经过三个月的试验与错误,Georgi Gerganov 和 Ghorbani Asghar 为我们找到了既简单又优雅的解决方案。只需五分钟,就可以让一个口袋大小的大语言模型在你的安卓或苹果手机上运行。

我终于做到了!不过说实话,我几乎没做什么。我只是时刻保持警觉,捕捉到这个消息的第一个信号。
在这篇文章中,我将向您展示如何在没有网络连接的情况下,在您的安卓(或iPhone)手机上本地运行一个小型语言模型(例如 Gemma2–2B 或 Qwen2.5–1.5B)。
几个月前,我开始寻找一个方法,让大语言模型在我的安卓手机上本地运行。结果遇到了很多失败...
当时,唯一活跃的项目是(至今仍是)mlc-llm 及其平行项目 web-llm:但部署过程简直是一场噩梦!
不过,后来我的超级英雄 Gerogi Gerganov 发布了一则令人惊叹的消息:
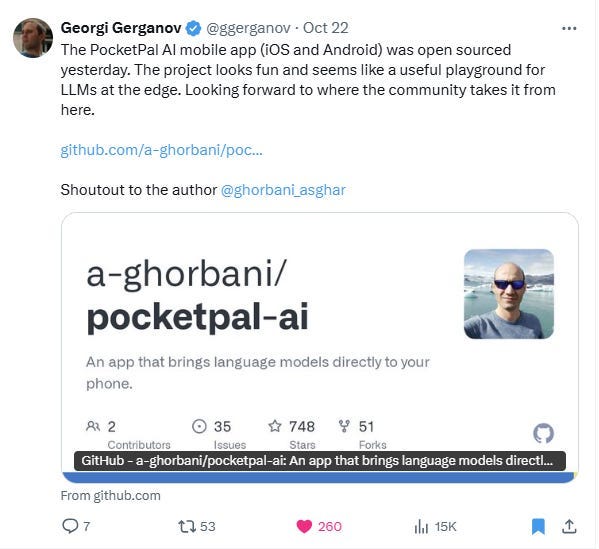
我称他为超级英雄,因为在我看来,Gerganov 是过去两年里真正的生成式 AI 创新者。通过 Llama.cpp 项目,他让不可能成为可能。
任何有 CPU 的人(甚至是 Raspberry Pi)都可以本地运行生成式 AI!
我没有浪费时间,立刻进行了尝试。现在我将在这里教你如何自己动手实现。
注意:我使用的是非常旧的安卓手机,所以它也应该能在你的手机上运行。我的测试手机都是安卓手机,如下图所示。相信我,如果我能在这上面运行 AI,那么你也可以做到!
在您的手机上运行小型语言模型所需的一切
事实上 Asghar Ghorbani 的 GitHub 仓库 就是你需要的一切,就是这么简单。他开发了两个应用程序,一个是 安卓版,一个是iOS版,你可以直接在各自的应用商店下载。
所以可以说,PocketPal 就是你所需要的
PocketPal 的应用商店...
