进行Web Scraping可能看起来是一项复杂而繁琐的任务,无论您是否具备编程知识。然而,ChatGPT和Code Interpreter插件将为我们节省许多代码和头疼的时间,因为它可以在几秒钟内从网页中提取信息,只需一个简单的提示。
接下来,我们将通过三个示例,逐步解释如何使用ChatGPT以简单实用的方式进行Web Scraping。

让我们开始吧...
Walmart
我们将使用Walmart在线商店的“Shop all Back to School”部分。我在下面提供了直接链接:
步骤1:定义要提取的字段
我们需要定义我们希望提取的信息。这非常重要,因为它将帮助我们稍后在ChatGPT中构建我们的提示。
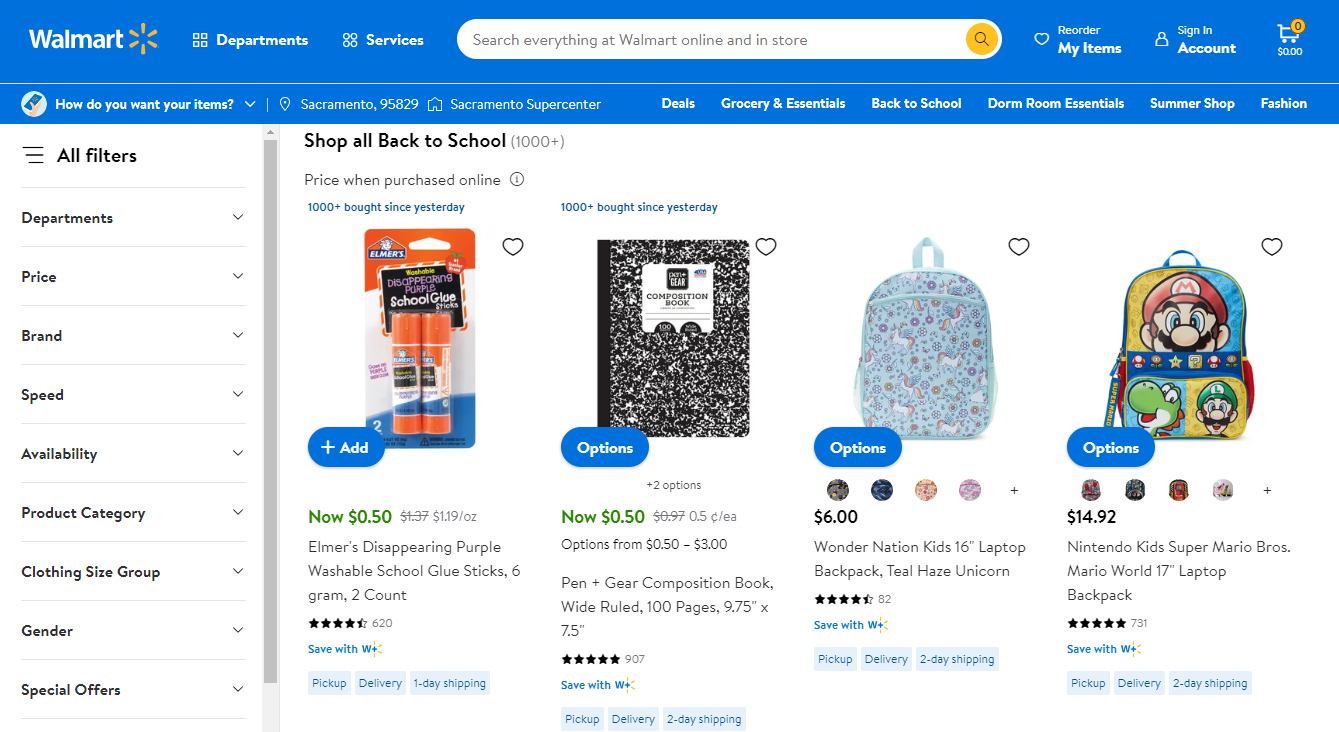
在这种情况下,我们将抓取产品名称和价格。
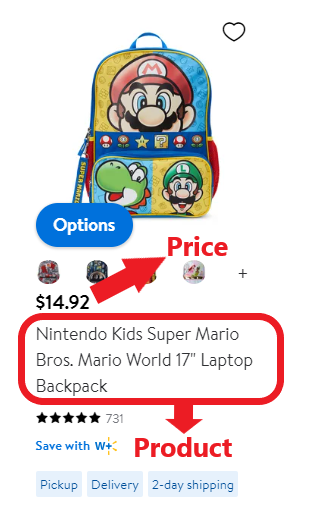
步骤2:检查代码
在这里,我们需要定义一个产品的代码(作为将其输入到ChatGPT中的示例)
但在我们这样做之前,请记住以下内容:
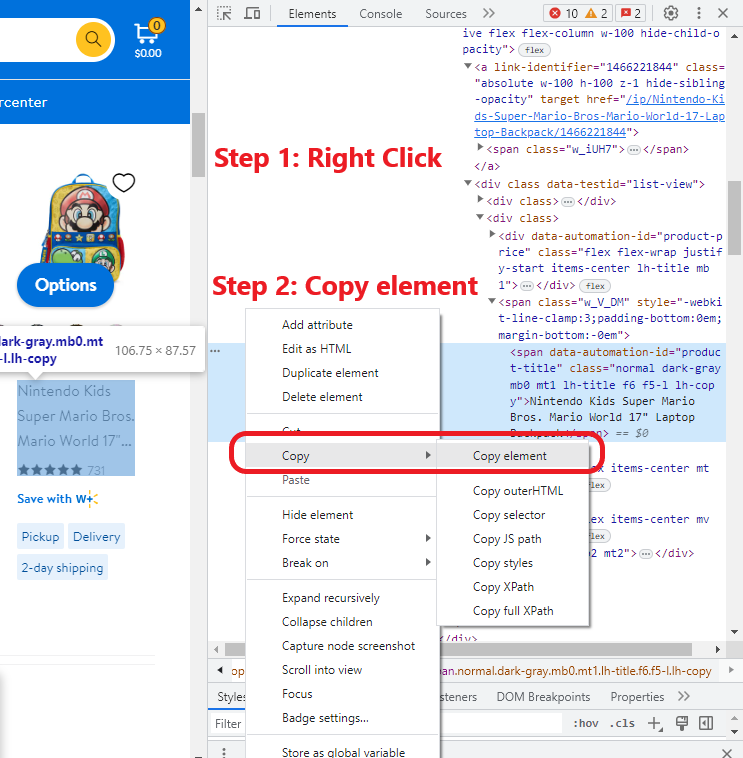
要在Chrome中访问检查元素功能,如果您使用Windows,则有两个键盘快捷键选项:
a) Ctrl + Shift + c
