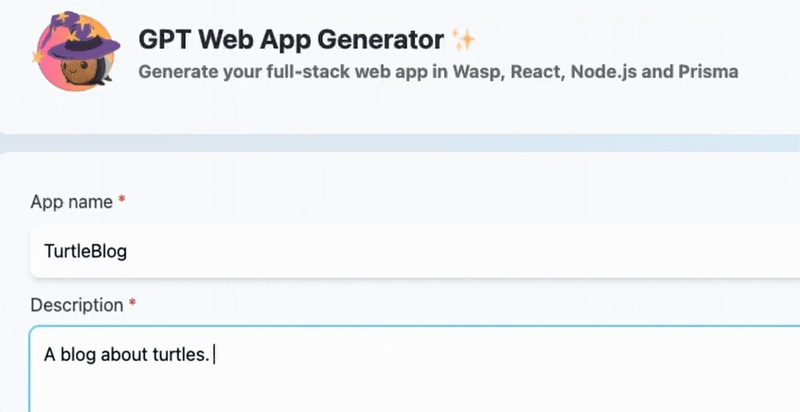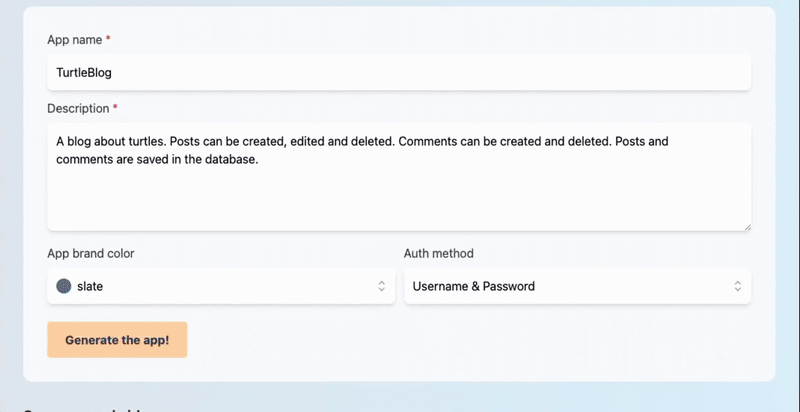
请查看这篇博文,了解GPT Web App Generator的实际操作,包括一分钟的演示视频、几个示例应用程序,并了解更多关于我们未来计划的信息。或者,您可以在https://magic-app-generator.wasp-lang.dev/上自行尝试!
在这篇博文中,我们将探讨创建GPT Web App Generator的技术方面:我们使用的技术、我们如何设计我们的提示、我们遇到的挑战以及我们做出的选择!(从这里开始,我们将只称其为“生成器”或在谈论后端时称其为“代码代理”)
此外,生成器背后的所有代码都是开源的:Web应用程序,GPT代码代理。
它的工作效果如何🤔?
首先,让我们快速解释一下我们最终得到的结果以及它的性能。
我们的生成器的输入是应用程序名称、应用程序描述(自由格式文本)以及一些简单的选项,例如主要应用程序颜色、温度、身份验证方法和要使用的GPT模型。
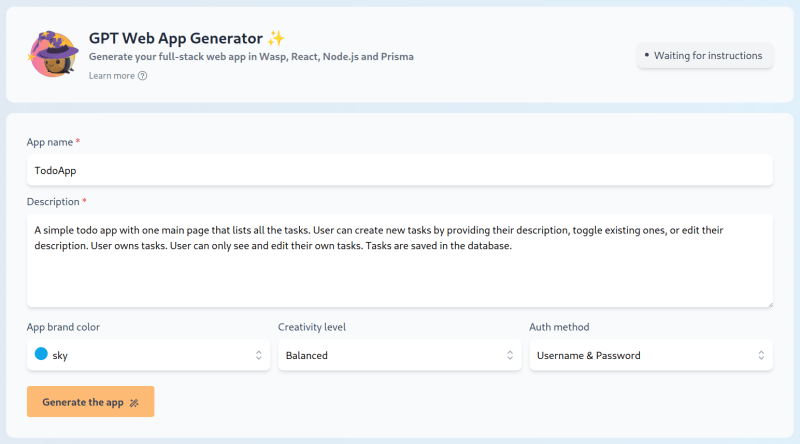
作为输出,生成器会生成一个完整的全栈Web应用程序的JS代码库:前端、后端和数据库。前端使用React + Tailwind,后端使用NodeJS和Express,与数据库的交互使用Prisma。所有这些都与Wasp框架连接在一起。
您可以在这里查看生成的代码库的示例:https://magic-app-generator.wasp-lang.dev/result/07ed440a-3155-4969-b3f5-2031fb1f622f。
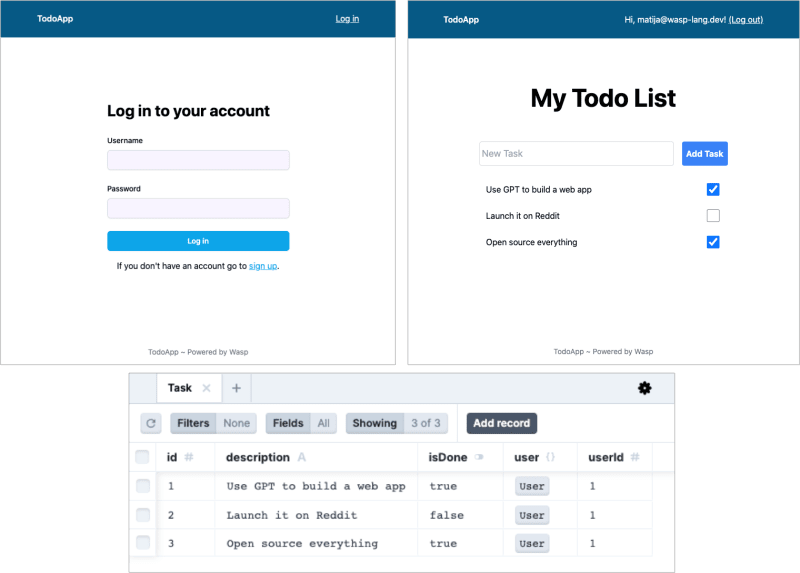
生成器会尽力生成可以立即运行的代码→您可以将其下载到您的计算机并运行。对于较简单的应用程序,例如TodoApp或MyPlants,它通常会生成没有错误的代码,您可以立即运行它们。
这是一个生成的TodoApp的示例:
对于稍微复杂一些的应用程序,例如带有帖子和评论的博客,它仍然会生成一个合理的代码库,但可能会有一些错误。对于更复杂的应用程序,它通常无法完全跟进,而是在某个复杂度水平停止,并使用TODO填充其余部分或省略功能,因此它有点像被要求的模型的简化版本。总体而言,它优化了生成CRUD业务Web应用程序。
