今天,我们将使用Node.js和OpenAI的API构建一个语音转文本的Web应用。我们将使用OpenAI的API来使用其Whisper模型,该模型允许我们上传mp3格式的音频文件,并为我们提供其转录。它甚至可以将其他语言的音频翻译成英文文本,这真是令人难以置信。
首先,我们将设置一个新的Node.js项目,以便我们可以开始构建我们的应用程序。所以,我们将创建一个文件夹来构建我们的项目,并使用命令行进入该文件夹,然后我们可以使用以下命令设置一个新的Node.js项目:
npm init
运行此命令后,它会询问一些问题,例如应用程序的名称、入口点等。我们现在可以将它们保持默认值。之后,您会看到它创建了一个package.json文件。此文件将包含有关我们的应用程序的信息以及我们为此应用程序安装的软件包。
因此,下一步是将必要的节点模块(即软件包)安装到我们的应用程序中,以便我们准备开始构建应用程序。我们可以通过运行以下命令来完成:
npm install express multer openai cors --save
我们安装了这四个软件包,并使用--save将这些软件包添加到package.json文件中。这样,克隆存储库的其他人只需运行一次npm install命令即可安装所有所需的软件包。
我们还希望在我们的应用程序中使用nodemon软件包,以帮助我们在检测到代码更改时自动刷新和重新加载服务器,这样我们就不必在每次更改后手动重新启动服务器。因此,我们将其添加为开发依赖项,因为它只用于开发中的帮助,我们不会直接在代码中使用它。我们可以使用以下命令安装它:
npm install --save-dev nodemon
现在,我们已经拥有了所有必要的软件包来开始我们的开发工作。正如我们在package.json文件中看到的那样,其中将包含我们安装的所有模块和软件包,以及有关应用程序的一些详细信息。package.json文件如下所示:
{
"name": "speechtext",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"dependencies": {
"cors": "^2.8.5",
"express": "^4.18.2",
"multer": "^1.4.5-lts.1",
"openai": "^3.2.1"
},
"devDependencies": {
"nodemon": "^2.0.22"
}
}
因此,正如我们所看到的,index.js写在main中,表示index.js文件是我们应用程序的入口点。如果您记得,在运行npm init命令时进行设置过程中会询问这个问题。如果您将其保留为默认值,那么您将具有相同的入口点;否则,您将具有在那时定义的入口点。
现在,我们将创建一个名为index.js的新文件。您可以根据您定义的入口点将文件命名为您希望的任何名称。我们在此处考虑index.js。
index.js
因此,我们现在将开始构建index.js文件。我们将从导入所需的模块开始。对于索引文件,我们需要express和cors。因此,我们从这两个模块开始:
const express = require('express');
const cors = require('cors');
接下来,我们将创建一个express应用程序的新实例。此外,我们将设置我们的应用程序以使用cors,处理json数据,并使public文件夹包含静态文件,这些文件可以由客户端或前端访问。
const app = express();
app.use(express.static('public'));
app.use(express.json());
app.use(cors());
接下来,我们希望有一个单独的文件,我们将在其中定义API。我们将创建一个名为routes的文件夹,在其中,我们将有一个名为api.js的文件,其中将定义应用程序中所需的GET和POST API。为了通知应用程序,我们将在定义基本URL和文件位置的位置添加此行代码,其中将定义所有API的文件。这是一个中间件,帮助我们设置应用程序的路由。
app.use('/', require('./routes/api'));
接下来,我们使用错误处理中间件函数,用于处理应用程序中发生的任何错误。
app.use(function(err,req,res,next){
res.status(422).send({error: err.message});
});
最后,我们设置应用程序监听指定的端口号上的传入请求,我们可以使用环境变量设置它,也可以直接定义。
