随着自动化内容创作工具如Dubdup和Canva的兴起,关于如何轻松生成成千上万的YouTube Shorts引起了广泛讨论。许多人宣传的内容包括“AI副业,每天赚XXX美元”或“无需露脸”:
受到这些宣传的吸引,我决定挑战使用最新的AI大语言模型(LLM)技术,如ChatGPT和Leonardo.ai,来完全自动化创建YouTube视频。我的目标是每天批量制作144个5到10分钟的视频,不依赖第三方工具。以下是我如何实现这一目标的详细说明,包括遇到的见解和挑战。
流程概述
在本文中,我将详细介绍如何创建一个脚本来自动化生成YouTube视频的整个过程。从生成视频主题到创建缩略图,这个端到端的解决方案展示了AI在内容创作中的巨大潜力。以下是关键步骤:
- 生成主题:使用ChatGPT推荐适合自我激励YouTube频道的有吸引力且相关的主题。
- 生成YouTube脚本:创建详细且引人入胜的视频脚本,包括介绍、主要观点、个人故事和激励性的结论。同时去除不必要的字符,提高文字转语音(TTS)的质量。
- 生成Leonardo提示词:为Leonardo.ai生成与视频内容相关的图像提示词。随后通过Leonardo.ai的运动生成API进行放大并动画化,参考其文档。
- 文字转语音转换:使用Google Cloud的Text-to-Speech API将YouTube脚本转换为高质量的语音解说,并配置为纪录片风格。
- 搜索和下载音乐:起初我尝试使用Pixabay的API搜索音乐,但由于限制,改为本地下载免版权音乐,或者从YouTube Studio下载音乐。
- 视频合成:将生成的视频片段、背景音乐和解说音频结合成一个完整视频,添加视频片段之间的渐变效果和字幕。
- 创建YouTube缩略图:使用视频中的帧并添加视频标题文本,生成一个视觉吸引力强的缩略图。
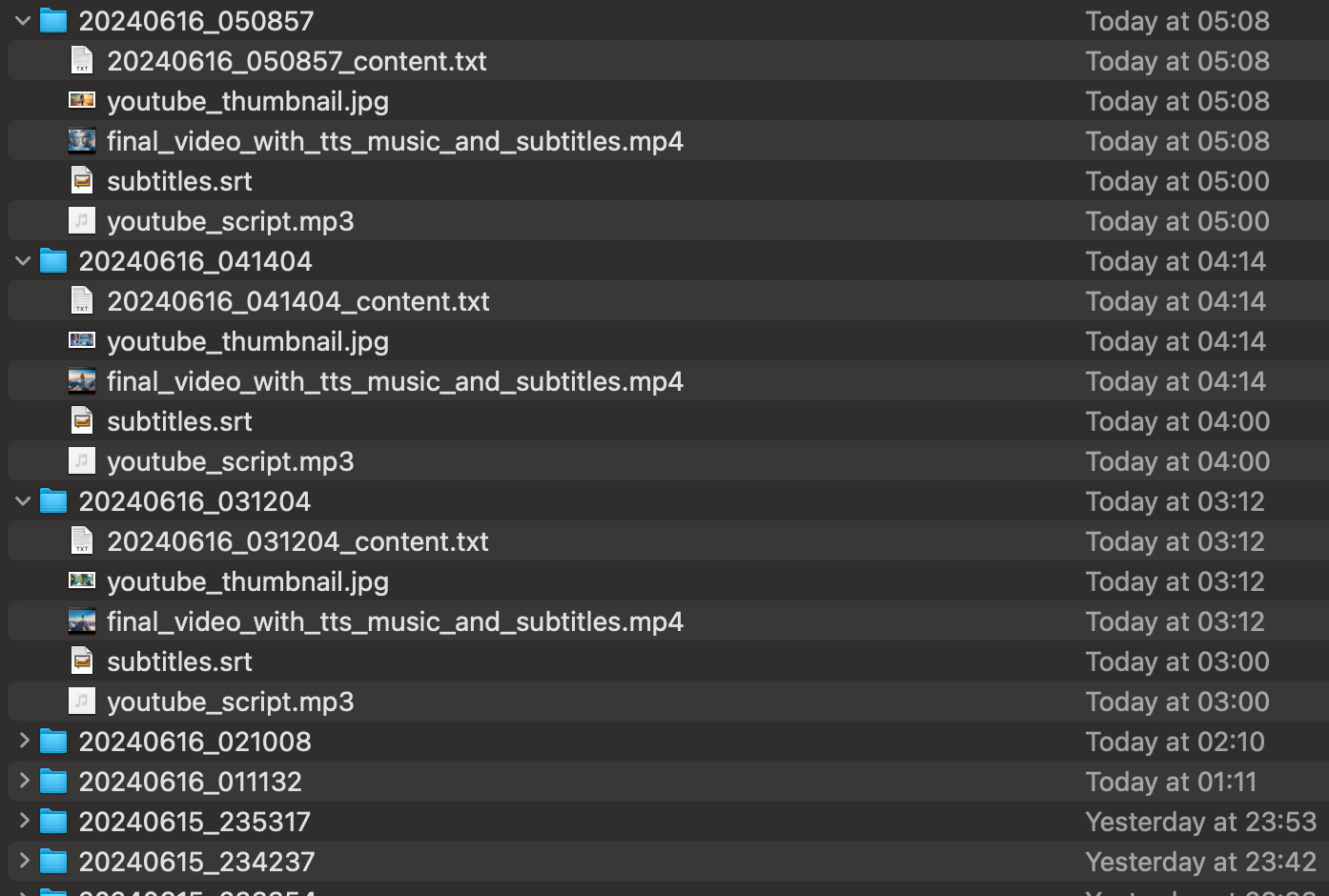
- 保存和整理内容:将所有生成的内容,包括视频、缩略图和脚本,保存到结构化的文件夹系统中。
- 自动化调度:使用Python的
schedule库多次运行脚本,实现持续的视频生成。
不过,通过YouTube API上传视频需要额外的验证,因此我选择手动上传自动生成的视频。在ChatGPT的帮助下,我仅用了2小时就完成了这个项目的代码编写。下面是我如何每天生成144个视频的详细指南,每个视频制作大约只需10分钟。
请求和调整总结
- 初始请求:我希望创建一个专注于成功人士心态和动机的YouTube频道。
- 脚本生成:我需要一个脚本生成器,能生成流畅且没有生硬语句的内容,删除多余的字符如“主持人:”以确保文字转语音的顺畅。
- 图像和视频生成:使用Leonardo.ai生成图像并进行放大,然后将其转换为视频。此过程参考了Leonardo.ai的API文档。
- 文字转语音转换:我使用Google Cloud Text-to-Speech API配置了纪录片风格的解说,Google提供免费配额,新用户可获得300美元的免费额度。
- 字幕生成:使用OpenAI的Whisper API生成字幕。
- 背景音乐和过渡效果:起初我使用Pixabay API获取背景音乐,但后来改为下载免版权音乐或从YouTube Studio获取。
- 缩略图创建:使用Python Imaging Library(PIL)生成缩略图。
- 保存和上传内容:将所有生成的内容保存到结构化的文件夹中,并上传至YouTube。
- 上传视频到YouTube:使用YouTube数据API上传所有生成的视频,并自动设置标题、描述和缩略图。
- 脚本调度:使用Python的
schedule库定时运行脚本。
与ChatGPT的创意构思
整个流程与ChatGPT的合作简单而高效。最初,我要求ChatGPT为自我提升和激励内容的YouTube频道生成创意。然后,通过API生成详细的视频脚本。接着,我要求ChatGPT为Leonardo.ai生成提示词,用于创建符合视频主题的图像。
我还使用了ChatGPT推荐的Python API处理文字转语音(TTS)和视频编辑。虽然ChatGPT推荐了内置的TTS库gtts,但我选择了Google Cloud Text-to-Speech API,因为该API提供更自然的语音合成效果。
此外,我要求ChatGPT生成和放大图像的代码,将图像转换为视频,并在视频中应用
与语音时长匹配的渐变效果,还加入了免版权背景音乐和字幕。为了简化整个过程,我让脚本保存所有生成的内容,并使用Python调度库定期运行该脚本。
克服挑战与调试