这使得它成为一个很好的工具,可以通过坚实的原型来启动您的下一个Web应用程序项目,甚至可以即时生成可工作的简单应用程序!
它是如何工作的⚙️?
当我们开始构建生成器时,我们给自己设定了以下目标:
-
我们必须能够在几周内构建它
-
它必须相对容易在未来维护
-
它需要快速且廉价地生成应用程序(几分钟,< $1)
-
生成的应用程序应尽可能少出错
因此,为了保持简单,我们没有进行任何LLM级别的工程或微调,而是只使用OpenAI API(具体是GPT3.5和GPT4)来生成应用程序的不同部分,同时在每个时刻给予它正确的上下文(文档片段、示例、指南等)。为了确保生成的应用程序的连贯性和质量,我们没有给予我们的代码代理太多的自由,而是通过逐步引导它来生成应用程序。
作为第零步,我们确定性地生成一些代码文件,不使用GPT,只基于用户选择的选项(主要颜色、身份验证方法):这些文件包括项目的一些配置文件、一些基本的全局CSS和一些身份验证逻辑。您可以在这里查看此逻辑(我们称之为“骨架”文件):Github上的代码。
然后,代码代理接管!
代码代理在3个主要阶段中完成其工作:
-
规划📝
-
生成🏭
-
修复🔧
由于GPT4比GPT3.5慢得多且昂贵得多(每分钟的令牌数量限制较低,每分钟的请求数量限制也较低),我们仅在规划阶段使用GPT4,因为这是关键步骤,然后在此之后,我们使用GPT3.5进行其他步骤。
至于每个应用程序的成本💸:一个应用程序通常会消耗从25k到60k个令牌,这大约是**$0.1到$0.2每个应用程序,当我们混合使用GPT4和GPT3.5时。如果我们只使用GPT4运行它,那么成本是10倍,即$1到$2**。
🎶 插曲:OpenAI Chat Completions API的简短解释
OpenAI API提供了不同的服务,但我们只使用了其中一个:“chat completions”。
API本身实际上非常简单:您发送一个对话,然后从GPT获得一个响应。
对话只是一个消息列表,其中每个消息都有内容和角色,其中角色指定谁“说”了该内容→是“user”(您)还是“assistant”(GPT)。
需要注意的重要事项是没有状态/内存的概念:每个API调用都是完全独立的,GPT只知道您在那一刻提供给它的对话!
