在人工智能领域迅速发展的今天,多模态模型正在设定整合视觉和文本数据的新标准。最新的突破之一是 Phi-3-Vision-128K-Instruct,这是一种先进的开放式多模态模型,进一步推动了 AI 在图像和文本处理方面的能力边界。该模型专注于文档提取、光学字符识别(OCR)以及一般图像理解,可以彻底改变我们处理来自 PDF、图表、表格等结构化或半结构化文档的信息方式。
接下来,我们将深入探讨 Phi-3-Vision-128K-Instruct 的技术细节,了解其架构、技术要求、负责任的使用考量,并探索如何利用它简化诸如文档提取、PDF 解析和基于 AI 的数据分析等复杂任务。
什么是 Phi-3-Vision-128K-Instruct?
Phi-3-Vision-128K-Instruct 属于 Phi-3 模型系列,专为处理多模态数据而设计,支持128,000 个 Token的上下文长度。该模型结合了文本和视觉数据,非常适合需要同时解析文本和图像的任务。其开发过程中使用了5000 亿个训练 Token,并结合了高质量的合成数据与筛选后的公开数据源。通过精细的训练过程,包括监督微调和偏好优化,该模型旨在提供精准、可靠和安全的 AI 解决方案。
Phi-3-Vision-128K-Instruct 拥有42 亿个参数,其架构包括图像编码器、连接器、投影模块和 Phi-3 Mini 语言模型,使其成为一个功能强大且适用广泛的选择。
核心应用场景
该模型的主要应用涵盖多个领域,特别适合以下场景:
-
文档提取和 OCR: 高效地将文本图像或扫描文档转换为可编辑的格式。它能够处理复杂布局的表格、图表等,是数字化实体文档和自动化数据提取的有力工具。
-
一般图像理解: 解析视觉内容,识别对象、理解场景、提取相关信息。
-
内存/计算受限环境: 在计算能力或内存有限的情况下运行 AI 任务,保持高效性能。
-
低延迟场景: 减少实时应用程序中的处理延迟,例如实时数据源、聊天助手或流媒体内容分析。
如何开始使用 Phi-3-Vision-128K-Instruct
要使用 Phi-3-Vision-128K-Instruct,您需要在开发环境中设置必要的库和工具。该模型已集成到 Hugging Face transformers 库的开发版本(4.40.2)中。在深入了解代码示例之前,请确保您的 Python 环境安装了以下软件包:
# 必需的软件包
flash_attn==2.5.8
numpy==1.24.4
Pillow==10.3.0
Requests==2.31.0
torch==2.3.0
torchvision==0.18.0
transformers==4.40.2
加载模型时,可以更新本地的 transformers 库,也可以直接从源代码克隆并安装:
pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers
以下是如何利用该模型进行文档提取和文本生成的代码示例。
加载模型的示例代码
以下 Python 代码演示了如何初始化模型并开始进行推理。我们通过类和函数来保持代码的简洁和条理:
from PIL import Image
import requests
from transformers import AutoModelForCausalLM, AutoProcessor
class Phi3VisionModel:
def __init__(self, model_id="microsoft/Phi-3-vision-128k-instruct", device="cuda"):
"""
使用指定的模型 ID 和设备初始化 Phi3VisionModel。
Args:
model_id (str): Hugging Face 模型中心预训练模型的标识符。
device (str): 要加载模型的设备("cuda" 用于 GPU 或 "cpu")。
"""
self.model_id = model_id
self.device = device
self.model = self.load_model() # 在初始化期间加载模型
self.processor = self.load_processor() # 在初始化期间加载处理器
def load_model(self):
"""
加载具有因果语言建模能力的预训练语言模型。
Returns:
model (AutoModelForCausalLM): 加载的模型。
"""
print("加载模型...")
return AutoModelForCausalLM.from_pretrained(
self.model_id,
device_map="auto",
torch_dtype="auto",
trust_remote_code=True,
_attn_implementation='flash_attention_2'
).to(self.device)
def load_processor(self):
"""
加载与模型关联的处理器,用于处理输入和输出。
Returns:
processor (AutoProcessor): 用于处理文本和图像的加载处理器。
"""
print("加载处理器...")
return AutoProcessor.from_pretrained(self.model_id, trust_remote_code=True)
def predict(self, image_url, prompt):
"""
使用给定的图像和提示执行模型预测。
Args:
image_url (str): 要处理的图像的 URL。
prompt (str): 引导模型生成的文本提示。
Returns:
response (str): 模型生成的响应。
"""
image = Image.open(requests.get(image_url, stream=True).raw)
prompt_template = f"<|user|>\n<|image_1|>\n{prompt}<|end|>\n<|assistant|>\n"
inputs = self.processor(prompt_template, [image], return_tensors="pt").to(self.device)
generation_args = {
"max_new_tokens": 500,
"temperature": 0.7,
"do_sample": False
}
print("生成响应...")