他在所有细节上都做得很好,包括你开箱即用的两个惊人功能:
-
你可以直接从应用中下载 LLM(小型模型)
-
你可以添加你自己格式为 GGUF 的小型语言模型
首先,从你的应用商店下载并安装这个应用(在我的案例中是 Google Play 商店)。之后,打开它,开始获取和配置模型。
PocketPal AI 预配置了一些流行的小型语言模型:
-
Danube 2 和 3
-
Phi
-
Gemma 2
-
Qwen
模型需在使用前下载。你可以直接从应用下载并使用这些模型,还可以加载任何其他 GGUF 格式的模型!稍后我将解释如何操作。对于 iOS 用户,我不确定如何做到这一点。请按照以下步骤操作:
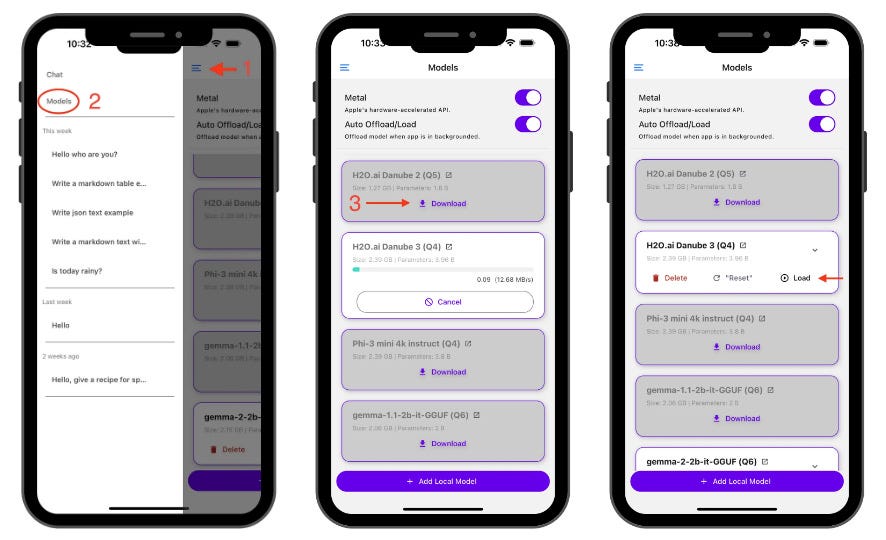
下载一个模型
-
点击汉堡菜单
-
导航到“模型”页面
-
选择你想要的模型并点击下载
加载一个模型