或
b) Ctrl + Shift + i
如果您使用macOS,请使用:
a) alt + Command + i
或
b) Option + Command + i
记住这一点后,我们现在可以检查Walmart网站。让我们回顾一下各个部分:
i)产品名称
在这种情况下,我们需要在代码中找到要抓取的产品名称。
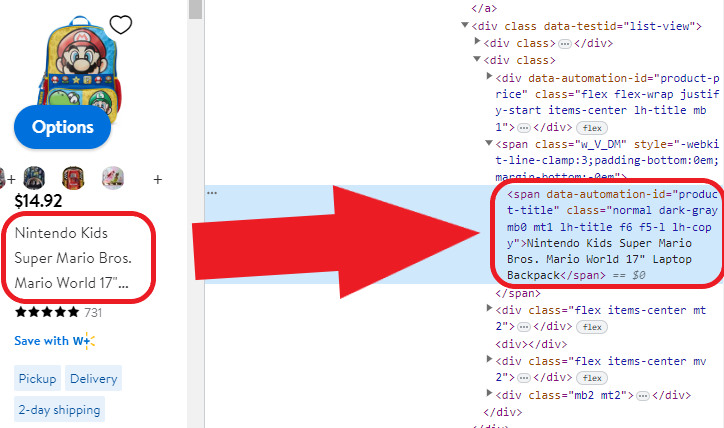
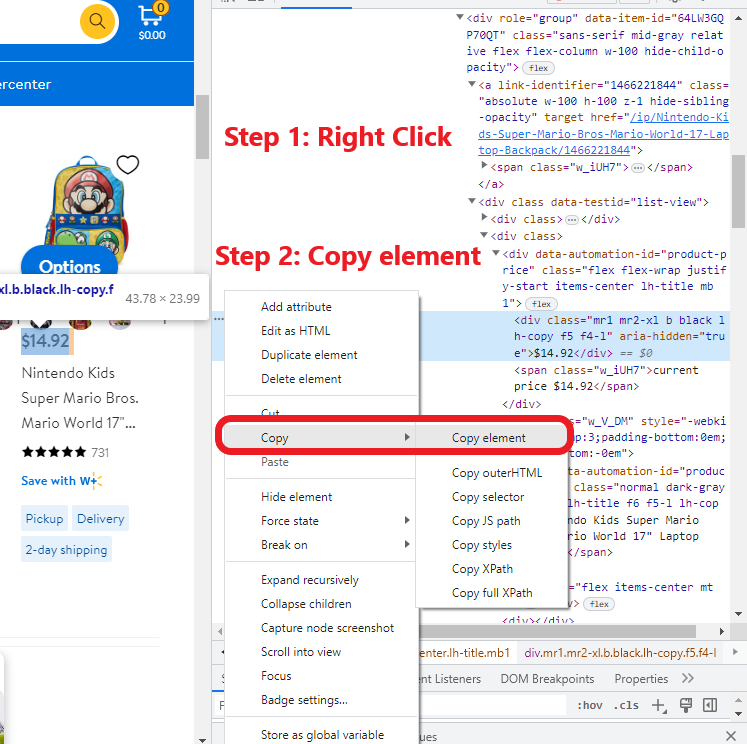
让我们复制它,然后将其包含在我们的提示中。要复制_span标签_,我们将鼠标悬停在该部分上,右键单击,然后会出现以下内容:
现在我们只需复制它,并为了方便起见,我们将它保存在手边,以便稍后将其包含在提示中
Nintendo Kids Super Mario Bros. Mario World 17" Laptop Backpack
ii)价格
我们将对价格字段执行相同的操作
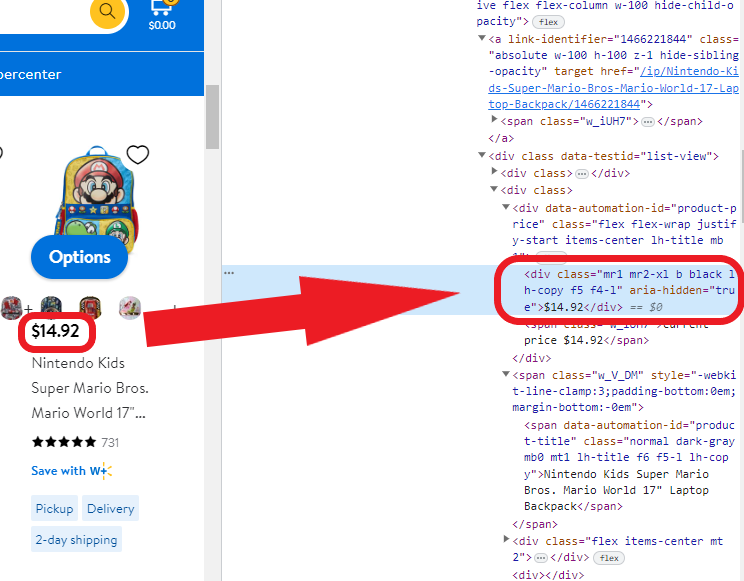
我们将保留价格字段的复制元素以供以后使用
如果您需要从网页中提取更多部分,则应重复我们为产品名称和价格执行的相同步骤
提示: 要在代码区域内快速定位要检查的字段,只需将鼠标放在字段上,右键单击,检查选项将被启用