如果您想知道ChatGPT(使用后台的Web应用程序)如何在没有内存的情况下工作→好吧,每次您写一条消息时,到目前为止的整个对话都会被重新发送!这里还有一些额外的智能机制在起作用,但在其核心,就是这样。
第一步:规划📝
Wasp应用程序由实体(Prisma数据模型)、操作(NodeJS查询和操作)和页面(React)组成。
一旦给定应用程序的描述和标题,代码代理首先生成一个计划:它是一个由实体、操作(查询和操作)和页面组成的列表,构成应用程序。所以有点像应用程序的初始草稿。它还没有生成代码→相反,它提供它们的名称和一些其他细节,包括它们应该如何行为的简短描述。
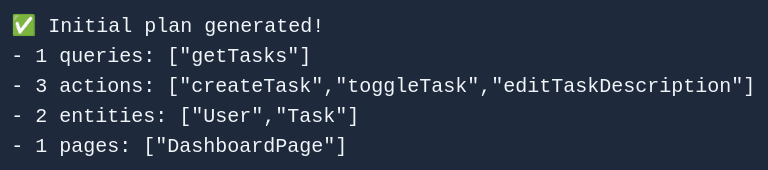
这是通过向GPT发送一个API请求完成的,其中提示包括以下内容:
-
关于Wasp框架的简短信息+一些Wasp代码的示例。
-
我们解释我们想要生成计划,解释它是什么,以及它如何作为JSON表示,通过描述其模式。
-
我们提供一些计划的示例,以JSON表示。
-
我们希望它遵循的一些规则和指南(例如“计划应该至少有1个页面”,“确保生成一个User实体”)。
-
指令仅将计划作为有效的JSON响应返回,不返回其他文本。
-
应用程序的名称和描述(由用户提供)。
您可以在这里查看我们如何生成这样的提示的代码。
此外,这是一个链接到一个gist,其中包含一个TodoApp的实际示例。
然后,GPT会以JSON的形式(希望如此)回复,我们解析它,就有了一个计划!我们将在接下来的步骤中使用这个计划,来驱动我们生成应用程序的其他部分。请注意,GPT有时会向JSON响应添加文本或返回无效的JSON,因此我们内置了一些简单的方法来克服这些问题,我们将在后面详细解释。
🎶 插曲:常见的提示设计
我们刚刚描述的用于生成计划的提示设计实际上与其他步骤(例如生成和修复步骤以及它们各自的子步骤)非常相似,因此让我们涵盖这些共同点。
我们使用的所有提示或多或少都遵循相同的基本结构:
-
一般上下文:关于Wasp框架是什么的简短信息,以及无论我们现在生成什么(例如NodeJS代码的示例或React代码的示例)的文档片段(如果需要的话)。
-
项目上下文:我们在前面的步骤中生成的与当前步骤相关的内容。- 我们现在想要生成的内容的说明+其JSON模式+示例JSON响应。
-
规则和指南:这是一个很好的地方,可以警告它常犯的错误,或给予一些建议,并强调需要发生的事情和不应发生的事情。
-
指示仅以有效的JSON格式进行回复,不要包含其他文本。
-
原始用户提示:应用程序名称和描述(由用户提供)。
我们将原始用户提示放在最后,因为在它看到原始用户提示的开始之后(我们有一个特殊的标题),我们可以在系统消息中告诉GPT,它需要将其后的所有内容视为应用程序描述,而不是关于要做什么的指示→这样我们试图防止潜在的提示注入。
第二步:生成 🏭
在生成计划后,生成器逐步执行计划,并要求GPT生成每个Web应用程序部分,同时为其提供文档、示例和指南。每次生成一个Web应用程序部分时,生成器将其适应整个应用程序。这是我们大部分工作的地方:在正确的时刻为GPT提供正确的信息。

在我们的情况下,我们为计划中的所有操作(操作和查询:Node.js代码)以及计划中的所有页面(React代码)执行此操作,每个操作一个提示。因此,如果我们有2个查询、3个操作和2个页面,那将是2+3+2 = 7个GPT提示/请求。提示的设计如前所述。
在生成操作时,我们向GPT提供有关先前生成的实体的信息,而在生成页面时,我们向GPT提供有关先前生成的实体和操作的信息。
第三步:修复 🔧
最后,生成器尽力修复GPT可能先前引入的任何错误。GPT喜欢修复它先前生成的东西→如果你首先要求它生成一些代码,然后告诉它修复它,它通常会改进它!