开发过程中,我需要进行一些调试。尽管ChatGPT能够理解我的请求并生成必要的代码,但最初的代码与最新的OpenAI Python库版本不兼容。不过,使用openai migrate命令解决了这个问题。
ChatGPT最初对Leonardo.ai的使用方法理解有误,但通过参考Leonardo.ai的API文档,我成功指导ChatGPT生成了适合的代码。与ChatGPT合作使任务完成时间从预期的6小时缩短到了2小时。
背景音乐的实验
在测试阶段,我发现Pixabay API不支持下载背景音乐。于是,我尝试通过Selenium直接下载,但由于需要ChromeDriver和无头浏览器,操作过于繁琐。最终,我手动下载了免版权的激励音乐,以避免Pixabay内容在YouTube上产生版权问题。
详细操作步骤
1. 生成主题
第一步是使用OpenAI的ChatGPT为YouTube视频生成一个吸引人的主题。这样可以确保视频内容能够吸引寻求自我提升的观众。
def generate_topic():
prompt = "推荐一个适合自我激励YouTube频道的吸引人且有启发性的主题。"
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": prompt},
],
)
topic = response.choices[0].message.content.strip()
return topic
2. 生成YouTube脚本
有了主题后,我们生成一个详细的YouTube脚本。该脚本包含引人入胜的介绍、关键观点、个人故事和激励性的结论,并确保脚本中没有不必要的字符,从而提升文字转语音的效果。
def generate_youtube_script(topic):
prompt = (
f"为自我激励频道创建一个YouTube脚本。主题是'{topic}'。"
"脚本应包含介绍、主要部分的关键点、个人故事或实例,以及一个激励性的结论。"
"删除所有不必要的字符,如‘主持人:’。"
)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": prompt},
],
)
script = response.choices[0].message.content.strip()
script = re.sub(r"\[.*?\]", "", script)
script = re.sub(r"^\d+\.\s*", "", script, flags=re.MULTILINE)
script = re.sub(r"\bHost:\s*", "", script)
script = re.sub(r"[^a-zA-Z0-9\s,?.!]", "", script)
return script
3. 生成Leonardo提示词
使用Leonardo.ai的API生成视觉内容。该步骤生成高质量图像并将其放大,同时制作动态视频,使静态图像变得更加生动。
def generate_leonardo_prompts(youtube_script):
prompt = (
f"根据以下YouTube脚本生成10个适合Leonardo.ai的文本提示。"
f"每个提示描述一个成功人士的场景,且不包含人脸。"
f"以下是YouTube脚本:\n\n{youtube_script}"
)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": prompt},
],
)
prompts = response.choices[0].message.content.strip().split("\n")
prompts = [prompt for prompt in prompts if prompt.strip()]
prompts = [
f"{prompt}。此外,图像中不要包含任何文字,人物的脸不应朝向前方。"
for prompt in prompts
]
return prompts
4. 文字转语音转换
使用Google Cloud的Text-to-Speech API将脚本转换为语音解说,语音风格设定为纪录片风格,以确保解说听起来专业且吸引人。
def convert_text_to_speech(text, filename):
client = texttospeech.TextToSpeechClient.from_service_account_json(
"path/to/your/service_account.json"
)