下载后,点击 加载 将模型加载到内存中。现在你可以开始聊天了!
如何聊天和定制本地模型
从应用直接下载的模型已经配置好所有正确的设置。没错……在这里你也需要进行一些调整。
没什么好惊讶的,PocketPal 是基于 llama.cpp 构建的!所以每当你想使用另一个模型时,你需要检查使用 llama.cpp 库时需要的一些相同参数。
首先,我从官方 Qwen Hugging Face 仓库下载了 qwen2–0.5b-instruct-q8_0.gguf,并上传到我的手机下载目录(你也可以直接下载到那里)。我选择了 q8 格式,因为对于小参数模型,准确性不能降低。对于参数高达 2B 的模型,你也可以使用 q5_m 量化,对于 3B 模型,甚至 q4 也是可以的。
现在你可以点击 + Local Model 并浏览下载的文件。你可能尝试加载并立即开始聊天,但有些不需要的 token 会打印在聊天框中。
与我们在 llama-cpp-python 中配置模型超参数的方式类似,在这里我们必须设置一些基本参数:
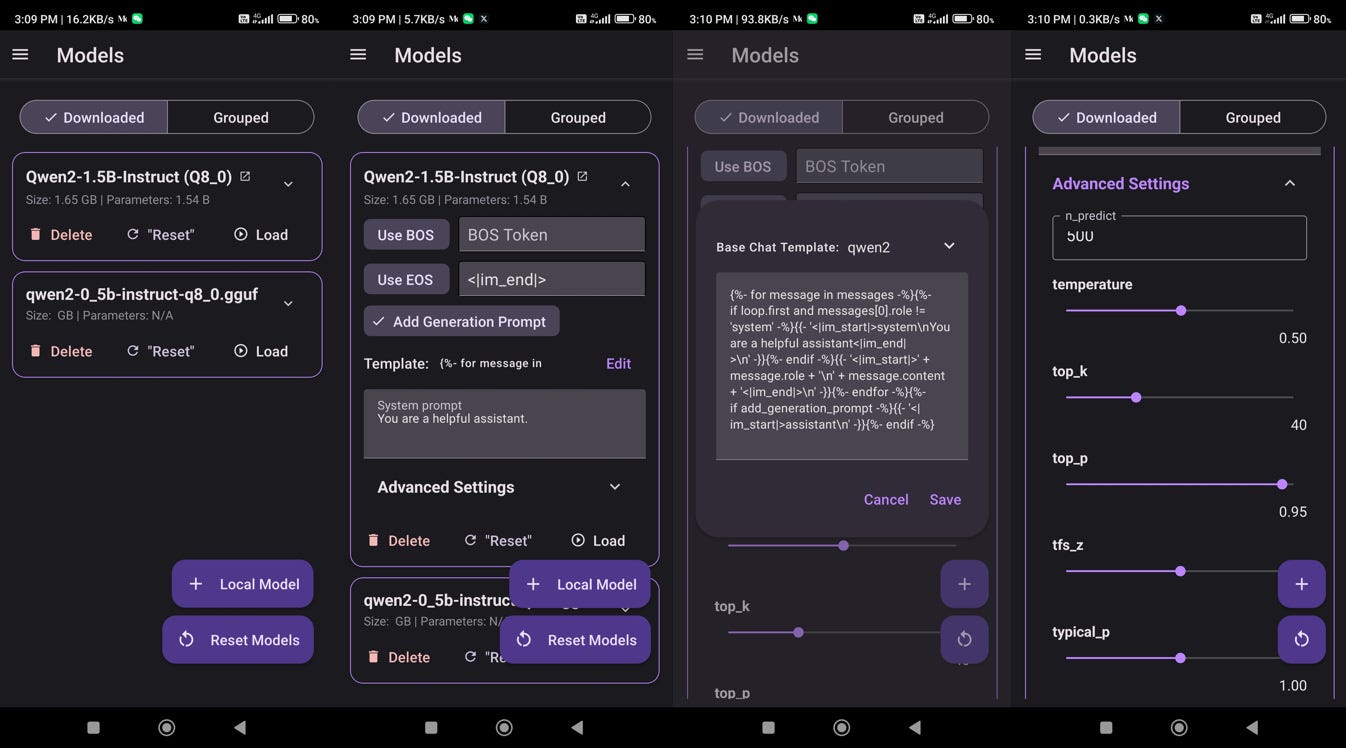
最后在高级设置中,你还需要指定 repeat _penalty 和 stop。
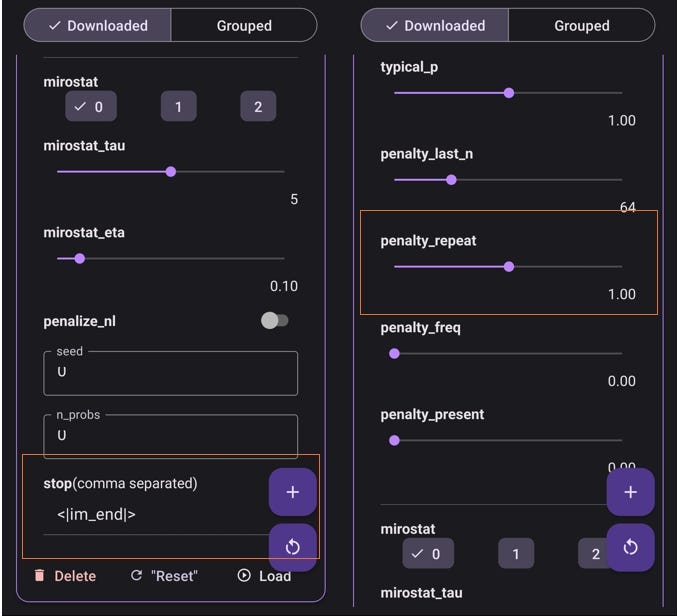
使用 Qwen2–0.5b 非常简单:实际上,我从模型库中已经提供的 qwen2–1.5b-instruct 模板中复制了设置。
你可以通过在终端中激活 venv,自己找到这些信息。
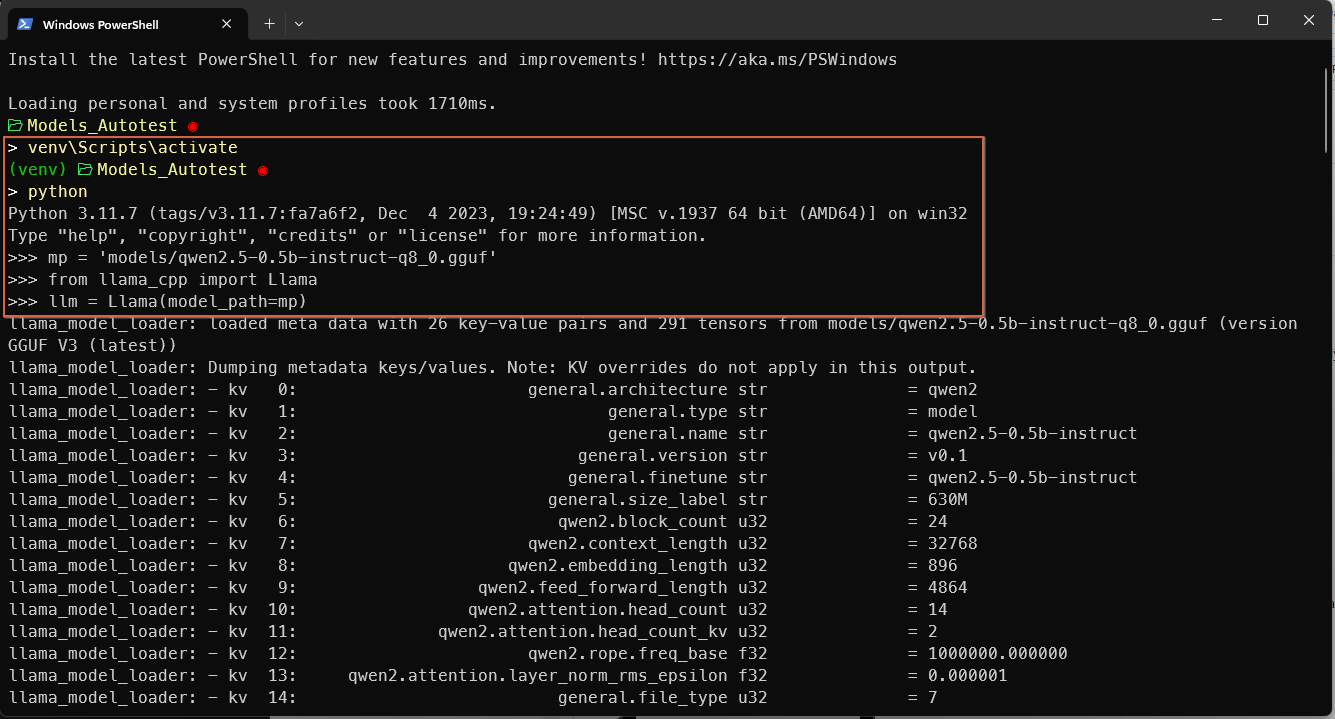
当你加载模型时,很多元描述符会被加载并打印出来。其中你可以找到 EOS token(也是一个 stop),上下文长度甚至还有聊天模板
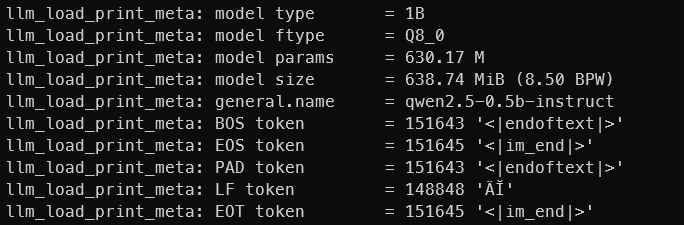