output_ids = self.model.generate(**inputs, **generation_args)
output_ids = output_ids[:, inputs['input_ids'].shape[1]:]
response = self.processor.batch_decode(output_ids, skip_special_tokens=True)[0]
return response
# 初始化模型
phi_model = Phi3VisionModel()
# 示例预测
image_url = "https://example.com/sample_image.png"
prompt = "以 JSON 格式提取数据。"
response = phi_model.predict(image_url, prompt)
print("响应:", response)
上述代码定义了一个 Phi3VisionModel 类,封装了模型的加载与使用,使其更易于集成到您的应用中。predict() 方法演示了如何使用自定义提示进行基于图像的推理。
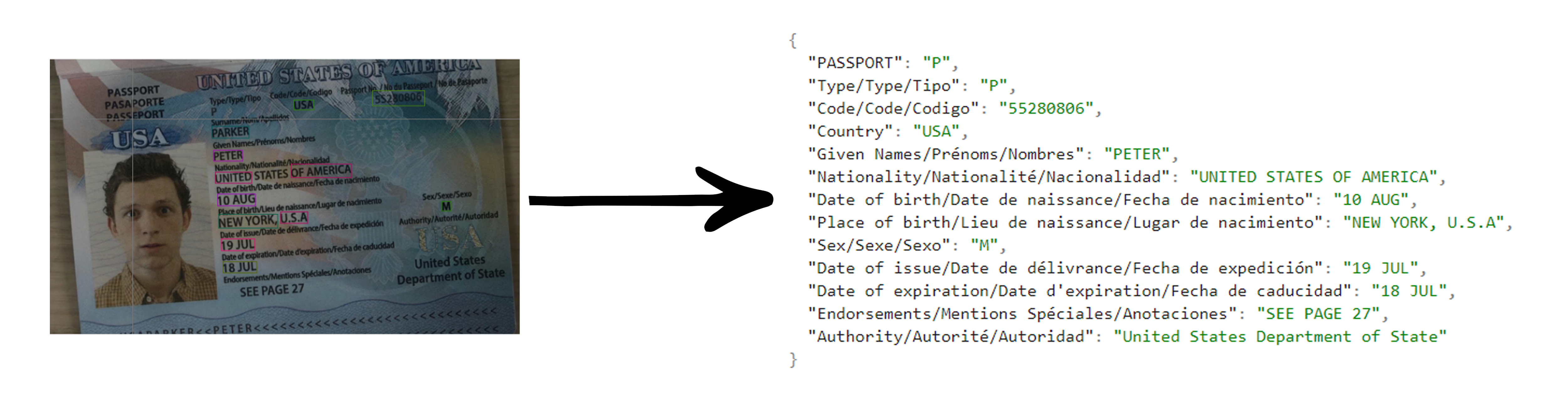
为了评估 Phi-3-Vision-128K-Instruct 模型的 OCR 能力,我们将其应用于真实扫描的身份证图像示例中,取得了优异的表现。
使用扫描的身份证测试 OCR 能力
为了评估 Phi-3-Vision-128K-Instruct 的 OCR 性能,我们测试了几张真实扫描的身份证图像。这些图像质量和清晰度各不相同,考验了模型从不同特征文档中提取文本的能力。
图像 1: 一本虚构的乌托邦护照,包含姓名、国籍、出生地、签发日期等个人信息。文本略带风格化,整体质量较高,背景干净。

输出:
{
"Type/Type": "P",
"Country code/Code du pays": "UTO",
"Passport Number/N° de passeport": "L898902C3",
"Surname/Nom": "ERIKSSON",
"Given names/Prénoms": "ANNA MARIA",
"Nationality/Nationalité": "UTOPIAN",
"Date of Birth/Date de naissance": "12 AUGUST/AOUT 74",
"Sex/Sexe": "F",
"Place of birth/Lieu de naissance": "ZENITH",
"Date of issue/Date de délivrance": "16 APR/AVR 07",
"Authority/Autorité": "PASSPORT OFFICE",
"Date of expiry/Date d'expiration": "15 APR/AVR 12",
"Holder's signature/Signature du titulaire": "anna maria eriksson",
"Passport/Passeport": "P<UTOERIKSSON<<ANNA<MARIA<<<<<<<<<<<<<<<<<<<<<<<L898902C36UT07408122F1204159ZE184226B<<<<10"
}
使用 Phi-3-Vision-128K-Instruct 进行尝试
如果您想亲自尝试 Phi-3-Vision-128K-Instruct 模型,可以通过以下链接进行探索:在 Azure AI 上尝试 Phi-3-Vision-128K-Instruct。该链接可以帮助您体验其强大的 OCR 功能。
模型架构与训练
Phi-3-Vision-128K-Instruct 是一个多模态 AI 模型,经过了全面的训练,处理文本和图像数据的能力极为出色。其架构将语言模型与图像处理模块结合,能够理解超过 128K 个 Token 的上下文,适用于需要大量内容理解的场景。
模型在强大硬件(如 512 个 H100 GPU)上进行训练,并采用 flash attention 技术提高内存效率。其训练数据集结合了合成数据和筛选后的真实世界数据,涵盖 数学、编码、常识推理 和 知识问答 等方面,使其足够灵活以应对各种应用。
OCR 和文档提取的重要性
文档提取和 OCR 对企业和研究机构来说至关重要,它能够将手写或印刷文本转换为机器可读格式。利用 Phi-3-Vision-128K-Instruct 这样的 AI 模型可以大幅简化任务,如 PDF 解析、自动数据录入、发票处理 和 法律文档分析。
无论是处理扫描文档、截图,还是相机拍摄的页面,Phi-3-Vision-128K-Instruct 的多模态功能都能帮助自动化数据提取,成为提高生产效率的有力工具。
负责任的 AI 与安全考量
虽然 Phi-3-Vision-128K-Instruct 功能强大,但开发者需要意识到其潜在局限性,包括 语言偏见、刻板印象强化 以及 内容不准确 等问题。对于高风险应用,如 医疗或法律建议,需要额外的验证和内容过滤措施。
未来方向与微调
希望扩展 Phi-3-Vision-128K-Instruct 的功能?该模型支持微调,开发者可以利用 Phi-3 Cookbook 对其进行调整,使其适应特定任务,如 文档分类、OCR 精度提升 和 专业化图像理解。
结论
Phi-3-Vision-128K-Instruct 是多模态 AI 领域的一大突破,它让文档提取、OCR 以及 AI 驱动的内容生成变得更加高效和易于访问。通过广泛的训练、强大的架构以及精心设计,该模型赋予开发者在多个领域改变数据处理方式的能力。