app.listen(process.env.PORT || 4000, function(){
console.log('Ready to Go!');
});
我们在应用程序中使用了端口4000。我们还在其中有一个简单的console.log,当应用程序准备好接收请求时,它会将消息记录到控制台。
完整的index.js文件:
const express = require('express');
const cors = require('cors');
const app = express();
app.use(express.static('public'));
app.use(express.json());
app.use(cors());
app.use('/', require('./routes/api'));
app.use(function(err,req,res,next){
res.status(422).send({error: err.message});
});
app.listen(process.env.PORT || 4000, function(){
console.log('Ready to Go!');
});
接下来,我们将转到我们在routes文件夹中创建的api.js文件。
api.js
因此,我们现在将开始构建api.js文件。我们将从导入所需的模块开始。我们将导入express,multer和openai库。
const express = require("express");
const multer = require("multer");
const { Configuration, OpenAIApi } = require("openai");
Multer是一个中间件,我们使用它来处理multipart/form-data,因为我们将处理音频文件的上传。
从openai中,我们需要Configuration和OpenAIApi模块,我们将使用它们来向Whisper模型发送API请求。
然后,我们将设置express路由器并创建multer中间件的实例。
const router = express.Router();
const upload = multer();
接下来,我们将配置OpenAI并创建一个新的配置实例。我们需要一个OpenAI秘钥,我们必须将其放在这里作为API密钥。您可以从这里获取秘钥。
const configuration = new Configuration({
apiKey: process.env.OPENAI_KEY,
});
现在,我们创建一个异步函数,它接受包含歌曲数据的缓冲区,并在调用其API时返回从OpenAI的Whisper模型接收到的响应。
async function transcribe(buffer) {
const openai = new OpenAIApi(configuration);
const response = await openai.createTranscription(
buffer, // 要转录的音频文件。
"whisper-1", // 用于转录的模型。
undefined, // 用于转录的提示。
'json', // 转录的格式。
1, // 温度
'en' // 语言
)
return response;
}
如上所示,我们首先使用我们在代码中之前定义的配置创建OpenAI类的新实例。然后,我们调用OpenAI的createTranscription函数,并在此使用await关键字,以便在继续之前等待先获取响应。
我们将所需的参数传递给函数,其中包括包含歌曲数据的缓冲区,以及要用于转录的模型,在我们的情况下是whisper-1。然后,我们将提示保留为空。如果您愿意,您也可以给出提示,这将有助于模型通过具有与您提供的提示类似风格的提示来更好地转录音频。我们将定义我们接收的数据类型为json,将温度设置为1,并定义我们希望输出的语言。
接下来,我们将定义GET请求。我们使用sendFile发送一个包含我们的表单的HTML文件,用户可以在其中上传音频文件。我们稍后将构建HTML文件。我们在基本URL上提供它。
router.get("/", (req, res) => {
res.sendFile(path.join(__dirname, "../public", "index.html"));
});