为了进一步增强这个过程,我们不仅要求它修复先前的代码,还向它提供了关于要注意的内容的指示,例如我们注意到它经常犯的常见错误类型,并指出我们自己能够检测到的任何特定错误。
关于检测要报告给GPT的错误,理想情况下,你会有一个完整的REPL→这意味着通过解释器/编译器运行生成的代码,然后发送给它进行修复,依此类推,直到所有问题都解决。
在我们的情况下,我们无法在规定的时间限制内通过TypeScript编译器运行整个项目,但我们使用了一些更简单的静态分析工具,如Wasp的编译器(用于.wasp文件)和prisma format用于Prisma模型模式,并将它们发送给GPT进行修复。我们还编写了一些我们自己的简单启发式算法,能够检测到一些常见错误。
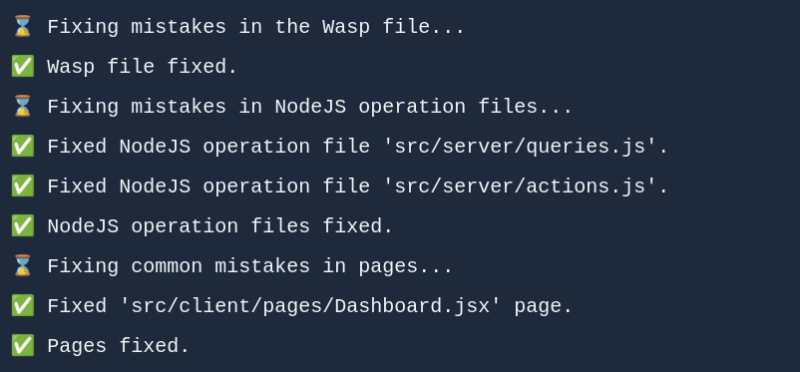
在提示中,我们通常会重复在生成步骤中提供的相同指南,同时添加一些额外的指针,指出常见错误,这通常有助于修复之前遗漏的内容。但是,通常不是所有的内容,而是仍然会有一些问题。有些事情我们无法让它始终修复,例如Wasp特定的JS导入,无论我们如何强调它需要如何处理它们,它都会继续搞砸。即使是GPT4在这种情况下也不完美。对于这种情况,如果可能的话,我们最终编写了我们自己的启发式算法来修复这些错误(修复JS导入)。
我们尝试/学到的东西
解释 💬
我们尝试告诉GPT解释它在修复错误时所做的事情:它将修复哪些错误以及它修复了哪些错误,因为我们读到这样做可以帮助,但是我们没有看到它的性能有明显的改善。
测试 🧪
测试代码代理的性能很困难。
在我们的情况下,我们的代码代理生成一个新应用程序需要几分钟的时间,并且您需要直接使用OpenAI API运行测试。此外,由于结果是非确定性的,很难确定输出是否受到您所做更改的影响。
最后,评估输出本身可能很困难(特别是在我们的情况下,当它是一个完整的全栈Web应用程序时)。
理想情况下,我们将建立一个系统,可以仅运行整个生成过程的部分,并且可以自动运行特定部分多次,每次都使用不同的参数集(包括不同的提示,但也包括模型类型(gpt4 vs gpt3.5)、温度等参数),以便比较每个参数集的性能。
评估性能也最好是自动化的,例如我们将计算编译过程中的错误数量和/或评估应用程序设计的质量→但这也相当困难。
不幸的是,我们没有时间建立这样的系统,因此我们主要是手动进行测试,这是相当主观和容易受到随机性的影响,并且只对具有相当大影响的更改有效,而对于那些较小的优化,您无法真正检测到。
上下文与智能 🧠
当我们开始处理生成器时,我们认为上下文的大小将是主要问题。然而,最后我们并没有遇到上下文的任何问题→我们想要指定的大部分内容都可以适应2k到最大4k个令牌,而GPT3.5的上下文可以达到16k!
