在与大型语言模型(如 GPT4 和 Claude 3 Haiku)一起工作数月后,为客户提供咨询和构建服务,我意识到避免孤立使用大语言模型是多么重要。
普通人通常以一种单一的方式使用大语言模型,即提示,回应。这通常充满了大量的试错和来回,直到你找到确切的答案为止。如果你长时间使用大语言模型,你可能会开始对有时得到的通用回复感到沮丧,因为你要经历这些循环的询问。
大语言模型的真正力量在于以构建应用程序逻辑的方式来使用它们,具有清晰的上下文边界和明确的角色。清晰的示例对有效引导模型至关重要。你需要专注于将这些模型纳入更广泛的工作流程中,其中现有的工作流程可以与彼此协同工作的不同变体的这些 AI 模型相结合,以解决复杂问题。
大语言模型已经经历了它们的加密 ICO 时刻。使用这些大语言模型的成本已经变得更加便宜,适用于高交易量任务,使其更易获得,并且现在是开始寻求大语言模型可以作为你的新工作流程或现有工作流程的一部分来补充的创造性和创新性方法的黄金时期。
我已经整理了一份高度主观的想法清单,超越了仅仅使用大语言模型的范畴,比如一个谷歌搜索或文档搜索替代工具,这些想法可以成为你下一个大语言模型驱动项目的产品想法。如果执行得当,这些想法有潜在的好处,可以为你的业务带来真正的价值,无论你是想将它们纳入你的业务,还是作为你工作中的兼职项目的一部分。
1. 带有自定义知识的链式 RAG 对话聊天机器人
在为真实用例构建机器人时,客户希望他们的数据安全,并且具有可预测的成本。因此,对于这个人群类别,最好的方法是创建一个不使用付费服务且可以自托管的东西。随着新的开源模型与 Openai 的模型不相上下,这变得更加容易。
关键在于确保这种 ChatGPT 机器人可以部署在内部协作工具中,如 Slack、Microsoft Teams,甚至 WhatsApp 群组中。
老实说,仅仅将文档贴上并创建一个可以回答文档问题的机器人,从我在一家大型金融科技组织工作的经验来看,导致了无人使用的陈旧机器人,原因有很多,可以总结为实现逻辑不佳或机器人所依赖的整体文档很快过时,而且更快地直接私信你或你的下一个同事询问信息。
LLM 聊天机器人的缺点在于,如果你的文档不经常更新,那么拥有机器人的初衷就会失去意义,因为人们总是会回到最初不使用机器人的状态。重要的是不要仅仅向你的大语言模型投放随机文档进行向量数据库搜索查找。如果没有经过深思熟虑的知识库组织过程,它将变成另一个未经优化的目录搜索引擎,充满了幻觉。
你需要做的是构建适合对话的查找逻辑。举个例子,在你的 Telegram 或 Slack 群组中有一个支持聊天机器人。机器人将以工作流程方式做出反应,其中可以根据对话或提示调用多个工作流程。如果机器人无法回答问题,设计一个反馈循环可以帮助解决这个问题。这可以简单地提示用户从预定义的操作列表中选择要执行的操作,例如
-
查找文档存储库,如维基页面或 Google 文档,以解决你的问题
-
查找 Slack 历史对话
-
连接到支持系统,如 Jira,提出支持问题,或利用你的事件响应管理服务来调用流程。