synthesis_input = texttospeech.SynthesisInput(text=text)
voice = texttospeech.VoiceSelectionParams(
language_code="en-US",
name="en-US-Wavenet-B",
ssml_gender=texttospeech.SsmlVoiceGender.MALE,
)
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.MP3,
pitch=-2.0,
speaking_rate=0.9,
volume_gain_db=0.0,
)
response = client.synthesize_speech(
input=synthesis_input, voice=voice, audio_config=audio_config
)
with open("temp.mp3", "wb") as out:
out.write(response.audio_content)
print(f'音频已写入"temp.mp3"')
audio = AudioSegment.from_file("temp.mp3", format="mp3")
chunks = split_on_silence(audio, silence_thresh=-50, min_silence_len=500, keep_silence=250)
trimmed_audio = AudioSegment.empty()
for chunk in chunks:
trimmed_audio += chunk
trimmed_audio.export(filename, format="mp3")
os.remove("temp.mp3")
5. 搜索和下载音乐
为增强观众体验,我们为视频生成字幕,并使用OpenAI的Whisper API进行音频转录。
6. 音乐与TTS结合视频片段
最初,我尝试使用Pixabay API搜索激励音乐,但由于API不支持音乐搜索,我下载了免版权音乐,并将其添加到视频中,以提升情感效果。
def concatenate_video_with_music_and_tts(
video_path, music_folder, tts_path, srt_path, output_path, target_resolution=(720, 1280)
):
video_clip = VideoFileClip(video_path).resize(width=1920)
tts_clip = AudioFileClip(tts_path)
music_files = [
os.path.join(music_folder, file) for file in os.listdir(music_folder) if file.endswith(".mp3")
]
music_clips = [
AudioFileClip(music_path).fx(afx.volumex, 0.1) for music_path in random.sample(music_files, 40)
]
video_clip = vfx.loop(video_clip, duration=tts_clip.duration)
looped_music_clip = loop_audio_clips_sequentially(music_clips, tts_clip.duration)
composite_audio = CompositeAudioClip([tts_clip, looped_music_clip]).set_duration(tts_clip.duration)
subtitles = parse_srt(srt_path)
font_path = "NotoSans-Bold.ttf"
subtitle_clips = [
TextClip(
text, fontsize=60, color="white", font=font_path, stroke_color="black", stroke_width=1, size=video_clip.size
).set_position(("center", "center")).set_start(start).set_end(end)
for (start, end, text) in subtitles
]
video_with_subtitles = CompositeVideoClip([video_clip] + subtitle_clips)