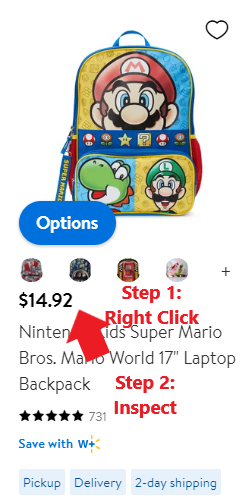
步骤3:保存HTML文件
由于我们将使用Code Interpreter进行工作,因此我们需要将文件附加到其中。因此,我们将保存要抓取的页面作为HTML文件。
返回页面并使用键盘快捷键Ctrl + S(适用于Windows和macOS)
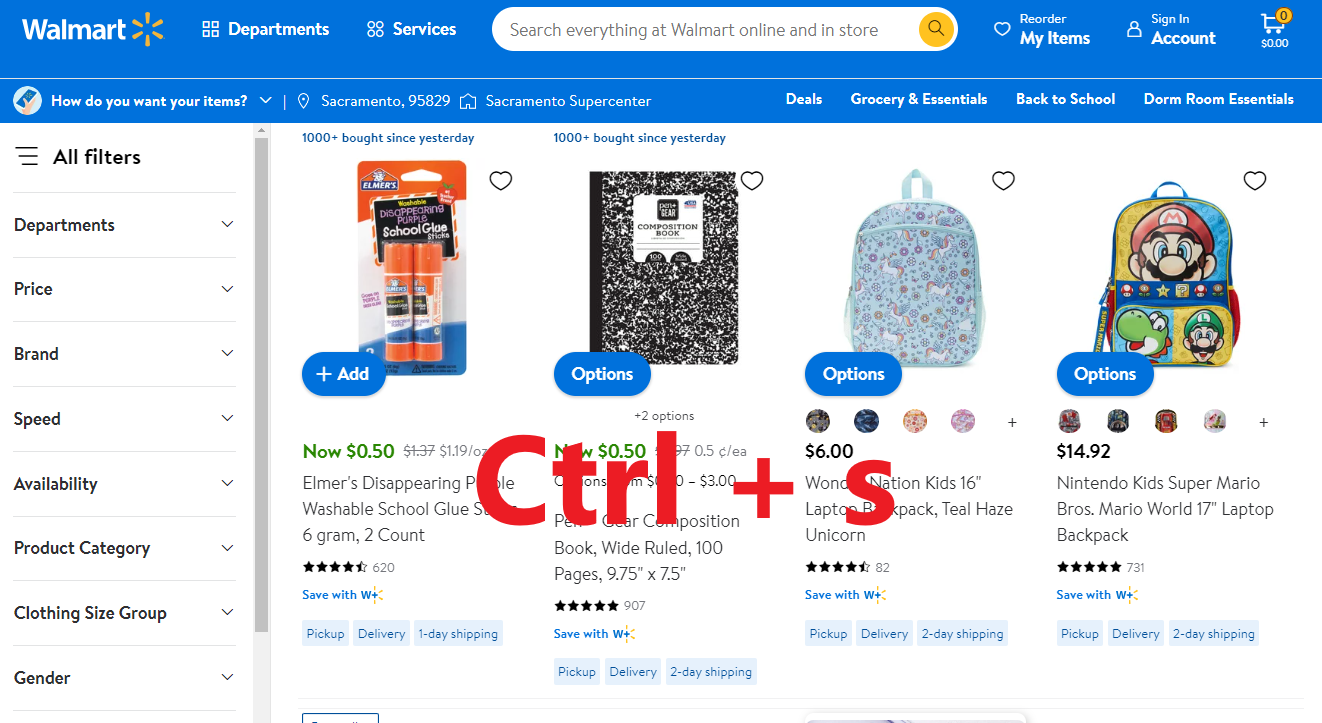
接下来,将文件以HTML格式保存在本地文件夹中

步骤4:上传HTML文件+生成提示
现在,我们已经定义了要抓取的字段及其在Web上的代码,让我们在ChatGPT中构建提示
如果您尚未激活Code Interpreter,请按照一些说明进行操作。否则,我建议您跳过此部分,直接进入构建提示
i)设置
ii)打开Code Interpreter
在ChatGPT中激活Code Interpreter后,让我们上传我们在步骤3中保存的HTML文件


现在,让我们构建提示,考虑到产品名称和价格,以及每个部分的代码(如果有疑问,请查看步骤2)

**提示:**从HTML文件中提取产品名称和价格,将数据放入表格中,并将其导出到CSV文件中
这是一个产品的元素: Nintendo Kids Super Mario Bros. Mario World 17" Laptop Backpack