接下来,我们定义POST请求,它将处理音频文件的上传。我们使用multer中间件来管理文件上传部分。然后,我们从音频文件创建一个缓冲区,该缓冲区将包含音频文件的数据,以一种可以发送到OpenAI API的格式。然后,我们使用上传的音频文件的原始名称为缓冲区设置一个名称。
然后,我们调用transcribe函数,一旦我们获得响应,我们就向客户端发送一个JSON。我们将转录和音频文件名称发送回前端。我们还有一个catch方法来处理任何错误。
router.post("/", upload.any('file'), (req, res) => {
audio_file = req.files[0];
buffer = audio_file.buffer;
buffer.name = audio_file.originalname;
const response = transcribe(buffer);
response.then((data) => {
res.send({
type: "POST",
transcription: data.data.text,
audioFileName: buffer.name
});
}).catch((err) => {
res.send({ type: "POST", message: err });
});
});
```最后,我们导出`router`模块,这样其他文件就可以导入它们了。
```ini
module.exports = router;
所以,api.js文件的完整代码如下:
const express = require("express");
const multer = require("multer");
const { Configuration, OpenAIApi } = require("openai");
const router = express.Router();
const upload = multer();
const configuration = new Configuration({
apiKey: process.env.OPENAI_KEY,
});
async function transcribe(buffer) {
const openai = new OpenAIApi(configuration);
const response = await openai.createTranscription(
buffer, // 要转录的音频文件。
"whisper-1", // 用于转录的模型。
undefined, // 用于转录的提示。
'json', // 转录的格式。
1, // 温度
'en' // 语言
)
return response;
}
router.get("/", (req, res) => {
res.sendFile(path.join(__dirname, "../public", "index.html"));
});
router.post("/", upload.any('file'), (req, res) => {
audio_file = req.files[0];
buffer = audio_file.buffer;
buffer.name = audio_file.originalname;
const response = transcribe(buffer);
response.then((data) => {
res.send({
type: "POST",
transcription: data.data.text,
audioFileName: buffer.name
});
}).catch((err) => {
res.send({ type: "POST", message: err });
});
});
module.exports = router;
现在,我们已经完成了所有的后端部分。接下来,我们将编写HTML文件,并编写一些前端JavaScript代码来处理表单提交、数据保存在本地存储中以及从本地存储中检索数据。
我们创建一个public文件夹,在其中创建两个HTML文件 - index.html和transcribe.html。
我们将从index.html文件开始:
index.html
在这个文件中,我们将构建一个页面,显示一个上传音频文件的表单。我们将使用Bootstrap CSS,因此我们通过CDN导入它。我们还通过CDN在HTML文件的末尾包含了Bootstrap JS。
然后,我们创建一个简单的卡片,要求用户上传音频文件。我们确保提交的文件是.mp3格式,因为这是OpenAI API接受的唯一格式。我们显示一个按钮,点击按钮后提交表单。
