是云还是非云?这是让硅谷最优秀的人们夜不能寐的问题。
一方面,有一些从业者在本地运行LLM进行实验和构建原型,还有一些公司由于隐私、安全和监管问题无法离开数字后院。
另一方面,还有一些人在云解决方案上押注,速度和规模是游戏的规则,竞争正在迅速增长。
如果您查看最新的第三季度收益,云群似乎得分了。一些公司的投资回报率估计已经开始显现。例如,自2023年7月以来,微软对OpenAI的投资开始见效,Azure OpenAI服务的客户数量增长了64%,达到了18,000。这绝对不仅仅是增长;这是一次爆炸,是技术客户宇宙中的超新星。
那么,你的选择是什么?你准备加入云星座还是留在你的数字后院?
如果是后者,我有好消息告诉你。在本文中,我将为您介绍:
-
部署本地LLM的前3个原因
-
使用Ollama(Llama v2)、Supabase pgvector、Langchain.js和Nextjs部署本地LLM堆栈
-
对代码库的简要解释,以便您可以根据自己的需求自定义堆栈

让我们开始吧!
运行LLM本地的前3个原因
-
隐私:在本地运行LLM可以确保您的数据永远不会离开其他人的设施,并在数据隐私方面提供了非常重要的优势。由于数据泄露成为新的银行抢劫,每个在用户领域内本地处理的查询都是一个潜在的风险回避,对所有相关方来说都是一种信任的维护。特别是在医疗保健或金融等关键行业,隐私不仅仅是一个功能;它是信任和合规的基石。
-
成本效益:如果您不小心,云服务很容易成为一个完全的预算黑洞,但这不仅仅是成本问题,决策必须在更广泛的时间框架内进行。在构建与购买的决策中,公司通常更喜欢采购而不是开发,这是由市场参与速度的迫切性驱动的。这有助于快速运行原型并验证想法。但速度是以灵活性为代价的。当您“购买”时,您也会面临供应商锁定和一系列限制。您很快会发现自己试图适应您所锁定的某种技术,而不是根据用例或业务需求驱动技术选择。在这种意义上,选择“构建”可能具有更好的长期影响,确保同时考虑两者,并将两者的优点融入到同一混合中。
-
定制:个性化的人工智能助手作为生活和工作伴侣,这已经不仅仅是一个奇思妙想。在不久的将来,LLM的本地部署将非常普遍。个人AI助手将随着时间的推移不断改进,并在组织您的生活和提高您的工作效率方面提供前所未有的支持。在这方面,定制将至关重要。想象一下一个AI助手,它不仅可以安排会议,而且可以根据您的个人偏好进行安排,比如避免早上的时间段或将相似的任务聚集在一起。在工作中,它可以与您的工作流程无缝集成,管理项目时间表,并以反映您的专业风度的细微差别促进沟通。助手还可以变成工作与生活平衡的个人策展人,了解何时在专业承诺和个人时间之间划定界限。现实世界的场景是多种多样的,每一次定制的进展都使我们更接近将它们变为现实。你明白我的意思吧!
希望到这一点,您应该有足够的动力和决心在本地环境中部署一个。
终极本地LLM堆栈:Ollama、Supabase、Langchain和Nextjs
设置环境
→ 首先克隆以下存储库:
git clone https://github.com/ykhli/local-ai-stack.git
→ 更改目录并安装依赖项:
cd local-ai-stack/
npm install
不要使用pnpm,因为它会导致安装问题。
→ 按照这些说明安装Ollama,因为我使用的是WSL 2,所以我将运行:
curl https://ollama.ai/install.sh | sh
当安装完成后,您将看到以下内容
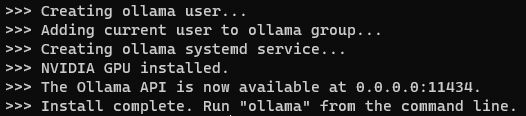
您可以看到Ollama API可在localhost:11434上使用。
运行以下命令启动Ollama:
ollama serve

然后在另一个终端中运行:
ollama run llama2

第一次运行时,它将拉取模型,对于所有后续运行,您将看到服务器将启动llama runner

有了这个,我们就可以在本地运行LLM了!