这是价格的元素:
如果产品的价格缺失,请将该价格作为null数据
在提示中,我们可以看到有04个部分。
在第一个段落中,我指定我已加载了一个HTML文件,并要求它抓取产品名称和价格。在这样做之后,我要求它将数据导出到CSV文件中
在第二和第三段中,我为ChatGPT提供了相应结构的示例,用于产品名称和价格字段。我们可以看到每个产品都是一个_span标签,价格是一个div标签_
在最后一段中,我要求它在找到价格的_null值_时将其分配为null数据
请记住这个提示,因为接下来的示例将具有相同的结构,只会更改字段及其代码
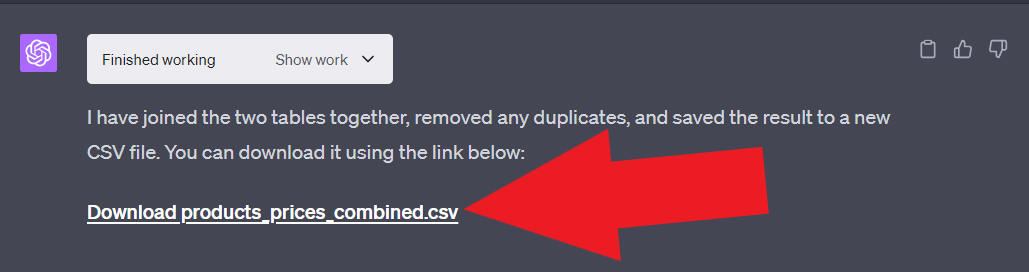
结果:
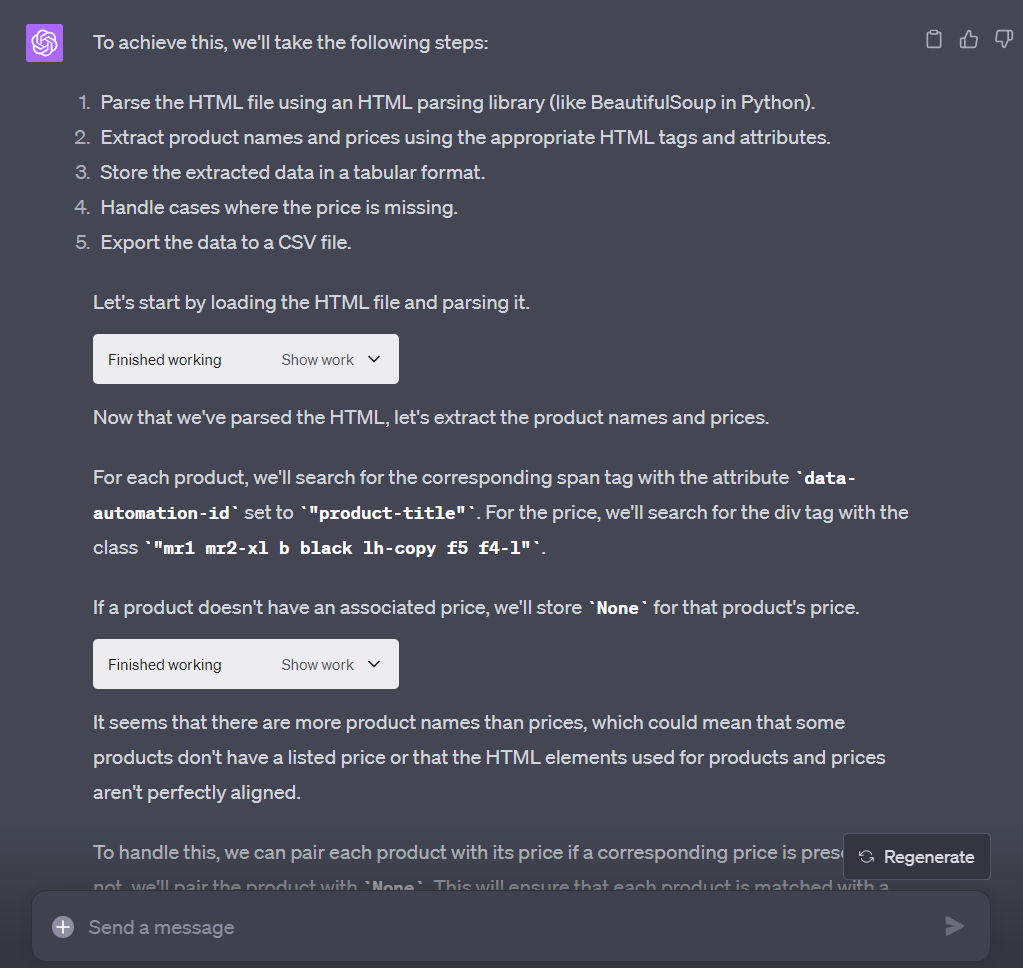
下载并打开_CSV_文件
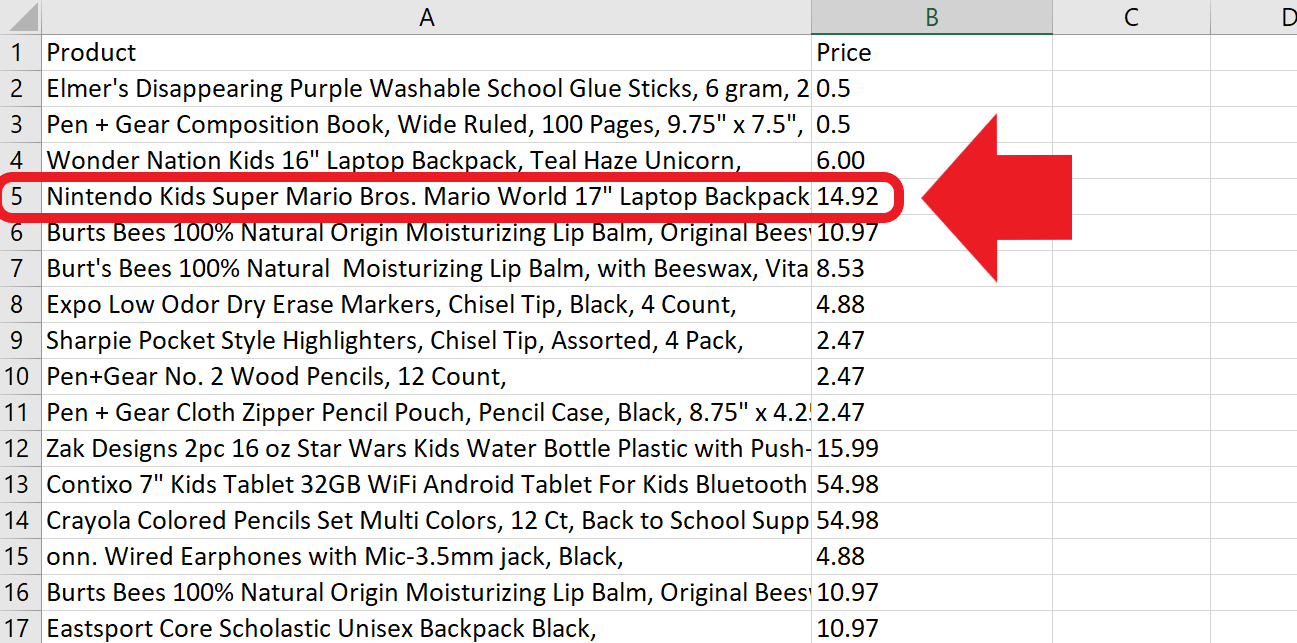
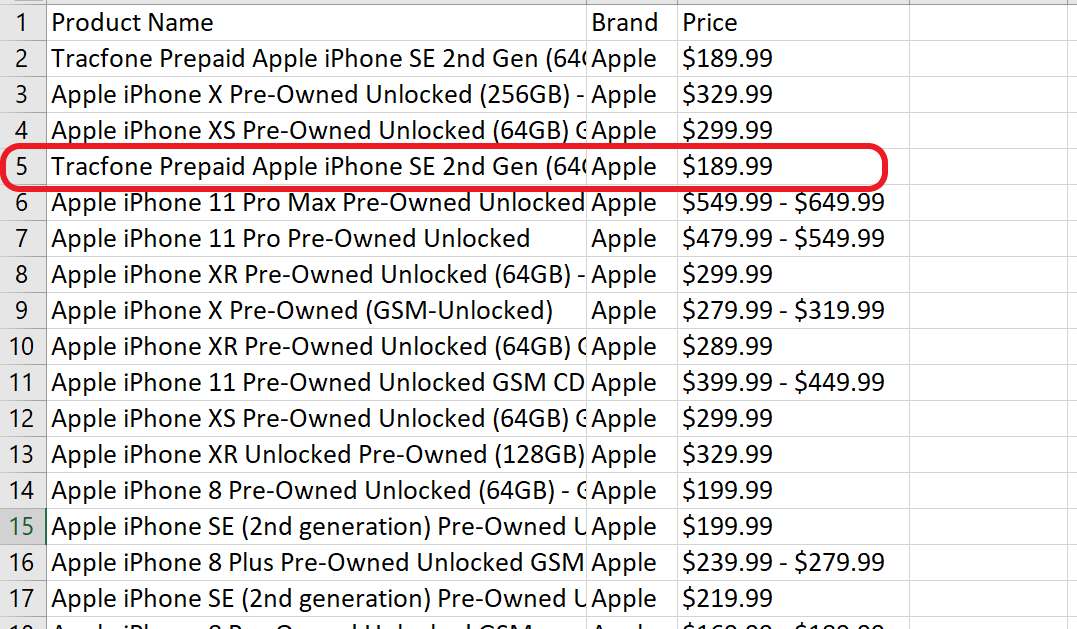
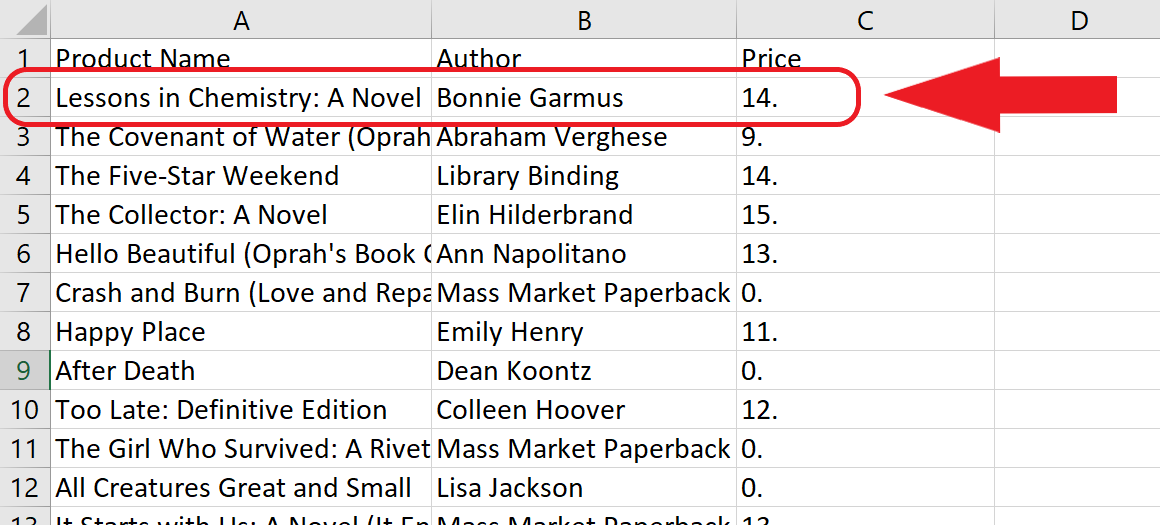
最后,我们成功地对产品及其相应价格进行了Web Scraping,并将其导出到了一个CSV文件中,如表格图像所示。请注意,我们用作示例的产品已包含在内!
