在这篇文章中,我将带领你了解一个完整的自动化系统,帮助你将任何内容重新利用为你想要的任意数量的其他文章。
输入的内容可以是任何形式:YouTube 视频链接、博客文章链接、大纲、推文、PDF 等等...
我会在本文末尾提供所有代码。
跟随我一步步了解所有工作原理,这样你就可以根据需要编辑代码。
它是如何工作的?
重新利用这些文章的主要引擎是我们的 强大提示。这些提示被馈送到 OpenAI 的大语言模型 或者你选择的模型,它将为我们完成所有工作。
在我的案例中,我将使用 GPT-4o。
首先,我们将从输入的链接/文件中提取内容。
但是我们如何只用一行代码提取任何内容呢?
这就是 SimplerLLM 登场的时候,这是我最近开发的一个 Python 库。正如你将看到的,它使编写 AI 工具变得更加简单。
从这里,我实施了两种策略:
策略 1: 我们将提取的内容馈送到 OpenAI 的 GPT-4o 模型,使用 SimplerLLM,并根据我们使用的提示获取一个重新利用的内容片段。
💡 我实施这一步是为了让你更容易理解主要自动化脚本的基础。
策略 2: 这是将提取的内容转换为 三种不同类型 内容的主要代码,同样使用 SimplerLLM。
然后,我们将获取的输出合并为一个 JSON 格式的输出。
现在,无论你使用哪种代码,输出都将保存在代码文件夹中的一个 txt/json 文件中。
策略 1:基础代码
到目前为止,你应该已经掌握了代码工作原理的概念。那么,让我们开始技术细节吧!
首先,我们的代码高度依赖于 SimplerLLM,以使其简单而简短。
因此,让我们从安装该库并导入开始。
pip install simplerllm
首先,我们需要创建一个 .env 文件,并添加我们的 OpenAI API 密钥,以便 SimplerLLM 函数可以使用它来生成响应。
如果你没有 API 密钥,前往 OpenAI 的网站 生成一个新的。然后,将其添加到此形式的 .env 文件中:
OPENAI_API_KEY = "YOUR_API_KEY"
现在,我们准备使用代码;以下是代码:
from SimplerLLM.tools.generic_loader import load_content
from SimplerLLM.language.llm import LLM, LLMProvider
from resources import text_to_x_thread, text_to_blog_post, text_to_medium_post, text_to_summary, text_to_newsletter
# 这里的输入可以是 YouTube 视频链接、博客文章链接、CSV 文件等等
file = load_content("https://learnwithhasan.com/create-ai-agents-with-python/")
# 根据需要编辑提示名称
final_prompt = text_to_x_thread.format(input = file.content)
llm_instance = LLM.create(provider=LLMProvider.OPENAI, model_name="gpt-4o")
response = llm_instance.generate_response(prompt=final_prompt, max_tokens=1000)
with open("response.txt", "w", encoding='utf-8') as f:
f.write(response)
正如你所见,我们向代码中导入了两样东西:我们将使用的 SimplerLLM 函数和我创建的资源文件,其中保存了所有强大提示,我会免费提供给你!