-
标记谁值班处理问题
对于那些编程的人来说,这看起来很熟悉,因为这是事件的逻辑步骤。
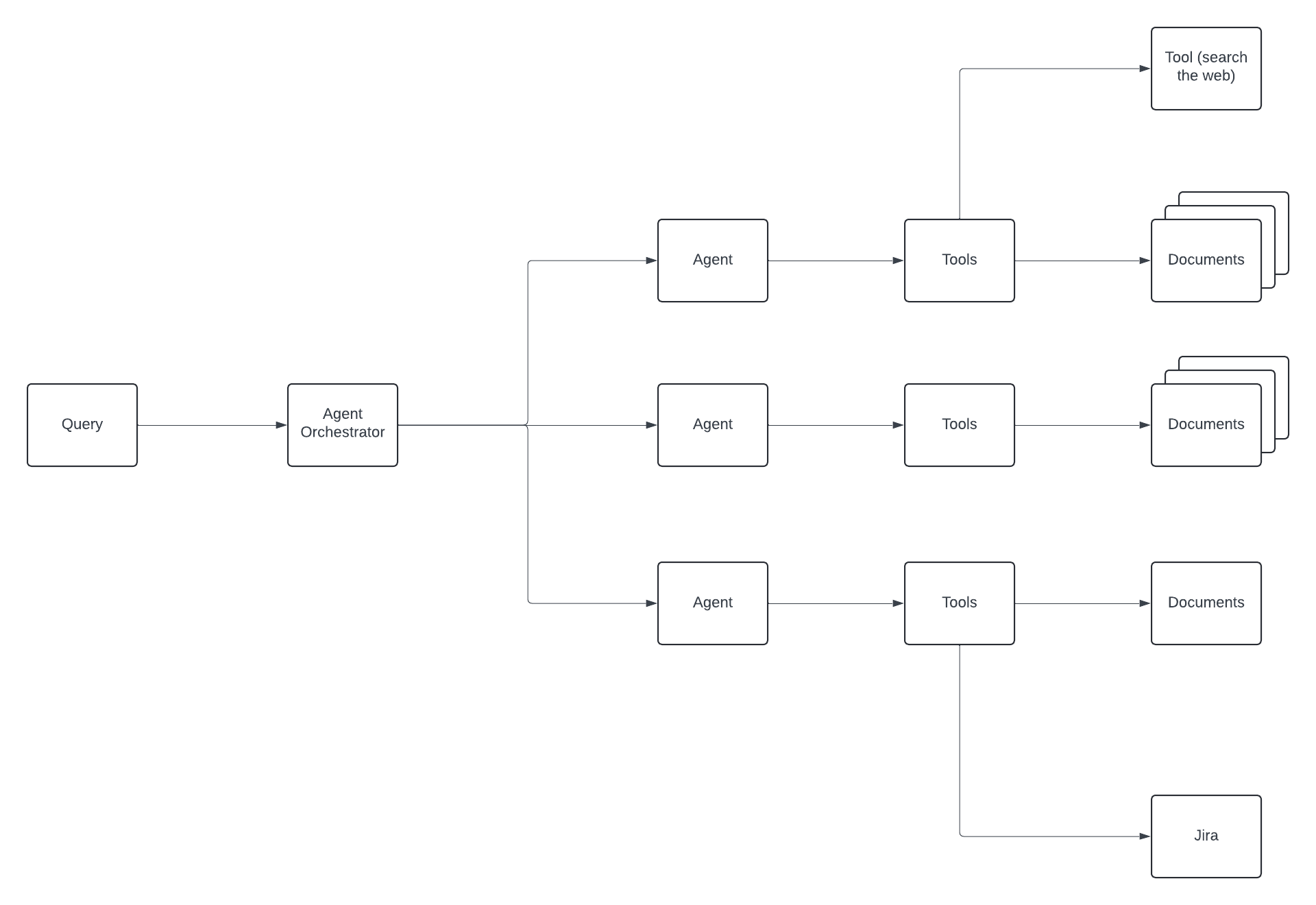
上面的例子准确地说明了我所说的不要孤立构建 LLM 机器人,而是将它们与现有工作流程和系统结合起来,以增强任务。
这意味着你可以设计与你的应用程序交互并解决支持查询或问题的机器人,这才是真正的价值所在。提高生产力意味着你有足够的时间在其他地方赚钱。
你如何实现这种工作流类型的代理通信?有像 CrewAI 和 LangGraph 这样的框架,专门用于处理大语言模型中的循环工作流链式思维过程。
基本思想是代理可以接收来自其他代理先前输出的反馈,这作为下一个代理的输入。有了这个概念,你可以构建更好的 RAG 聊天机器人,它们可以利用工具来丰富你的数据检索,同时保持过去互动的记忆。
2. 自动流程生成
生成式 AI 已经解锁了令人兴奋的新可能性,特别是在游戏设计领域。让我们看一个假设性例子来说明,以激发想法。想象一种服务,通过一个简单的界面,你可以输入你想创建的流程名称。这个流程可以定义特定的动作和行为,然后将它们链接在一起,形成更复杂和精细的游戏内交互。
开发人员可以通过利用大语言模型(LLMs)的链接能力,构建适用于这些特定用例的服务。一个引人注目的例子是在游戏设计中自动创建流程,这打开了创新游戏工作流和对话角色扮演场景的大门。
游戏中的对话 NPC(非玩家角色)通常是单调和重复的。有了大语言模型的参与,我们现在可以设计能够使用自然语言与玩家互动的 NPC。通过利用大语言模型的能力,NPC 可以动态理解和回应玩家的输入,创造出更具沉浸感和互动性的游戏体验。
除了对话,AI 还可以帮助玩家完成游戏任务。例如,在游戏中的工作流辅助可以引导玩家完成复杂的挑战,如制作或解决谜题。这加深了沉浸感,并将支持整合到叙事中,使每个任务都显得有意义且相互关联。
大语言模型为根据不同 NPC 个性塑造逼真、动态对话提供了巨大潜力。想象一下一个 NPC,它记得以前的互动并根据上下文做出回应,增强了玩家的沉浸感。此外,大语言模型可以生成基于玩家选择演变的动态叙事,实现个性化叙事,其中决策影响游戏的进展和结果。
尽管像 ChatGPT 这样的大语言模型还不是真正的人工通用智能(AGI),我们可以通过提高上下文理解和知识来增强它们的能力,使 NPC 看起来更像 AGI,从而提高游戏速度的重要性。
3. 支付和订单放置机器人
虽然这可能需要大量工作,以正确的确定性方法进行仔细的提示工程,并结合可以执行有效检查和平衡的代码集成,但可以设计一个可靠的机器人,可以嵌入到任何平台或移动应用程序中,并执行预定义的指令,同时为用户提供一个类似对话的界面进行交互。
使用自然语言可以为设计提供极简界面的机会,或者你可能听到的对话界面,为用户提供类似聊天的体验。这里有一个简化过的 Github 仓库,可以让你理解这一点。