奖励
前面的步骤使我们能够从Walmart网站的第一个(01)页面进行Web Scraping。但是,如果我们想从第二(02)页面提取数据,我们执行相同的先前步骤,但不要忘记在这个新页面中识别一个产品,并将其作为示例包含在提示中
Walmart网站Back to School部分的第02页
i)产品名称

Minecraft Boys Cliff Goats Graphic T-Shirt, 2-Pack, Sizes 4–18
ii)价格
与第一页一样,我们需要将此第二(02)页的文件以_HTML_格式保存(如果您有任何疑问,请查看步骤03)
提示
从HTML文件中提取产品名称和价格,将数据放入表格中,并将其导出到CSV文件中。
这是一个产品的元素: Minecraft Boys Cliff Goats Graphic T-Shirt, 2-Pack, Sizes 4–18
这是价格的元素:

如果您希望将两个表格合并为一个表格,可以要求ChatGPT执行以下操作:
Target
在第二个示例中,我们将从Target网站的手机部分进行Web Scraping。如果有任何疑问,请直接参考第一个Walmart示例的步骤。
这是直接链接:
步骤1:确定要提取的字段
a)产品 b)品牌 c)价格
现在,让我们检查每个目标字段的代码级别(请参阅步骤2)
检查的键盘快捷键:Ctrl + Shift + c(Windows)或Alt + Command + i(macOS)
步骤2:检查代码
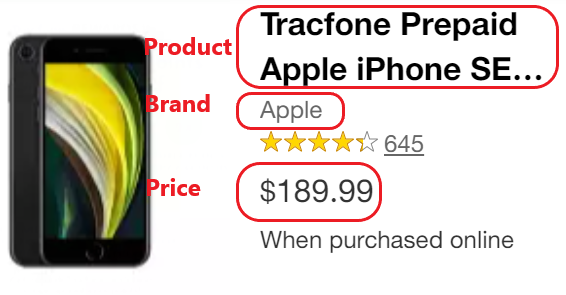
i)产品