file 变量使用了 SimplerLLM 函数 load_content,它以你的链接/文件作为输入并加载其数据。
因此,我首先通过将博客文章内容与之前导入的资源文件中的 text_to_x_thread 提示一起传递,格式化我的提示并存储在 final_prompt 变量中。
现在,我们创建一个 OpenAI LLM 实例,以调用他们的 GPT 模型,并使用 generate_reponse 函数调用它,如上面的 response 变量所示。
💡 请注意,默认情况下,此函数返回最多 350 个标记作为输出;这就是为什么我们添加了 max_tokens 参数将其增加到 1000,因为我们的大部分输出会有点长。
然后,我们获取生成的响应并将其保存在 response.txt 文件中。以下是输出的样子:
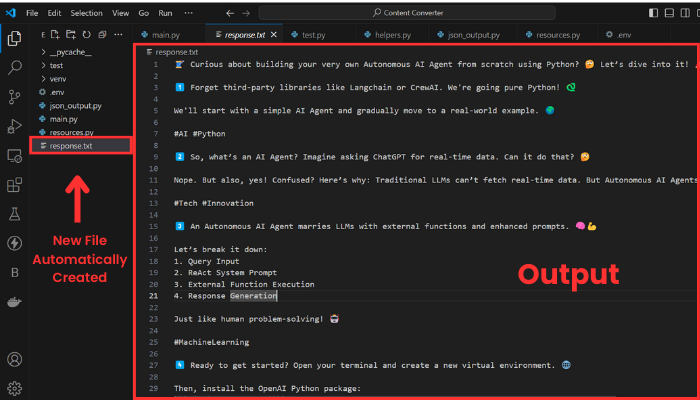
输出由十个线程组成,如果我想展示整个内容,会太长。无论如何,我的目的是向你展示它是有效的。
现在,让我们尝试另一个示例,将 YouTube 视频转换为博客文章。
为此,我们需要更改输入和我们使用的提示。
我将选择一个来自 我的 YouTube 频道 的视频作为输入。
以下是编辑后的代码行:
file = load_content("https://www.youtube.com/watch?v=DAmL-b_c85c")
要更改提示,编辑以下代码行:
final_prompt = text_to_blog_post.format(input = file.content)
让我们运行它并查看输出:
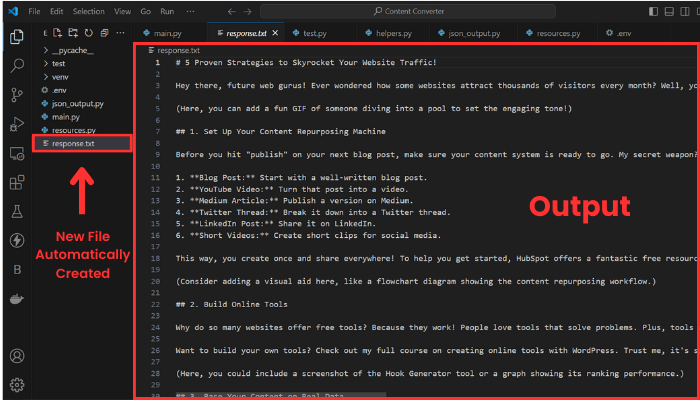
如你所见,格式已更改为博客文章,并且输入现在是 YouTube 视频的转录。
这里是我们上面使用的代码以及包含一些强大提示的 resources.py 文件:
策略 2:主要代码
现在,是时候进入真正的部分了,这就是你一直在等待的!
在这个策略中,通过单击一次,你将能够将你的内容重新利用为三种不同类型的内容,所有内容都以 JSON 输出格式呈现,这将使它们更易于访问。
使用此方法不需要任何新资源;你只需要更新的代码。以下是代码:
import json
from SimplerLLM.tools.generic_loader import load_content
from SimplerLLM.language.llm import LLM, LLMProvider
from resources import text_to_x_thread, text_to_summary, text_to_newsletter, format_to_json
llm_instance = LLM.create(provider=LLMProvider.OPENAI, model_name="gpt-4o")
# 这里的输入可以是 YouTube 视频链接、博客文章链接、CSV 文件等等
file = load_content("https://learnwithhasan.com/create-ai-agents-with-python/")
# 获取 3 种输入
x_prompt = text_to_x_thread.format(input = file.content)
newsletter_prompt = text_to_newsletter.format(input = file.content)
summary_prompt = text_to_summary.format(input = file.content)
# 生成 3 种社交帖子
x_thread = llm_instance.generate_response(prompt = x_prompt, max_tokens=1000)
with open("twitter.txt", "w", encoding='utf-8') as f:
f.write(x_thread)
newsletter_section = llm_instance.generate_response(prompt = newsletter_prompt, max_tokens=1000)
with open("newsletter.txt", "w", encoding='utf-8') as f:
f.write(newsletter_section)
bullet_point_summary = llm_instance.generate_response(prompt = summary_prompt, max_tokens=1000)
with open("summary.txt", "w", encoding='utf-8') as f:
f.write(bullet_point_summary)
# 将它们转换为 JSON 格式
final_prompt = format_to_json.format(input_1 = x_thread,
input_2 = newsletter_section,
input_3 = bullet_point_summary)
response = llm_instance.generate_response(prompt = final_prompt, max_tokens=3000)
# 验证并以缩进形式写入 JSON 以便阅读
try:
json_data = json.loads(response)
with open("Json_Result.json", "w", encoding='utf-8') as f:
json.dump(json_data, f, ensure_ascii=False, indent=4)
print("JSON 保存成功。")
except json.JSONDecodeError as e:
print("JSON 格式错误:", e)
with open("Json_Result.json", "w", encoding='utf-8') as f:
f.write(response)
这段代码的结构与上面的代码非常相似;我们在这里也使用相同的函数。
主要区别在于,我们不再仅生成一种类型的内容,而是使用 OpenAI 的 GPT 模型将选择的输入重新利用为三种不同类型的内容。我们将每个输出保存在一个带有相应名称的 TXT 文件中。
**💡 请注意,你也可以编辑这里的提示,以获得不同的结果,就像我上面展示的那样。
然后,在获取三个输出后,我们将它们合并为一个 JSON 输出,使用一个 强大提示,并将它们保存在一个 json 文件 中。
然而,GPT 的响应并不总是有效并生成正确的 JSON 格式。这就是为什么我添加了一个 try-except 语句,以便如果它不起作用,它会打印代码并将其保存为原始文本。
我无法详细说明如何修复这个问题,但你可以查看这篇博客文章;它肯定会帮助你改进结果。
现在,让我们尝试并看看我们得到了什么!