然后,我们有JavaScript代码,用于处理表单提交。首先,我们通过阻止表单提交事件的默认行为来阻止页面刷新。然后,我们获取表单数据,即音频文件,并将其作为POST请求发送到后端。然后,我们等待响应并将其存储在一个数据变量中。
如果数据中有可用的转录内容,我们将转录和音频文件名保存在本地存储中,以便在下一个需要显示转录的页面上访问它们。有多种方法可以传递信息,比如我们可以通过URI传递信息,但在这里我们使用本地存储来传递信息。
在将数据保存到本地存储后,我们更改窗口位置以加载transcribe.html文件。
<!DOCTYPE html>
<html>
<head>
<title>Speech to Text</title>
<link href="https://cdn.jsdelivr.net/npm/[email protected]/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-GLhlTQ8iRABdZLl6O3oVMWSktQOp6b7In1Zl3/Jr59b6EGGoI1aFkw7cmDA6j6gD" crossorigin="anonymous">
</head>
<body style="background-color: #f2f2f2;">
<div class="container mt-5">
<div class="row justify-content-center">
<div class="col-md-6">
<div class="card">
<div class="card-header">
Upload Audio File
</div>
<div class="card-body">
<form id="transcription-form" enctype="multipart/form-data">
<div class="form-group">
<label for="file-upload"><b>Select file:</b></label>
<input id="file-upload" type="file" name="file" class="form-control-file" accept=".mp3" style="margin-bottom: 20px">
</div>
<input type="submit" value="Transcribe" class="btn btn-primary"></input>
</form>
</div>
</div>
</div>
</div>
</div>
<script>
document.getElementById("transcription-form").addEventListener("submit", async function (event) {
event.preventDefault();
const formData = new FormData(event.target);
const response = await fetch("/", {
method: "POST",
body: formData,
});
const data = await response.json();
if (data.transcription) {
localStorage.setItem("transcription", data.transcription);
localStorage.setItem("audioFileName", data.audioFileName);
window.location.href = "/transcribe.html";
}
else {
console.error("Error:", data.message);
}
});
</script>
<script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/js/bootstrap.bundle.min.js" integrity="sha384-w76AqPfDkMBDXo30jS1Sgez6pr3x5MlQ1ZAGC+nuZB+EYdgRZgiwxhTBTkF7CXvN" crossorigin="anonymous"></script>
</body>
</html>
以上代码构建了index.html文件,它将向用户显示一个表单,用户可以在其中上传音频文件。
下面是一个屏幕截图,展示了它的外观:
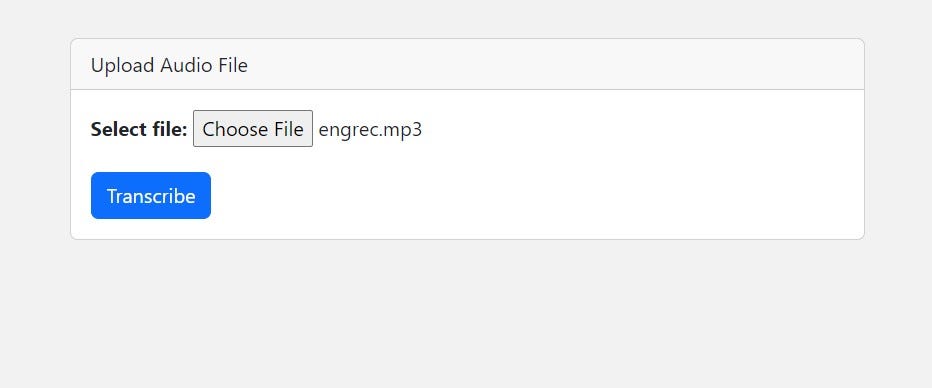
接下来,我们将构建transcribe.html文件。
transcribe.html
在这个文件中,我们将显示用户上传的音频文件的转录内容。所以,我们将再次使用Bootstrap CSS和JS,以便通过CDN包含它们。
然后,我们定义一些自定义的CSS来美化元素,使它们看起来更好。然后,我们在一个容器中显示音频文件名和该音频文件的转录内容。
在页面底部的JavaScript代码中,我们从本地存储中获取音频文件名和转录内容,并使用相应的id将这些数据推送到HTML元素中。
<!DOCTYPE html>
<html>
<head>
<title>Transcription</title>
<link href="https://cdn.jsdelivr.net/npm/[email protected]/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-GLhlTQ8iRABdZLl6O3oVMWSktQOp6b7In1Zl3/Jr59b6EGGoI1aFkw7cmDA6j6gD" crossorigin="anonymous">
<style>
h1 {
margin-top: 20px;
margin-bottom: 10px;
font-size: 2.5rem;
font-weight: bold;
color: #333;
}
p {
font-size: 1.2rem;
color: #333;
margin-bottom: 30px;
}
.container {
margin-top: 50px;
margin-bottom: 50px;
max-width: 600px;
padding: 30px;
background-color: #fff;
box-shadow: 0 0 10px rgba(0,0,0,0.2);
border-radius: 5px;
}
</style>
</head>
<body style="background-color: #f2f2f2;">
<div class="container">
<h1>Audio File:</h1>
<p id="audioFileName"></p>
<h1>Transcription:</h1>
<p id="transcription"></p>
</div>
<script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/js/bootstrap.bundle.min.js" integrity="sha384-w76AqPfDkMBDXo30jS1Sgez6pr3x5MlQ1ZAGC+nuZB+EYdgRZgiwxhTBTkF7CXvN" crossorigin="anonymous"></script>
<script>
const audioFileName = localStorage.getItem("audioFileName");
const transcription = localStorage.getItem("transcription");
document.getElementById("audioFileName").innerHTML = audioFileName;
document.getElementById("transcription").innerHTML = transcription;
</script>
</body>
</html>
我尝试转录了两个不同的小音频文件,这些文件是我个人录制的 - 一个是英语,另一个是印地语。虽然第二个音频文件是用印地语录制的,但我希望将结果显示为英语,以测试其翻译能力。它在转录这两个音频文件时非常准确。虽然在多次运行中,有时会产生不正确的转录,但很多时候,转录内容大部分是正确的。
我在下面附上了转录的屏幕截图。这些转录并不完全正确,但我会说它在转录我实际录制的音频文件方面大约有85-90%的准确率。
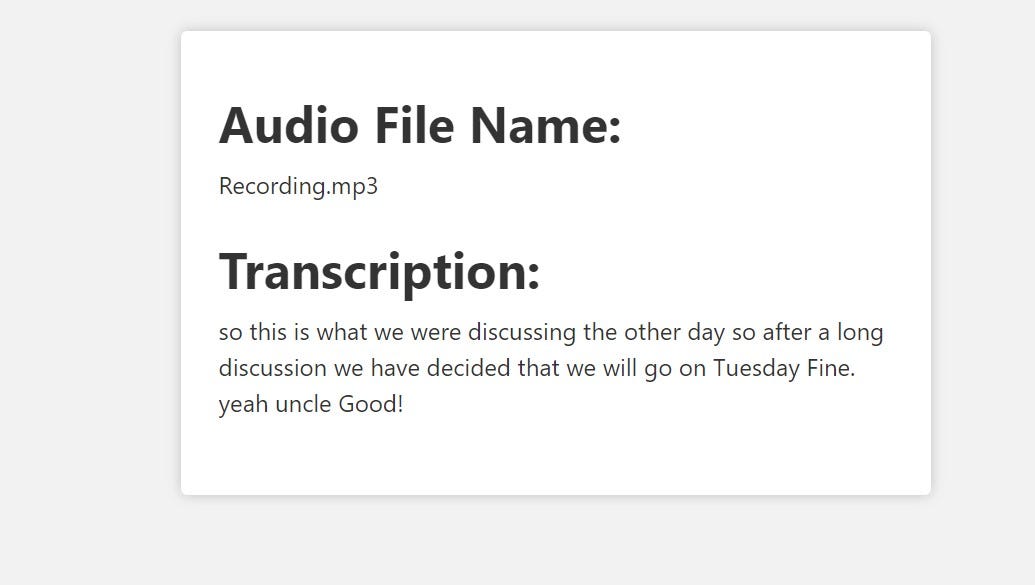
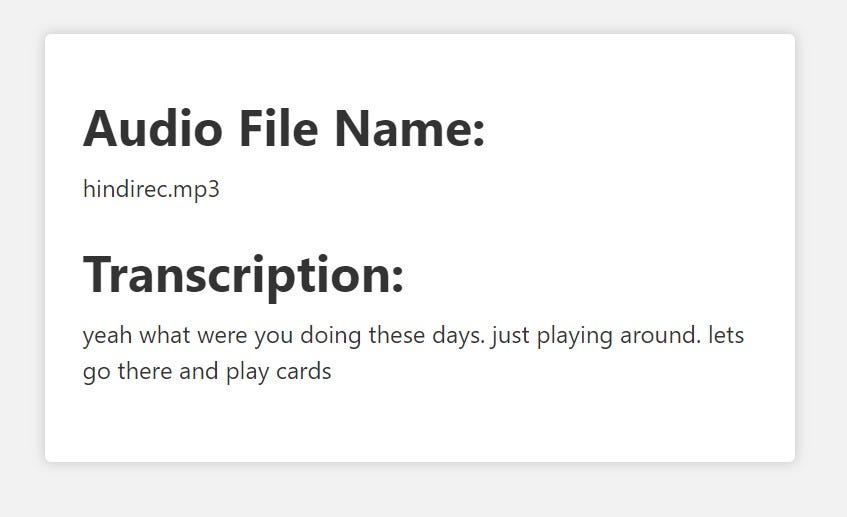
因此,我们成功地使用OpenAI的API和Node.js构建了一个语音转文本的Web应用程序。我希望您在构建过程中有所收获,并从本文中学到了一些新知识。您还可以更改参数以进行调整,并比较结果,以更好地了解在不同情况下哪种方式效果更好。