→ 接下来,根据您的操作系统安装Docker Desktop。如果您使用的是WSL 2,请转到Docker Desktop设置并启用WSL集成
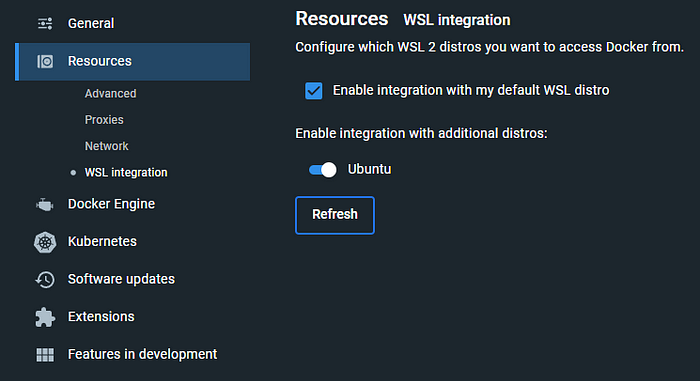
确保在继续之前Docker Desktop正在运行。
→ 在本地安装Supabase:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
echo 'eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"') >> /home/c0hnth3s4vi0r/.bashrc
eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"
sudo apt-get install build-essential
brew install supabase/tap/supabase
→ 启动Supabase:
supabase start
它将开始从supabase拉取一堆镜像,例如postgres、storage-api、imgproxy、edge-runtime,这些都是运行supabase所需的。完成后,您将看到以下内容
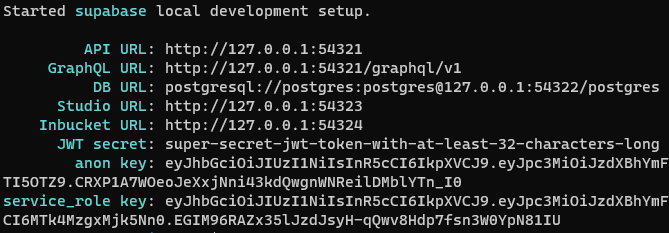
Supabase提供了pgvector,这是用于存储嵌入和基于嵌入(向量)相似性进行搜索的PostgreSQL扩展。
→ 复制示例env文件:
cp .env.local.example .env.local
→ 在.env.local文件中使用从以下命令获取的“anon key”值定义SUPABASE_PRIVATE_KEY:
supabase status
生成嵌入并将其存储在Supabase pgvector中
在您的项目文件夹中,您将使用src/scripts/indexBlogLocal.mjs根据/blogs文件夹中的文件生成嵌入
/blogs文件夹中存放着markdown文件,其中有两个文件,马克·安德森解释了为什么人工智能不会摧毁世界,实际上可能拯救世界。
您可以运行以下命令基于这些markdown文件生成和存储嵌入:
node src/scripts/indexBlogLocal.mjs
如果您打开脚本,您将看到它使用了
-
"Xenova/all-MiniLM-L6-v2"作为嵌入模型
-
使用LangChain的RecursiveCharacterTextSplitter进行分块,chunkSize为1000,chunkOverlap为50。
当您运行该命令时,您可以在终端中看到插入到Supabase中的块和相应的嵌入
向马克·安德森询问人工智能的风险
现在,您可以在本地运行应用程序
npm run dev
导航到http://localhost:3000并开始向马克·安德森提问!
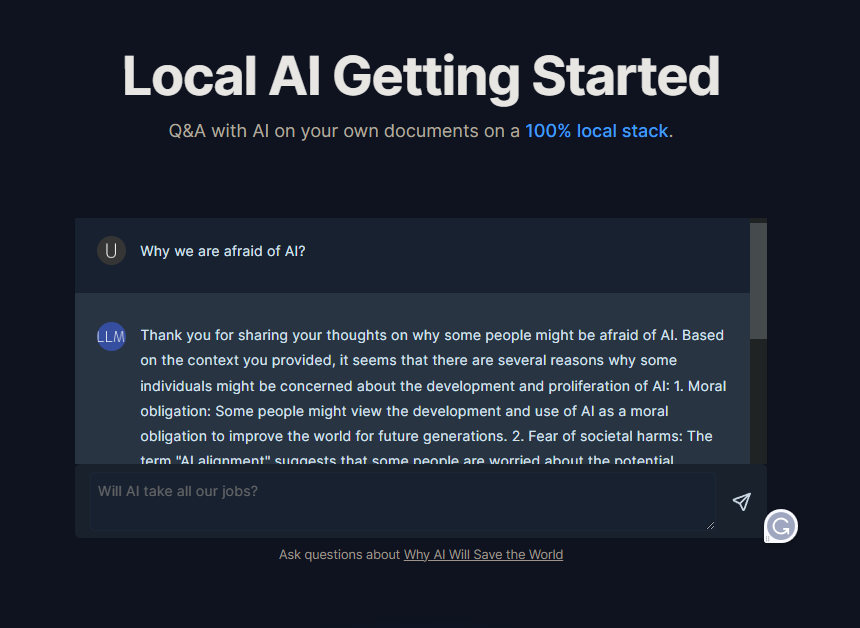
这已经非常强大,并且可以进行无数的定制!