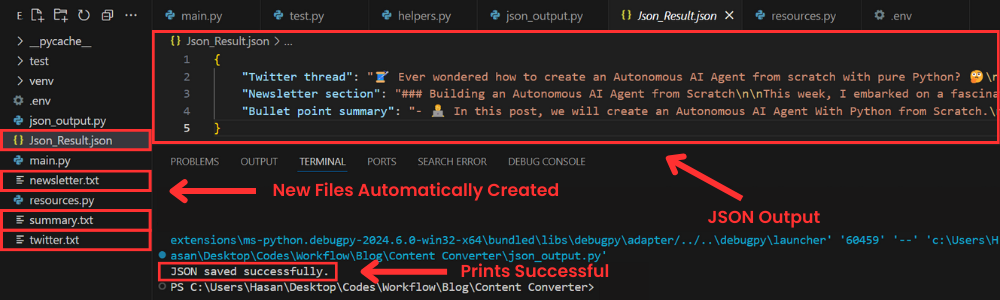
如你所见,创建了四个新文件;其中 3 个包含单独生成的三种内容,还有一个包含最终 JSON 格式输出的 json 文件。
随意玩弄提示,你将获得符合你偏好的新结果。
👉 代码
为工具创建用户界面
虽然脚本在终端中运行得很完美,但为什么我们不构建一个简单易用的界面,让运行代码变得更加容易呢?
而且,那些对编程一无所知的人也可以在完全不与代码交互的情况下使用它。
如果我们将下面的强大提示与 Streamlit 结合起来,这将非常简单:
扮演一位专业的 Python 程序员,专门使用 Streamlit 构建用户友好的 UI。为提供的脚本创建一个 Streamlit 用户界面。
确保对所有代码进行注释以增强理解,特别是针对初学者。选择最适合给定脚本的控件,并致力于创建专业、用户友好的界面。
目标受众是希望了解如何使用 Streamlit 创建用户界面的初学者。
响应的风格应具有教育性和详尽性。鉴于其指导性质,应在代码中广泛使用注释,以提供上下文和解释。
输出:提供经过优化的 Streamlit UI 代码,通过注释分段解释代码的每个部分,以便更好地理解。
输入:提供的脚本:{your input script}
这个提示是**高级提示库**的一部分,每个月都会更新,提供新的特殊提示。
无论如何,我使用了这个提示,几秒钟内就用 Streamlit 为我的工具创建了一个用户界面。以下是它生成的代码:
import streamlit as st
import json
from SimplerLLM.tools.generic_loader import load_content
from SimplerLLM.language.llm import LLM, LLMProvider
from resources import text_to_x_thread, text_to_summary, text_to_newsletter, format_to_json
llm_instance = LLM.create(provider=LLMProvider.OPENAI, model_name="gpt-4o")
st.title("一键生成内容")
url = st.text_input("输入您的输入的 URL 或文件名:")
if st.button("生成内容"):
if url:
try:
file = load_content(url)
x_prompt = text_to_x_thread.format(input=file.content)
newsletter_prompt = text_to_newsletter.format(input=file.content)
summary_prompt = text_to_summary.format(input=file.content)
x_thread = llm_instance.generate_response(prompt=x_prompt, max_tokens=1000)