final_video = video_with_subtitles.set_audio(composite_audio).fadein(2).fadeout(2)
final_video.write_videofile(output_path, codec="libx264", audio_codec="aac", fps=30, preset="ultrafast")
7. 创建YouTube缩略图
使用视频中的帧生成缩略图,并添加视频标题,使缩略图更具吸引力,确保视频在YouTube搜索结果中脱颖而出。
def create_youtube_thumbnail(video_path, text, output_path):
video_clip = VideoFileClip(video_path)
frame = video_clip.get_frame(video_clip.duration / 8)
image = Image.fromarray(frame)
draw = ImageDraw.Draw(image)
font_path = "NotoSans-Bold.ttf"
font = ImageFont.truetype(font_path, 50)
max_width = image.width - 100
lines = draw_text(draw, text, font, max_width)
total_height = sum(draw.textbbox((0, 0), line, font=font)[3] - draw.textbbox((0, 0), line, font=font)[1] for line in lines)
y_text = (image.height - total_height) // 2
for line in lines:
bbox = draw.textbbox((0, 0), line, font=font)
width = bbox[2] - bbox[0]
draw.text(((image.width - width) /
2, y_text), line, font=font, fill="white", stroke_width=1, stroke_fill="black")
y_text += bbox[3] - bbox[1] + 10
image.save(output_path)
8. 保存和整理内容
将生成的视频、缩略图、字幕和脚本保存到一个结构化文件夹中,方便后续上传至YouTube。
def save_to_folder(
topic, youtube_script, title, description, tts_filename, video_filename, srt_filename, thumbnail_filename
):
current_time = datetime.now().strftime("%Y%m%d_%H%M%S")
folder_name = f"{current_time}"
os.makedirs(folder_name, exist_ok=True)
text_filename = os.path.join(folder_name, f"{current_time}_content.txt")
with open(text_filename, "w") as file:
file.write(f"主题: {topic}\n\nYouTube脚本:\n{youtube_script}\n\n标题: {title}\n\n描述:\n{description}\n\n")
os.rename(tts_filename, os.path.join(folder_name, tts_filename))
os.rename(video_filename, os.path.join(folder_name, video_filename))
os.rename(srt_filename, os.path.join(folder_name, srt_filename))
os.rename(thumbnail_filename, os.path.join(folder_name, thumbnail_filename))
print(f"所有文件已保存至文件夹{folder_name}")
9. 上传视频至YouTube
使用YouTube数据API自动上传视频,并设置标题、描述和缩略图。此步骤需要提前配置API验证。