我们找到了代码和标签。我们复制并保留代码,以便稍后将其纳入ChatGPT提示中(如果有疑问,请查看第一个Walmart示例的步骤02)
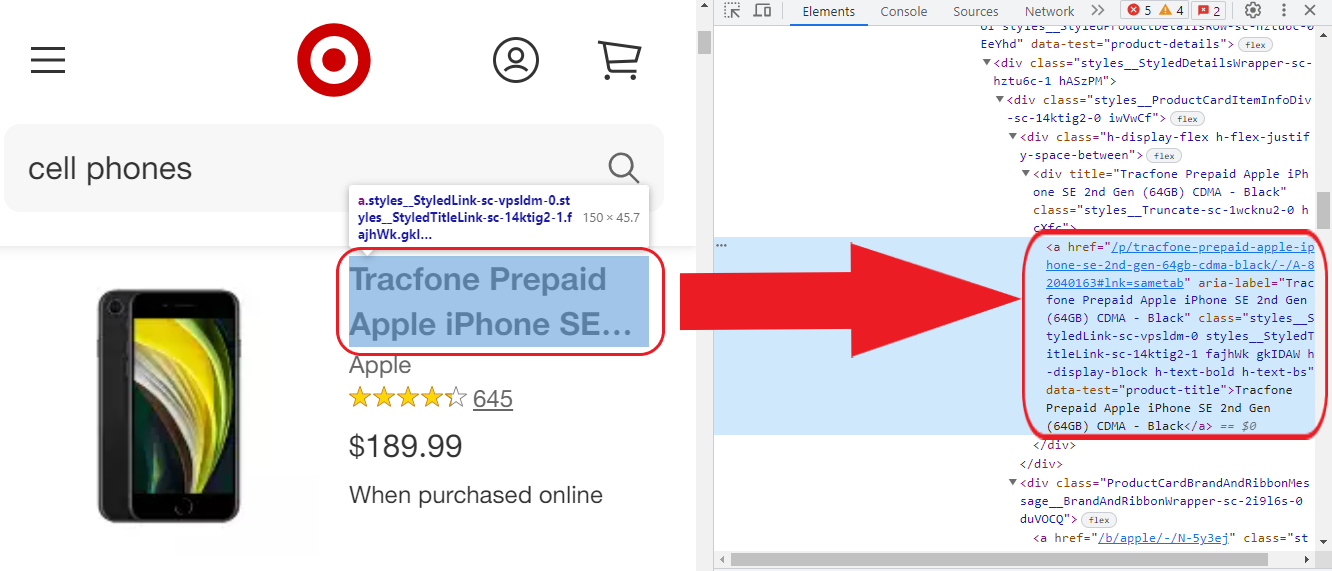
Tracfone Prepaid Apple iPhone SE 2nd Gen (64GB) CDMA - Black
ii)品牌
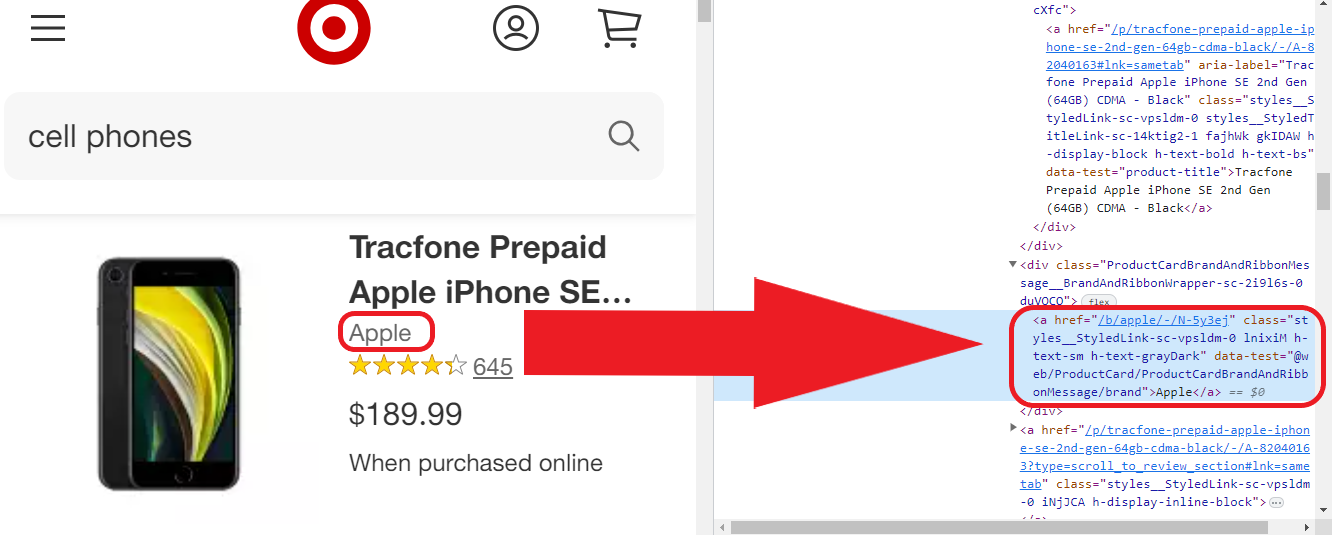
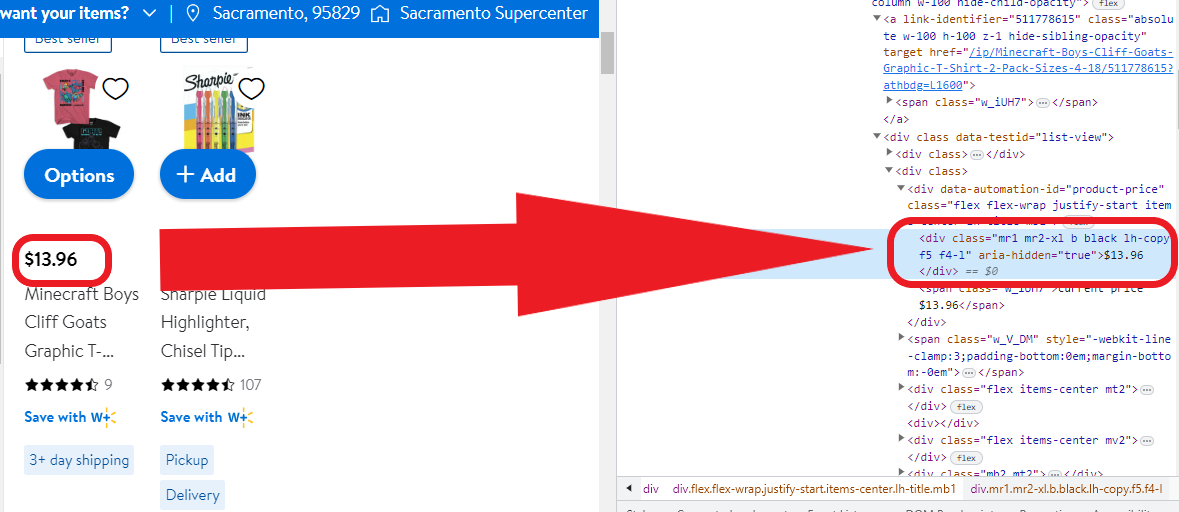
iii)价格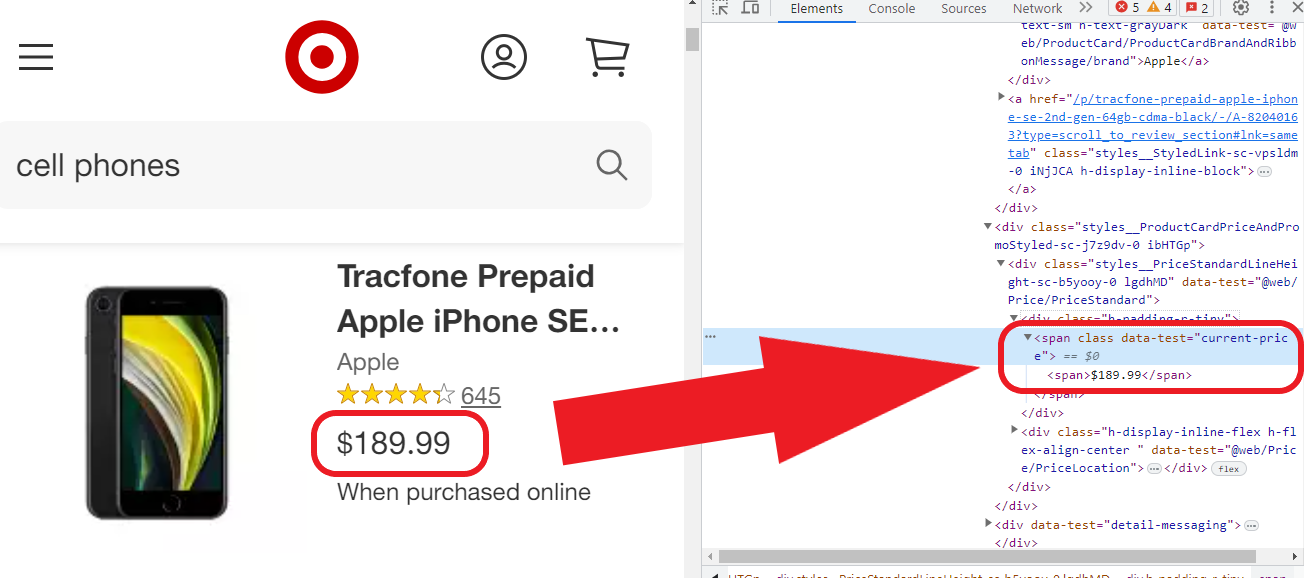
$189.99
第三步:保存HTML文件
将要抓取的页面保存为HTML文件(参考Walmart示例的第三步)
第四步:上传HTML文件+生成提示
我们将构建提示,但与之前的示例不同,我们将包括手机品牌字段(参见Walmart示例的第四步)。
加载HTML文件,并添加要抓取的每个字段的代码(产品名称、品牌和价格)
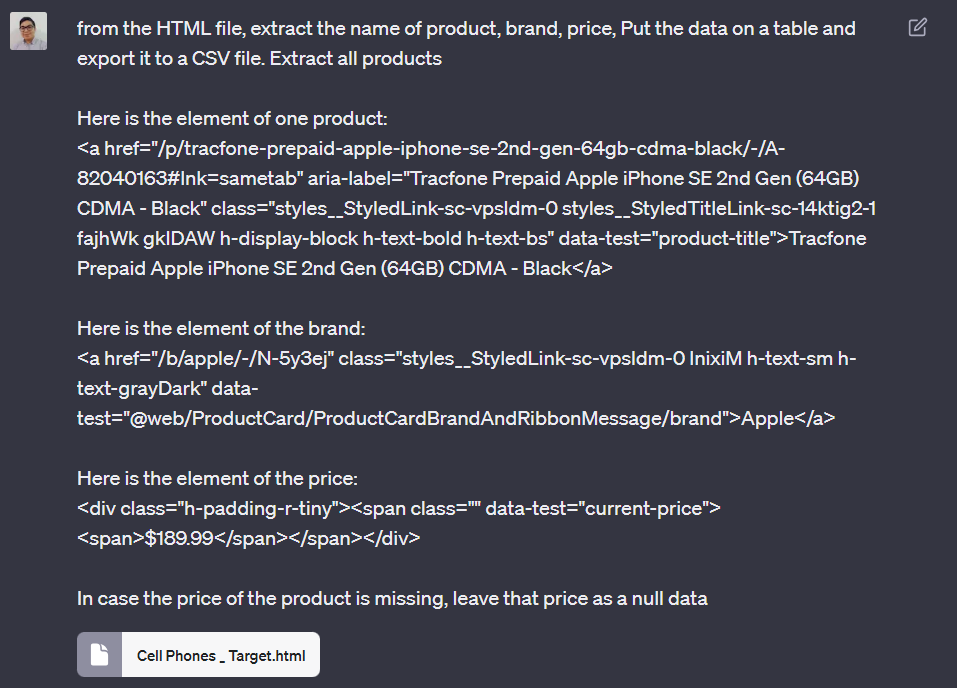
提示: 从HTML文件中提取产品名称、品牌和价格,将数据放在表格中并导出为CSV文件。提取所有产品。
这是一个产品的元素: Tracfone Prepaid Apple iPhone SE 2nd Gen (64GB) CDMA - Black
这是品牌的元素: Apple
这是价格的元素:
结果
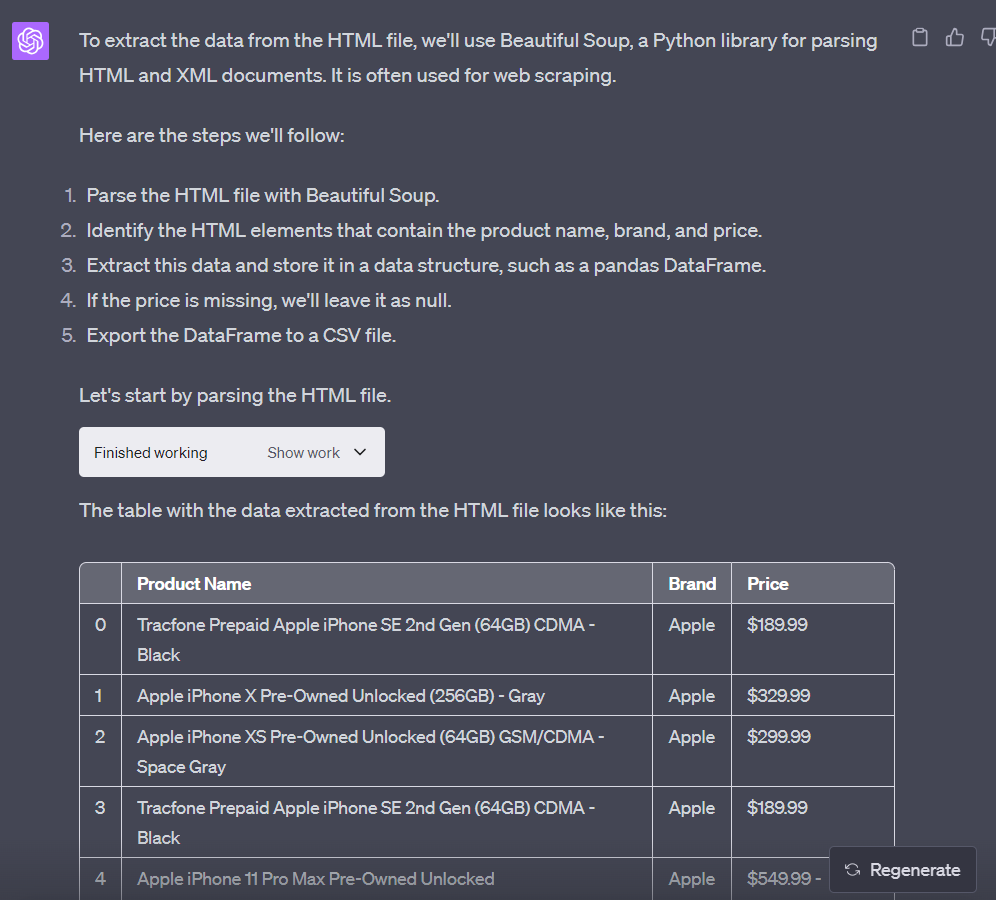
下载并打开_CSV_文件
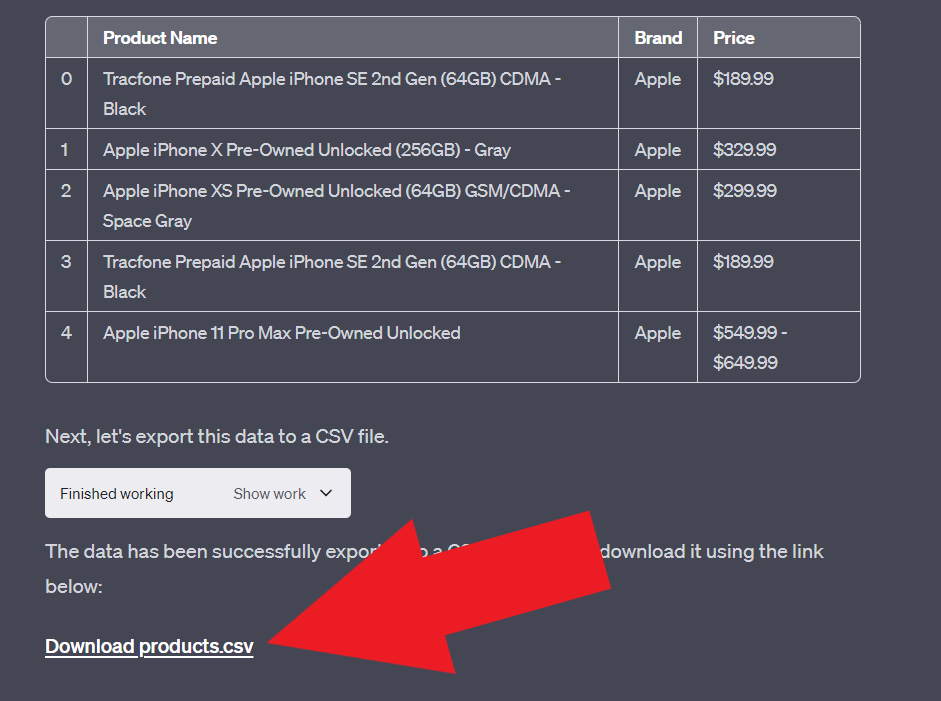