newsletter_section = llm_instance.generate_response(prompt=newsletter_prompt, max_tokens=1000)
bullet_point_summary = llm_instance.generate_response(prompt=summary_prompt, max_tokens=1000)
st.subheader("生成的 Twitter 线程")
st.write(x_thread)
st.markdown("---")
st.subheader("生成的通讯部分")
st.write(newsletter_section)
st.markdown("---")
st.subheader("生成的要点摘要")
st.write(bullet_point_summary)
st.markdown("---")
final_prompt = format_to_json.format(
input_1=x_thread,
input_2=newsletter_section,
input_3=bullet_point_summary
)
response = llm_instance.generate_response(prompt=final_prompt, max_tokens=3000)
try:
json_data = json.loads(response)
st.markdown("### __生成的 JSON 结果__")
st.json(json_data)
st.download_button(
label="下载 JSON 结果",
data=json.dumps(json_data, ensure_ascii=False, indent=4),
file_name="Json_Result.json",
mime="application/json"
)
except json.JSONDecodeError as e:
st.error(f"JSON 格式错误:{e}")
st.write(response)
except Exception as e:
st.error(f"发生错误:{e}")
else:
st.warning("请输入有效的 URL。")
上面的代码生成了您选择的三种内容类型,显示它们,并在最后显示带有下载按钮的 JSON 结果,以便一键下载结果。
现在,要运行这段代码,您需要将代码保存为 ui.py,打开一个新的终端并运行以下命令:
streamlit run ui.py
当然,您可以更改文件名,但在运行时还需要将其更改为新文件的名称。
运行后,将打开以下网页:
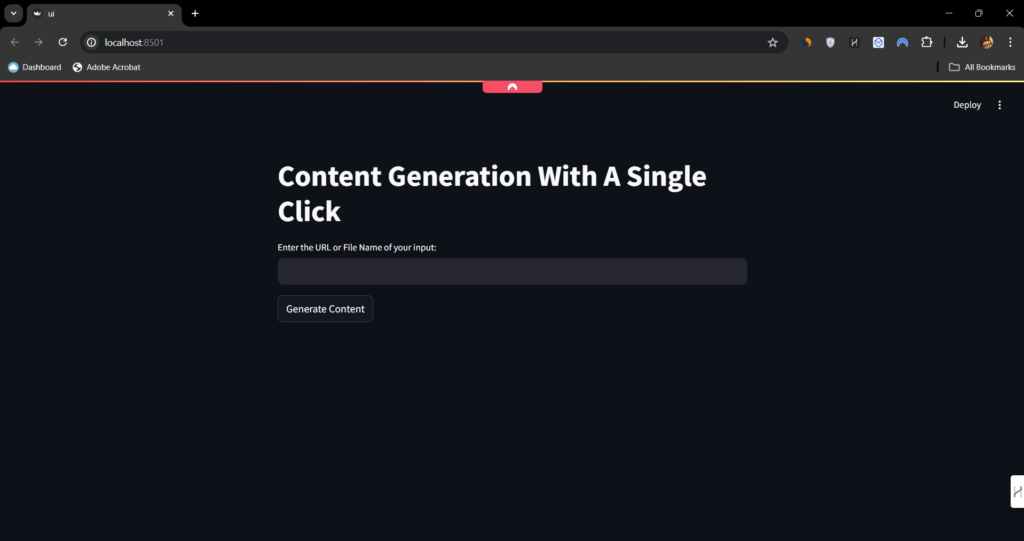
正如您所见,这非常简单易用。您只需输入链接或文件名,然后点击生成按钮即可获取所有结果。
奖励:将此工具变成赚钱机器
与其仅将工具保留供您使用,不如让其他人使用并为每次使用收费。
让我解释一下:
如果您在您的 WordPress 网站上为工具构建一个整洁的用户界面(这是最容易的事情之一),您可以建立一个积分系统,人们可以购买积分来使用这些工具。
这就是我在他的工具页面上使用的技术,他会根据使用的工具收取人们一定数量的积分。