现在,您可以创建自己的markdown文件,生成和存储这些嵌入,并通过调整提示来将您的答案调整到可接受的水平,如果不是完美的话。
清理
完成实验后,您可以停止ollama服务器(Ctrl + C)和supabase容器(supabase stop)。
理解代码库
显然,这里有很多内容,但我想带您了解聊天组件,并解释功能是如何工作的。
对我们尊敬的读者的个人请求:
我们设想一个未来,每个人都具备了解和利用人工智能的知识和工具,推动世界上的积极变革和创新。
我们发布的每篇文章,我们分享的每个笔记本,以及我们提供的所有资源都是对我们对这一愿景的承诺的证明。我们将我们的激情、专业知识和无数小时投入到创造我们相信可以在您的旅程中产生影响的内容中。
**但是,这里有一个令人惊讶的事实:**在从我们的内容中受益的成千上万人中,只有区区1%的人选择在Medium上关注我们。我们的梦想是看到这个数字增加到10%。为什么?因为每一个关注都是对我们的信心的投票,是我们走在正确道路上的标志,也是您希望看到更多的主题和资源的指示器。
如果您曾经从我们的工作中获得价值,如果您相信一个由人工智能赋能的世界,并且如果您愿意与我们一起参与这个激动人心的旅程,请花一点时间在Medium上关注我们。这只是一个小小的举动,但对我们来说意义重大,它帮助我们根据您的需求调整我们的内容。
感谢您成为我们社区的重要一员。让我们共同塑造人工智能的未来。
在page.tsx文件中,当您导航到localhost:3000时,您将看到呈现的内容
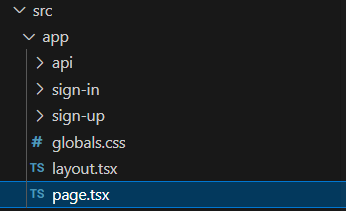
您可以看到有2个组件
-
第7行的
-
第24行的
如果您打开Examples组件
你会看到它在 src/components/ChatComponent.tsx 中使用了
让我们看看 ChatComponent 中发生了什么。
- ChatComponent 将聊天消息存储在 messages 变量中,它是一个 Message 类型的列表。
const [messages, setMessages] = useState<Message[]>([]);
useCompletion是来自 Vercel AI SDK 的自定义 React hook,用于处理将用户输入发送到 AI 后端并接收 AI 的文本补全响应。通过流式传输,UI 会自动从 API 端点更新,因为 Llama 2 生成新的令牌。
const {
completion,
input,
setInput,
isLoading,
handleInputChange,
handleSubmit,
} = useCompletion({
api: "/api/qa-pg-vector",
onFinish: (prompt: string, completion: string) => {
console.log(messages);
setMessages((previousMessage) => {
previousMessage[previousMessage.length - 1].content == "Thinking..."
? previousMessage.pop()
: null;
return [...previousMessage, { content: completion, user: "LLM" }];
});
},
});
handleFormSubmit是一个函数,用于将用户输入提交到 AI 后端,并使用用户输入和一个指示 AI 正在 "Thinking..." 的占位消息更新messages状态。
const handleFormSubmit = (e: React.FormEvent<HTMLFormElement>) => {
e.preventDefault();
handleSubmit(e);
setMessages((previousMessage) => [
...previousMessage,
{ content: input, user: "User" },
{ content: "Thinking...", user: "LLM" },
]);
};
UserMessage和LLMMessage是 React 函数组件,它们接受content作为 prop,并返回一个带有内容的样式化消息气泡。它们通过不同的样式和可能不同的头像图像进行区分。
此外,作者还实现了从 Pinecone 向量数据库检索向量,如果你查看 src/app/api/qa-pinecone/route.ts。
结论
希望这能帮助你了解堆栈的主要组件,并作为本地部署 LLM 的实用指南,为隐私、成本效益和定制化的好处提供有力支持。
现在,你可以继续使用 Ollama、Supabase、Langchain 和 Next.js 开发自己的本地 LLM 堆栈,并为各种用例扩展此基础架构。