这里是 tokenizer.chat template:
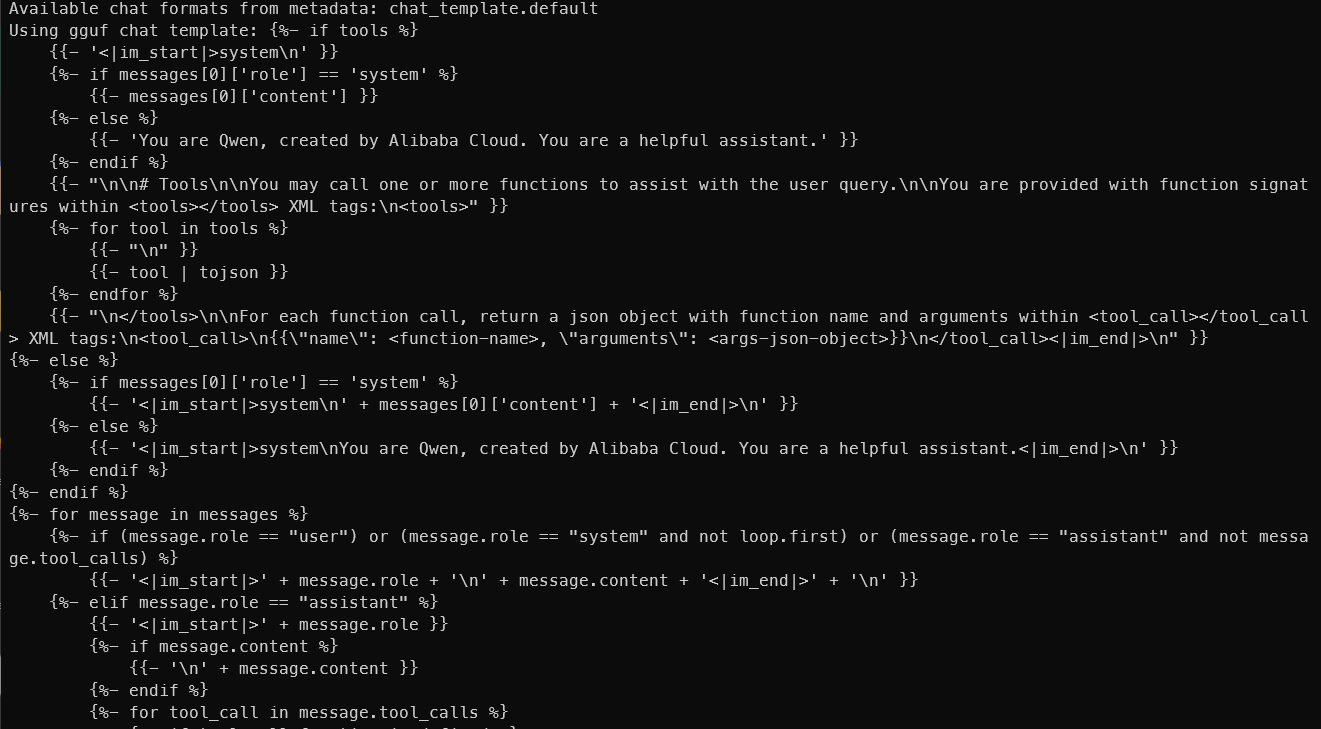
设置完上述参数后,你可以开始享受在手机上由本地 AI 驱动的聊天体验。
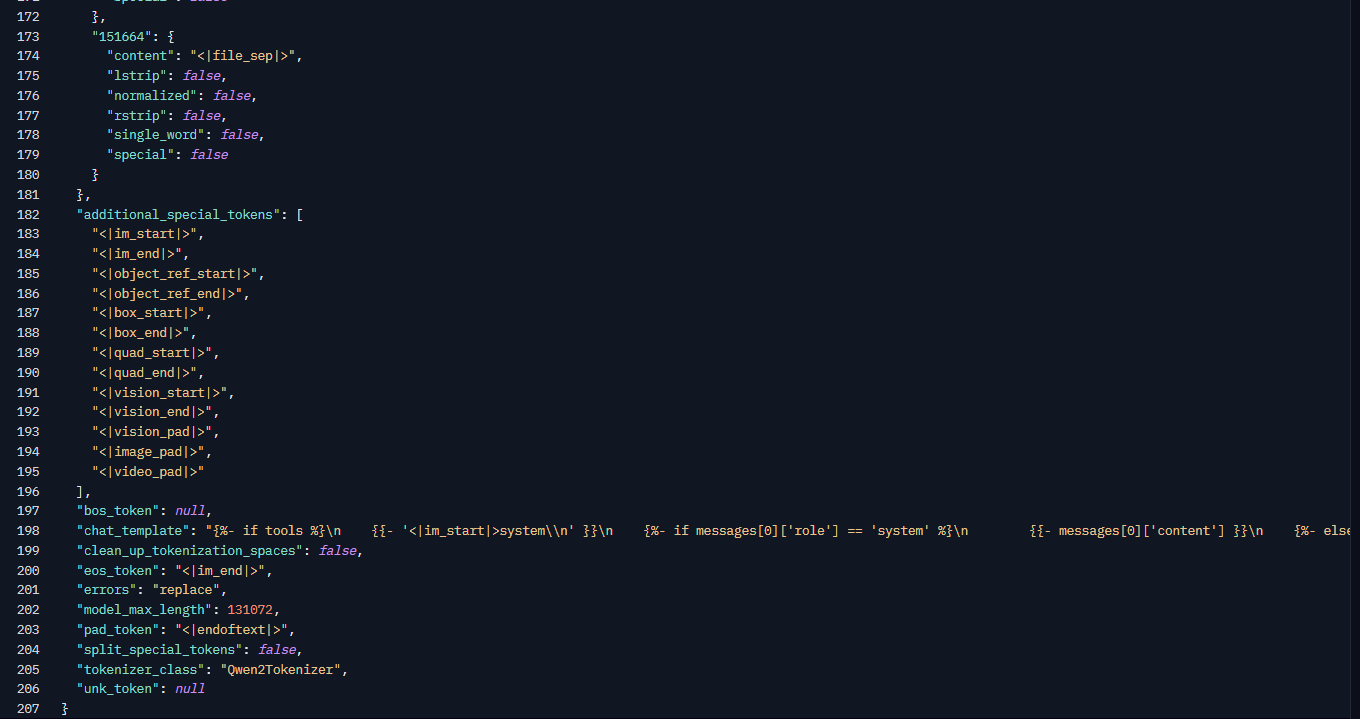
注意:你可以随时查看原始模型仓库,并查找 tokenizer_config.json 文件以获取聊天模板格式。这里是一个例子:
一些建议
在我最新的手机上,我没能从模型目录加载 Gemma-2B。大多数模型都是 q8 精度,这对于准确性来说是好的,但对 RAM 是一个不小的负担。
评估你是否有足够计算能力的最简单方法是一个简单的数学计算:
10 亿参数 = 1GB * 4 显存
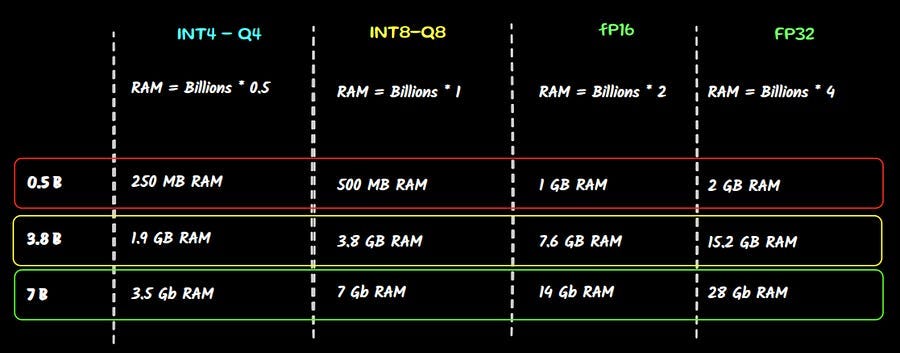
如果我们以一台没有独立显卡、内存为 16GB 的好笔记本电脑为例,即使在全精度(FP32)下也无法运行 3.8B 版本的模型,甚至在半精度(FP16)下运行 7B 模型也无法实现
所以从目录中你可以合理地假设所有参数不超过 1.5B 的模型都能使用,不会有太多问题。对于更大的模型,我建议下载较低量化权重的版本。
结论
Asghar Ghorbani 的 GitHub 仓库 是个真正的宝藏。到目前为止,还没有其他简单快速的解决方案可以让生成式 AI 模型完全本地运行在你的手机上。有一个例外,那就是已经存在一段时间,由 H2O.ai 开发的 Danube LLM 系列。
我将在建议文章部分留下一些参考资料,如果你想了解更多关于这方面的信息。
目前,PockePal-ai 是唯一一个能在手机上运行大语言模型的好选择,你可以从优秀的目录中选择你的生成式 AI 模型,甚至是你自己下载的本地模型格式 GGUF。