当你开始走上这条需要更少问责制的应用程序之路时,请注意将需要进行广泛测试,因为你可能不希望让未经监督的 AI 对你付费的客户进行放任,这可能会导致意想不到的后果。
4. 数据可视化仪表板
LLM 模型更有趣且被低估的用例之一是能够解释和理解结构化数据集,这些数据集可以很容易地通过 NLP 转化为动态仪表板可视化。这些交互式仪表板允许新手用户实时查询和查看数据,而无需支付巨额的前期投资来构建定制解决方案或支付定制的 SAAS 服务,如 Power BI。
价值主张在于提高生产力和潜在的客户成本节约,其中数据查询和洞察可以更多地转向自然语言。使用 NLP 的能力意味着数据可以更容易地从不同角度进行分析,而无需高级开发人员构建定制静态报告。
例如,你可以使用数据可视化仪表板并询问 ChatGPT:
"提供 2022 年至 2023 年患有糖尿病的 X 人群的数据"。您可以通过添加变量来优化此查询,例如,
“提供 2022 年至 2023 年间患有糖尿病的女性人口群体 X 的人口统计数据”。
这样,您可以分析相同数据的不同变量组合,同时能够可视化、比较和对比。
对于某些复杂计算,与其让大型语言模型(LLM)直接生成答案,让LLM生成执行计算的代码然后执行该代码以获得结果可能更有效。您可以参考 Langchain 框架文档中的一个快速示例 这里。
要开始,请参考这篇 文章,该文章提供了有关使用 Langchain 查询数据的更多见解和灵感。
5. 微型聊天机器人
我喜欢将这个想法称为微型聊天机器人,其中聊天机器人被视为单次使用的实用工具或小伙伴,用于执行特定用例的任务链。当您使用类似 langchain 的框架时,这个想法也被称为代理链。如果您已经尝试过 Langchain、代理工具或 OpenAI 函数、工具,这应该不陌生。
Zapier Zaps 和 Vectorshift,一个 SAAS 工作流平台,是最接近这个想法的最佳示例。一次性聊天机器人的内容可以是 PDF 或其他文档类型、网站,或客户与服务代表之间的对话记录。
语义搜索可以在文本数据上进行对话式执行。构建这个的两种方法:一种是为用户提供基于向导的用户体验,用户可以选择他们希望使用的组件和模型来构建机器人,并以辅助方式为机器人提供系统消息和防护措施;另一种是让用户有能力根据自己的需求定制机器人。
要更好地理解这些概念,请查看 Zaiper 工作流程,这是我能想到的最接近的例子,很好地说明了这一点。
如果您是一名本地后端开发人员,第二种方法是使用自然语言处理的高级用户对话用户界面,其中高级用户可以通过语音将机器人创建出来。用户可以选择机器人应该与之交互以实现其目标的 API 服务,类似于 AutoGPT。
6. 使用 LLM NLP 能力进行欺诈检测和情感分析
LLM 在情感分析方面表现相当不错,因此可以用于检测欺诈。在欺诈行为中,骗子总是找到不同的方法来实施网络安全欺诈。这涉及绕过软件和应用程序的安全协议。因此,软件工程师必须保持领先地位,并确保为客户提供安全保障。