结果很好,我们能够从Target网站上抓取到所有数据
亚马逊
在这个最后的例子中,我们将对Kindle图书进行网络抓取。这可能很有趣,可以看到哪些书最受欢迎,然后使用ChatGPT创建具有不同热门主题的故事。
这是链接:
第一步:确定要提取的字段
a) 产品或标题 b) 作者 c) 价格

第二步:检查代码
i) 产品或标题:
我们找到代码和标签。我们复制并保留代码,以便稍后将其合并到ChatGPT提示中(如果有疑问,请参阅第一个Walmart示例的第2步)
检查的键盘快捷键是:Ctrl + Shift + c(Windows)或Alt + Command + i(macOS)。有关更多详细信息,请参阅第2步
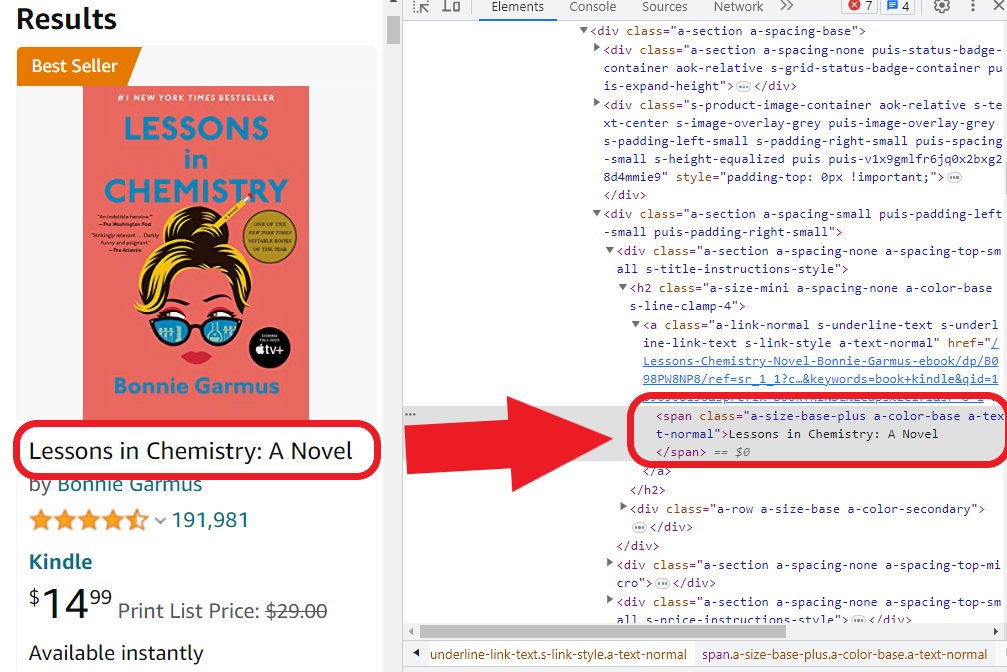
Lessons in Chemistry: A Novel
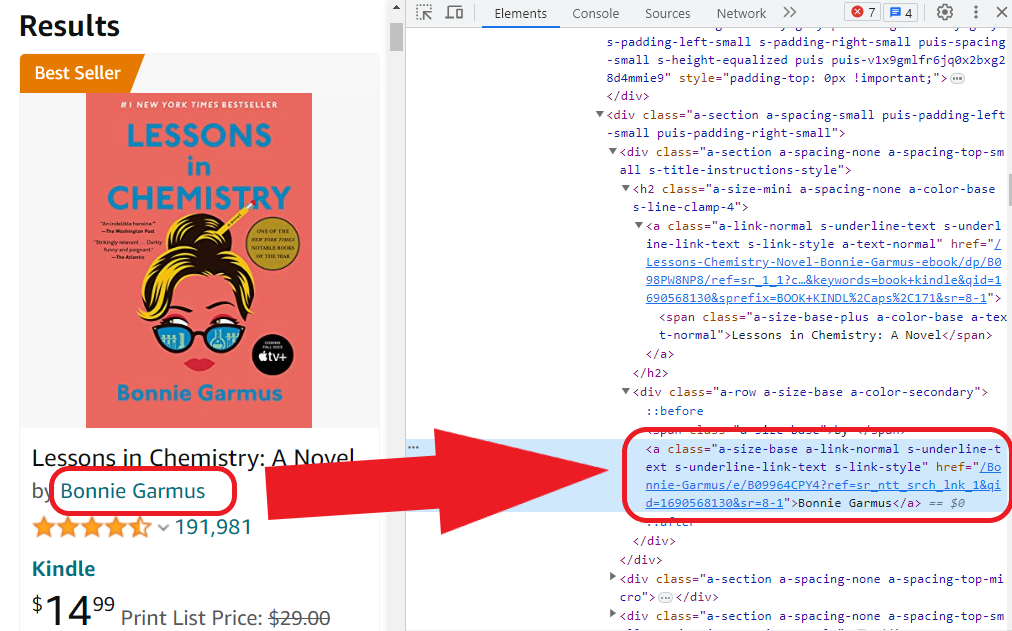
ii) 作者
iii) 价格
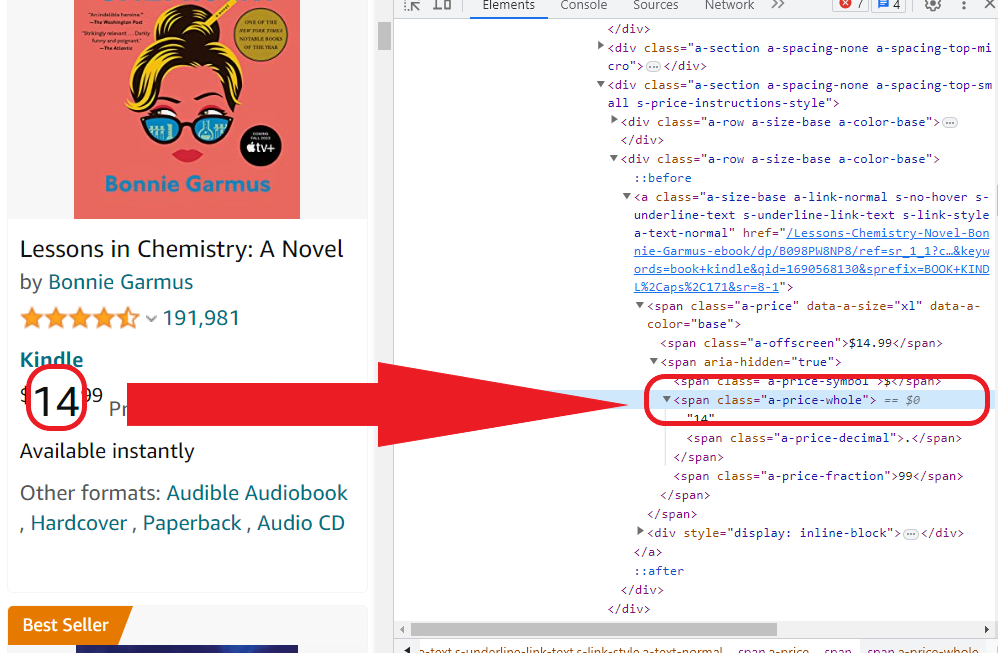
在此示例中,我们只提取价格的整数部分
14.
第三步:保存HTML文件
我们将要抓取的网页保存为HTML文件。为此,我们使用Ctrl + S快捷键保存要保存的页面。不要忘记以HTML格式保存文件(请参阅Walmart示例的第3步中的详细信息)
第四步:上传HTML文件+生成提示
现在,让我们根据我们想要从亚马逊网页中提取的字段构建提示,特别是从其Kindle图书部分。在这种情况下,我们想要提取标题、作者和价格。
接下来,我们加载HTML文件,并添加代码来抓取每个所需字段(标题、作者和价格)