CLIENT_SECRETS_FILE = "path/to/your/client_secret.json"
SCOPES = ["https://www.googleapis.com/auth/youtube.upload"]
def get_authenticated_service():
credentials = None
if os.path.exists("token.pickle"):
with open("token.pickle", "rb") as token:
credentials = pickle.load(token)
if not credentials or not credentials.valid:
if credentials and credentials.expired and credentials.refresh_token:
credentials.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(CLIENT_SECRETS_FILE, SCOPES)
credentials = flow.run_local_server(port=0)
with open("token.pickle", "wb") as token:
pickle.dump(credentials, token)
return build("youtube", "v3", credentials=credentials)
def upload_video_to_youtube(youtube, video_file, title, description, thumbnail_file):
body = {
"snippet": {
"title": title, "description": description, "tags": ["motivation", "self-improvement", "success"], "categoryId": "22"
},
"status": {"privacyStatus": "public", "selfDeclaredMadeForKids": False}
}
media = MediaFileUpload(video_file, chunksize=-1, resumable=True)
response = youtube.videos().insert(part="snippet,status", body=body, media_body=media).execute()
print(f"已上传视频,ID为:{response['id']}")
youtube.thumbnails().set(videoId=response["id"], media_body=thumbnail_file).execute()
10. 使用调度进行自动化
我们使用schedule库让脚本定时运行,实现自动化内容生产。
import schedule
import time
import os
def job():
print("调度器正在运行...")
os.system("python3 /path/to/your/script.py")
print("调度器启动中...")
schedule.every(10).minutes.do(job)
while True:
schedule.run_pending()
time.sleep(1)
与ChatGPT合作的思考

这个项目展示了ChatGPT和Leonardo.ai在自动化内容创作中的强大能力。但要注意,YouTube不允许对AI生成的视频进行货币化。此外,使用API进行内容生成可能会产生较高的费用。许多推广自动化YouTube Shorts作为副业的视频可能是为了促销某些工具。因此,我建议在投入前先通过免费试用探索自动化想法,避免浪费资金。
结论
虽然使用AI工具自动化YouTube视频制作是一个有趣的技术探索,但必须考虑实际效果。YouTube对AI生成内容的货币化政策有限,制作此类视频还可能涉及较高的API成本。
此外,许多推广自动化副业的视频实际上是通过联盟营销推广某些工具。相反,我建议通过免费试用或低成本方案进行尝试。最终目标应该是创造对观众有价值的内容,而不是追求低质量、高产量的自动化视频。
尽管成功地实现了自动化视频制作,但为了避免制造低质量内容,我选择不再继续此项目。 请谨慎使用这些强大的工具,着重于创造有意义的贡献,而不是仅仅追求货币化机会。