虽然 LLM 不能单独使用,但数据预处理对于确保最佳结果至关重要,这涉及将文本分类为不同的情感类别(积极、消极、中性)。同时,GPT-3.5 更倾向于生成连贯且上下文相关的回复,但现在您不仅仅局限于这一点。您有 GPT0、GPT4、AWS Titan、Anthropic Claude 3 Sonnet、Claude 3 Haiku、Cohere 和 Mistral AI,所有这些模型都具有更大的 Token 大小,这意味着您可以执行更复杂的任务,而不受我们在 2023 年所面临的限制。
专业人士可以利用 ChatGPT 生成工程项目想法。这款 AI 动力聊天机器人可以利用其深度学习能力分析文本的来源。它可以检测文本是由真正的权威发送还是由骗子制作。
通过这种方式,工程师可以利用 ChatGPT 开发用于欺诈检测的软件和应用程序,并整合其他先进技术以增强其结果。
让我们看一下下面的基本代码示例,这可以说明这一点。请注意,您需要设置一个 OPENAI_API_KEY 密钥作为您的环境变量的一部分才能运行 Python 代码。附有所需依赖项的 GitHub 存储库链接如下。
SentimentGPT 是我构建的一个简单演示微服务,用于辅助基本情感分类。该服务的理念是使用它来传输 Google Big Query 等大数据源,并执行分类。
import json
import os
import openai
from json import JSONDecodeError
from typing import Any, List
from pydantic import BaseModel, ValidationError, Field
from config import get_openai_token_cost_for_model
PROMPT = """
What is the sentiment of this statement?
Ranking On a scale of 1 to 10, how positive or negative is this review?
Opinion What is your opinion of this statement?
Profile What is the profile of the person who would write this review?
---------
{statement}
------
Format response as as JSON object
example:
{{
"sentiment": "Neutral",
"ranking": 5,
"opinion": "The statement presents an interesting possibility that should be further investigated.",
"profile": "Someone interested in global events and current affairs."