提示: 从HTML文件中提取产品名称、作者和价格,将数据放在表格中并导出为CSV文件。
这是一个产品的元素: Lessons in Chemistry: A Novel
这是作者的元素: Bonnie Garmus
这是价格的元素: 14.
如果产品的价格缺失,请将该价格保留为空数据
让我们看到,我们所见的示例中的提示具有相同的结构
结果
我们下载_CSV_文件
我们成功了!
总结和建议
-
如果我们尝试直接将URL放入ChatGPT中,即使启用了Code Interpreter,它也无法执行Web Scraping。因此,我们将要抓取的页面下载为HTML。
-
ChatGPT可能最初无法识别要提取的字段的标签,并且可能给出错误的信息。在这种情况下,我建议打开另一个对话,并再次运行提示。
-
我们应该记住,Code Interpreter使用Python和诸如BeautifulSoup之类的库进行Web Scraping。
-
这种方法并不旨在取代传统的Web Scraping,但它将节省我们的时间和代码行数。
-
通过上述3个Web Scraping示例中所见,我们可以看到这对于编程人员以及对这个领域几乎没有或没有任何知识的人来说都是有用的。
-
通过Web Scraping,我们可以实现一些有趣的事情,正如我上面提到的,我们可以专注于_dropshipping_,使用_畅销书_来创建_Kindle图书_,分析竞争对手的价格,跟踪特定产品等等。
这个完整的指南旨在为希望使用ChatGPT进行Web Scraping的人提供一种替代方法。不需要具备先前的编程知识,只需要好奇心和耐心。