相反,我们在“智能”方面遇到了更大的问题→这意味着GPT不会遵循我们明确告诉它要遵循的规则,或者会做我们明确禁止它做的事情。GPT4在遵循规则方面表现得比GPT3.5更好,但即使GPT4仍然会一遍又一遍地犯一些错误,并忘记特定的规则(即使有足够的上下文)。在“修复”步骤中,这有助于解决这个问题:我们会在那里重复规则,GPT会更多地遵守这些规则,但通常仍然不是所有规则。
处理JSON作为响应 📋
如本文前面提到的,在与GPT的所有交互中,我们总是要求它将响应作为JSON返回,为此我们指定了模式并给出了一些示例。
然而,GPT仍然不总是遵循该规则,有时会在JSON周围添加一些文本,或者在格式化JSON时出错。
我们处理这个问题的方法有两个简单的修复:
-
在接收到JSON后,我们会删除从开头到我们遇到
{之前的所有字符,以及从结尾到我们遇到}之前的所有字符。这是一个简单的启发式算法,但在实践中非常有效,因为GPT通常不会在该文本中包含任何{或}。 -
如果我们无法解析JSON,我们会将其再次发送给GPT进行修复。我们包括先前的提示及其最后的答案(包含无效的JSON),并添加修复指示+我们收到的JSON解析错误。我们重复这个过程几次,直到它正确为止(或者直到我们放弃)。
实际上,这两种方法在我们的情况下几乎可以处理99%的无效JSON。
注意:在我们实施我们的代码代理时,OpenAI发布了GPT的新功能“functions”,它基本上是一种机制,使GPT能够以结构化的JSON形式响应,遵循您的描述的模式。因此,使用“functions”来执行此操作可能更合理,但我们已经使这个方法运行良好,所以我们坚持使用它。
处理服务中的中断 🚧
我们直接调用OpenAI API,因此我们很快就注意到通常会返回503 - 服务不可用 - 尤其是在高峰时段(例如中欧时间下午3点)。
因此,建议使用某种重试机制,最好是指数回退,使您的代码代理对此服务中的随机中断以及潜在的速率限制具有冗余性。我们选择了指数回退的重试机制,效果很好。
温度 🌡️
温度决定GPT的创造力,但它越创造性,就越不“稳定”。它会产生更多的幻觉,并且更难遵循规则。 温度是一个从0到2的数字,默认值为1。
我们尝试了不同的值,并得出以下结论:
-
≥ 1.5 会偶尔产生一些非常愚蠢的结果,其中包含随机字符串。
-
≥ 1.0,< 1.5 还可以,但会引入太多错误。
-
≥ 0.7,< 1.0 是最佳选择→足够有创造力,同时错误不多。
-
≤ 0.7 的性能与稍高的值相似,但可能稍微缺乏创造力。
也就是说,我认为我们没有充分测试低于0.7的值,这是我们可以进一步研究的内容。我们最终将0.7作为我们的默认值,除了用于修复的提示,我们使用了较低的0.5,因为在修复时,0.7的值似乎会改变太多东西(过于有创造性)。我们的逻辑是:在编写代码的第一个版本时,让它有创造性,然后在修复时稍微保守一些。再次强调,我们还没有对所有这些进行足够的测试,所以我希望我们能更多地探索这个领域。
未来展望 🔮
虽然我们对我们在如此短的时间内所构建的性能感到印象深刻,但我们也希望尝试许多不同的想法来进一步改进它。在这个发展如此迅速的生态系统中,还有许多未被探索的领域,很难达到您感觉已经探索了所有选项并找到了最佳解决方案的程度。
以下是一些未来尝试的激动人心的想法:
-
我们对我们的代码代理生成的代码设置了很多限制,以确保其足够好用:我们不允许它创建辅助文件,不允许包含npm依赖项,不允许使用TypeScript,不允许使用高级的Wasp功能等等。我们希望取消这些限制,从而允许创建更复杂和强大的应用程序。
-
而不是让我们的代码代理一次性完成所有工作,我们可以在生成应用程序的第一个版本后允许用户与其进行交互:例如提供额外的提示来修复问题,添加一些功能到应用程序中,以不同的方式执行某些操作等等。最困难的是确定在哪个时刻向GPT提供哪些上下文,并相应地设计体验,但我相信这是可行的,并且它将使生成器的可用性提升到一个新的水平。另一个选择是允许在初始生成步骤之间进行干预,例如,在生成计划后,允许用户通过向GPT提供额外的指令来调整它。
-
找到一个适合我们目的的开源LLM,并对其进行微调/预训练。如果我们能教它更多关于Wasp和我们使用的技术的知识,这样我们就不必在每个提示中都包含这些信息,我们可以节省一些上下文,并使LLM更专注于我们在提示中指定的规则和指南。我们还可以自己托管它,对成本和速率限制有更多控制权。
-
对代码代理采取不同的方法:让它更自由。与其如此小心地引导它,我们可以教它关于它可以请求的所有不同事物(请求文档,请求示例,请求生成应用程序的某个特定部分,请求查看某个已生成的应用程序部分等等),并让它更自由地引导自己。它可以不断生成计划,执行计划,更新计划,直到达到平衡状态。这种方法可能提供更大的灵活性,并且可能能够生成更复杂的应用程序,但它也需要更多的标记和强大的LLM来驱动它→我相信随着LLM变得更有能力,这种方法将变得更可行。