}}
"""
class SentimentResponseSchema(BaseModel):
sentiment: str = Field(...,
description="The sentiment associated with the response.")
ranking: int = Field(...,
description="The ranking or score of the response. a numeric measure of the bullishness or postive / bearishness negative. This ranges from 1 (extreme negative sentiment) to 10 (extreme positive sentiment.")
opinion: str = Field(...,
description="Model opinion or feedback.")
profile: str = Field(...,
description="The user's profile classification")
class OutputParserException(ValueError):
def __init__(self, error: Any):
super(OutputParserException, self).__init__(error)
class SentimentOutputParser(BaseModel):
response_schemas: Any
text: str
def parse_json(self) -> SentimentResponseSchema:
try:
json_obj = json.loads(self.text.strip())
except (ValidationError, JSONDecodeError) as e:
raise OutputParserException(f"Got invalid JSON object. Error: {e}")
expected_keys = [_field for _field in list(SentimentResponseSchema.__annotations__)]
for key in expected_keys:
if key not in json_obj:
raise OutputParserException(
f"Got invalid return object. Expected key `{key}` "
f"to be present, but got {json_obj}"
)
return SentimentResponseSchema.model_validate(json_obj)
class SentimentAgent(object):
model_name: str = "text-davinci-003"
@classmethod
def evaluate_sentiment(cls, prompt: str) -> SentimentResponseSchema:
if prompt is None:
raise ValueError("prompt required")
openai.api_key = os.environ.get("OPENAI_API_KEY")
response = openai.Completion.create(
model=cls.model_name,
prompt=prompt,
temperature=0.7,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
usage = response.get("usage", {})
prompt_tokens = usage.get("prompt_tokens", 0)
completion_tokens = usage.get("completion_tokens", 0)
total_tokens = usage.get("total_tokens", 0)
total_cost: float = 0.0
completion_cost = get_openai_token_cost_for_model(
cls.model_name, completion_tokens, is_completion=True
)
prompt_cost = get_openai_token_cost_for_model(cls.model_name, prompt_tokens)
total_cost += prompt_cost + completion_cost
cost_info = (
f"Tokens Used: {total_tokens}\n"
f"\tPrompt Tokens: {prompt_tokens}\n"
f"\tCompletion Tokens: {completion_tokens}\n"
f"Total Cost (USD): ${total_cost}"
)
print(cost_info)
return SentimentOutputParser(
response_schemas=SentimentResponseSchema,
text=response['choices'][0]['text']).parse_json()
def get_google_play_store_app_reviews() -> List[str]:
reviews = [
"Booking a ride is is error prone and unintuitive. You cannot select your target destination directly on the map, you must choose from a list that AppRide knows. Once selected, the map opens asking you where you would like to be picked up. You cannot check your destination the map until after AppRide starts looking for a driver. Such a bad interface.",
"Drivers tend to cancel last minute. The app is very bad at updating the location of the driver. ",
"Excellent and must have app for living in Thailand and any other country that uses AppRide! Only negative is that when ordering food or groceries, there is a lot that is in Thai and/or another language. Thankfully, there are pictures for everything and you can always screenshot then use google translate, but it would be great if there was a way to have a built-in translator. That has caused very few issues for me, but it is an issue. However, NOT one that should scare someone away from using this.",
"I would like to extend my thanks to the driver. He has been patient with us, and pleasant with a ready smile. He has been accommodating and did his best to help us fit the TV inside his cab, not a small feat and we manage to settle in. His service is exceptional and worth mentioning. It is rare to see such kindness. Thank you so much for all your help, your service is commendable and greatly appreciated"
]
return reviews
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
reviews = get_google_play_store_app_reviews()
for review in reviews:```markdown
sentiment = SentimentAgent.evaluate_sentiment(PROMPT.format(statement=review))
print(sentiment)
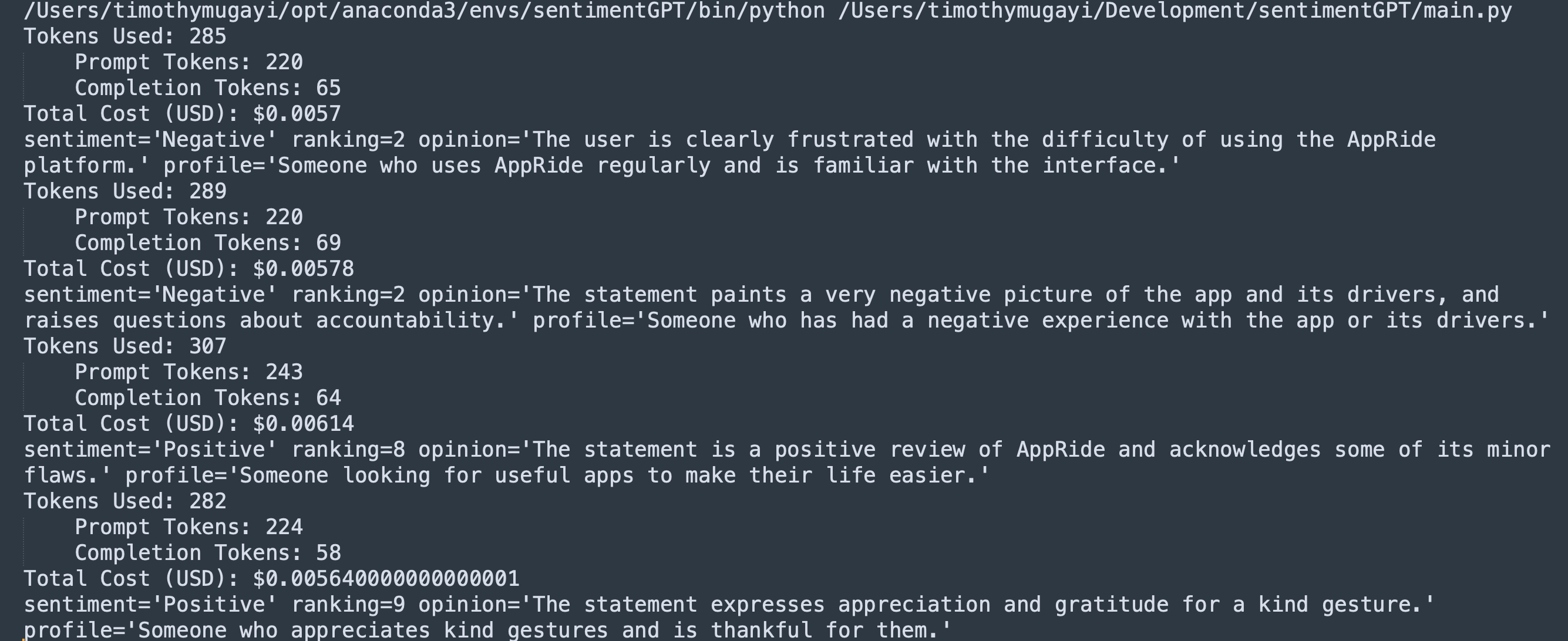
有关完整源代码和 PyPI 依赖项,请参阅此处的 Git 存储库。
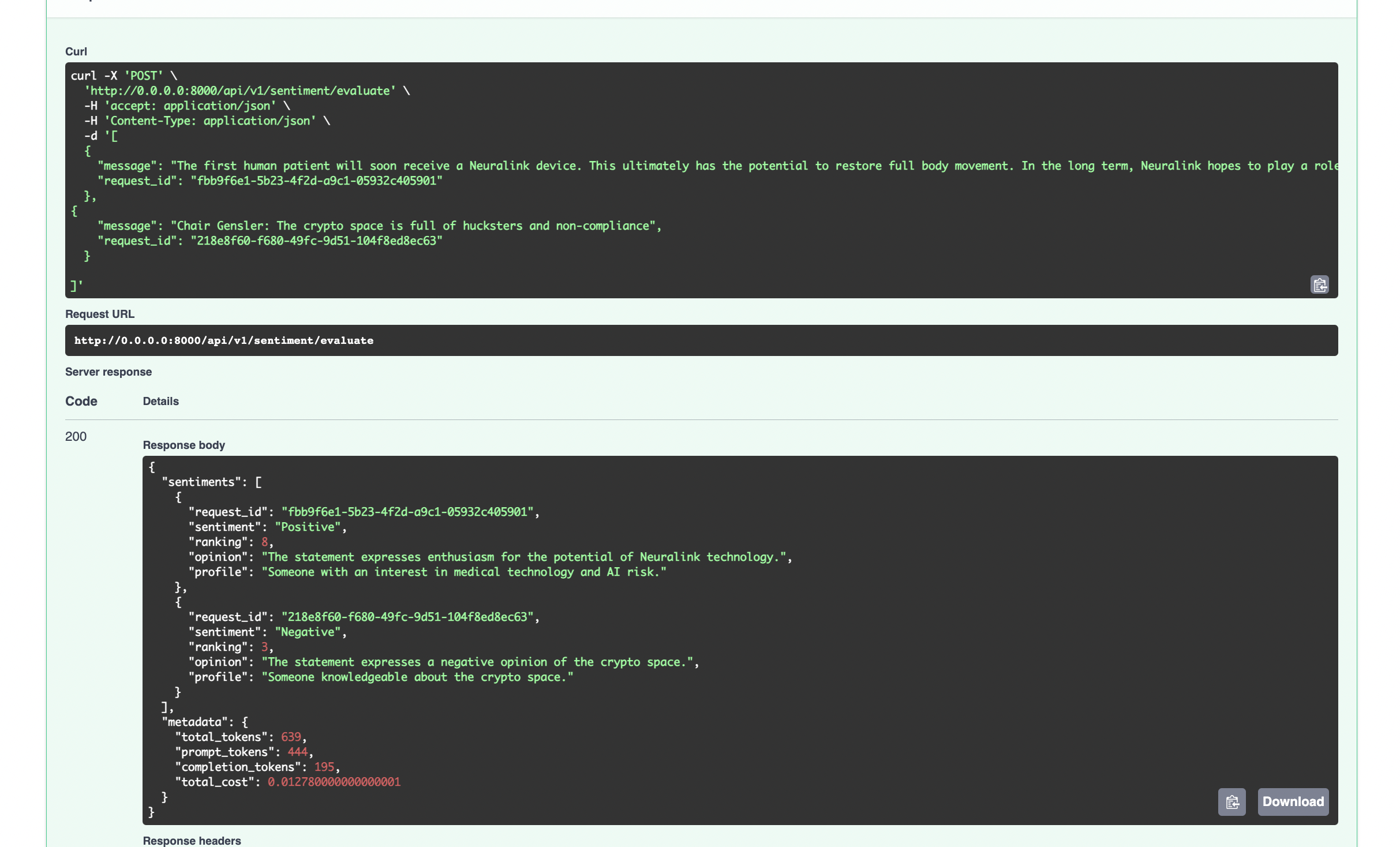
虽然成本可能会迅速增加,但在扩展解决方案时,利用开源模型可能是一种替代方法。在考虑使用付费模型(如 GPT)的结果带来的潜在投资回报率时,需要考虑成本和潜在 ROI。您也可以尝试一下 Ollama-3,您可以在本地免费运行它。
7. 使用机器学习的个性化推荐引擎
推荐系统已经成为我们日常生活中不可或缺的一部分,帮助我们浏览海量在线信息。这些系统根据我们的偏好、浏览历史和其他数据点为我们提供个性化推荐,从电子商务平台到流媒体服务。
想象一下,将一个机器人与 N 个电子商务网站集成,并要求 GPT 提供跨多个渠道的见解、最佳价格或推荐。
ChatGPT 是一个完美的工具,可以成为一个助手,旨在成为一个有用的助手,用于创建可以分析用户行为模式的应用程序。
例如,数据集分析显示某个年龄段的人群喜欢听某种类型的音乐。这种知识可以用来定制个人喜欢的音乐类型。这种副产品将带来公司重复的好处,这将导致对客户的更好理解。同时,客户将不必浪费时间搜索他们喜欢的服务。
推荐引擎有各种形式。我个人感兴趣的一个领域是食品订购和旅行规划。是的,您可以构建一些非常复杂的东西,如果做得正确,可以将其作为服务出售。即使您不擅长构建漂亮的用户界面,也有许多类似 langchain 的版本,例如 crewAI,可以让您在一定程度上实现这一点。
另一种选择是基于 API 的服务,可以为用户提供一个通道,轻松地集成到您的服务中。想象一下 ChatGPT 插件,其中 API 的底层层也是一系列基于 ML 模型的链,根据先前的偏好提供定制推荐。
8. 合成数据生成器
随着组织的增长,数据隐私和治理变得至关重要。在软件开发中,访问数据对于开发人员来说至关重要,以便测试、维护和复制更接近生产环境的类似环境,考虑到大型组织中困扰的合规问题和严禁在测试环境中混合生产数据的问题。在合成数据准备方面,LLM 在这里有真实的用例。
合成数据提供了许多好处,例如
-
在需要通过均匀分布数据集进行再平衡时,提供了一种更便宜的数据准备解决方案
-
它有助于维护 PII 数据隐私,减轻 HIPAA 风险,并在测试、训练和大规模复制时鼓励遵守 GDPR 等数据法规。
-
如果数据生成的方式避免偏见,它有助于促进 AI 模型的公平性和包容性。
初创企业面临的挑战之一是需要更多的数据。构建任何自定义数据生成解决方案可能会导致一个需要长期回报投资的永久项目。利用 LLM 可能是速度与成本的最佳平衡点。
如何将计费纳入基于 LLM 的应用程序
毕竟,构建任何软件的目标通常是利用机会获得一些投资回报。在推出解决方案之前,将资金化纳入您的 LLM 应用程序是非常重要的,因为每笔交易都会产生成本,这可能会迅速积累大额账单。我想花点时间为您提供一些关于如何处理资金化的想法。
消费者携带自己的 OpenAI 密钥。在这种模式下,云 LLM 使用没有前期成本;因此,无需构建任何额外内容来管理配额。您只需为托管应用程序的计算能力付费。这种方法意味着构建一个功能,允许安全存储用户的 API 密钥。您还应确保获得一些法律建议,以确保隐私政策清晰并保护您和您的用户。
基于配额 + 服务器托管成本。这种方法意味着您构建的任何基于配额或订阅模型的 LLM 想法将作为应用程序代码的一部分。
按年度月费租赁您的代码。B2B: 如果您是自由开发人员或只是想开始,这可能是一个具有较低前期成本的可行选择。这里的成本将是确保您维护代码的时间。
通过整合加密货币进行代币化: 通过这种策略,您可以扩大您的影响力。这种方法提供了几个关键优势,包括全球可访问性,无需依赖传统银行,适用于微交易的无摩擦低费用支付,以及通过用户购买代币来访问 LLM 功能的代币经济化的能力。
这种方法还通过区块链确保透明性和去中心化,同时实现了一种灵活的按需付费模式,用户只支付他们消费的服务,就像 PAAL AI 和 ChainGPT 项目中所看到的那样。
总结
AI 可以为各行各业的企业提供重大价值。当我们走出 LLM 炒作周期时,我认为现在是一个很好的时机,开始更认真地考虑可以从 LLM 中受益的用例,这些用例可以在您现有的工作流程中带来真正的价值和投资回报。