现在有很多人工智能产品可以让你与自己的私人 PDF 和文档进行交互。但是它们是如何工作的?你如何构建一个?实际上,在幕后,这其实非常简单。
让我们深入了解一下!
我们将从一个简单的聊天机器人开始,它可以与一个文档进行交互,然后逐步发展成一个更高级的聊天机器人,可以与多个不同的文档和文档类型进行交互,并且可以记录聊天历史,这样你就可以根据最近的对话来提问。
目录
- 它是如何工作的?
- 与单个 PDF 进行交互
- 使用嵌入和向量存储与单个 PDF 进行交互
- 添加聊天历史
- 与多个文档进行交互
- 改进
- 总结
它是如何工作的?
从基本层面上讲,文档聊天机器人是如何工作的?在其核心,它与 ChatGPT 是一样的。在 ChatGPT 上,你可以将一大段文本复制到提示中,然后要求 ChatGPT 为你总结文本或根据文本生成一些答案。
与单个文档进行交互,比如 PDF、Microsoft Word 或文本文件,工作方式类似。我们从文档中提取所有文本,将其传递给一个 LLM 提示,比如 ChatGPT,然后根据文本提问。这与上面的 ChatGPT 示例是一样的。
与多个文档进行交互
当文档非常大或者我们想要与多个文档进行交互时,情况就变得更有趣了。将所有这些文档的信息都传递给 LLM(大型语言模型)的请求是不可能的,因为这些请求通常有大小(令牌)限制,所以只有在尝试传递过多信息时才会成功。
我们只能将相关信息发送给 LLM 提示,以克服这个问题。但是,我们如何从文档中获取只有相关信息呢?这就是嵌入和向量存储的作用。
嵌入和向量存储
我们希望能够只发送与 LLM 提示相关的信息。嵌入和向量存储可以帮助我们实现这一点。
如果你以前没有听说过嵌入,可能会对它们感到有些困惑,所以如果一开始它们似乎有些陌生,不要担心。稍微解释一下,并在我们的设置中使用它们,应该能更清楚地理解它们的用途。
嵌入允许我们根据语义含义对文本进行组织和分类。因此,我们将文档分成许多小的文本块,并使用嵌入来描述每个文本块的语义含义。嵌入转换器用于将文本块转换为嵌入。
嵌入通过给文本块赋予一个向量(坐标)表示来对文本进行分类。这意味着彼此接近的向量(坐标)表示具有相似含义的信息。嵌入向量与每个嵌入对应的文本块一起存储在向量存储中。
一旦我们有了提示,我们就可以使用嵌入转换器将其与最相关的文本块进行匹配,这样我们就知道如何将我们的提示与向量存储中的其他相关文本块匹配起来。在我们的案例中,我们使用 OpenAI 的嵌入转换器,它使用余弦相似度方法来计算文档和问题之间的相似度。
现在,我们有了与提示相关的较小信息子集,我们可以使用我们的初始提示查询 LLM,同时将只有相关信息作为上下文传递给我们的提示。
这就是我们如何克服 LLM 提示的大小限制的方法。我们使用嵌入和向量存储来传递与查询相关的信息,并根据此信息让 LLM 回答我们。
那么,在 LangChain 中我们如何做到这一点呢?幸运的是,LangChain 提供了这个功能,只需几个简短的方法调用,我们就可以开始了。让我们开始吧!
编码时间!
与单个 PDF 进行交互
让我们从处理单个 PDF 开始,然后再处理多个文档。
第一步是从 PDF 创建一个 Document。Document 是 LangChain 中用于与信息进行交互的基类。如果我们查看 Document 的类定义,它是一个非常简单的类,只有一个 page_content 方法,允许我们访问 Document 的文本内容。
class Document(BaseModel):
"""与文档进行交互的接口。"""
page_content: str
metadata: dict = Field(default_factory=dict)
我们使用 LangChain 提供的 DocumentLoaders 将内容源转换为 Documents 的列表,每个页面一个 Document。
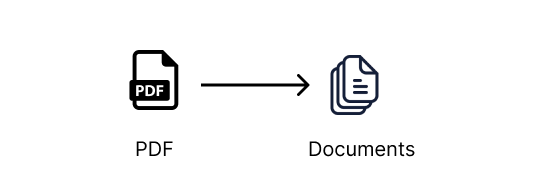
例如,有一些 DocumentLoaders 可以将 PDF、Word 文档、文本文件、CSV、Reddit、Twitter、Discord 等来源转换为 Document 的列表,然后 LangChain 链就可以使用这些 Document 进行工作。一旦你掌握了这些基础知识,就可以玩弄这些很酷的来源了。
首先,让我们创建一个项目目录。你可以按照我们的步骤一步一步地创建,或者使用以下命令克隆带有所有示例和示例文档的 GitHub 存储库。如果你克隆了存储库,请确保按照 README.md 文件中的说明正确设置你的 OpenAI API 密钥。
git clone [email protected]:smaameri/multi-doc-chatbot.git
否则,如果你想一步一步地跟着做:
mkdir multi-doc-chatbot
cd multi-doc-chatbot
touch single-doc.py
mkdir docs
# 还可以创建一个虚拟环境,以便只在本地安装所有软件包
python3 -m venv .venv
. .venv/bin/activate
然后从这里下载示例简历 CV [RachelGreenCV.pdf],并将其存储在 docs 文件夹中。
让我们安装我们设置所需的所有软件包:
pip install langchain pypdf openai chromadb tiktoken docx2txt
现在我们的项目文件夹已经设置好了,让我们将我们的 PDF 转换为一个文档。我们将使用 PyPDFLoader 类。同时,让我们现在设置我们的 OpenAI API 密钥。我们稍后会用到它。
import os
from langchain.document_loaders import PyPDFLoader
os.environ["OPENAI_API_KEY"] = "sk-"
pdf_loader = PyPDFLoader('./docs/RachelGreenCV.pdf')
documents = pdf_loader.load()
这将返回一个 Document 的列表,每个页面一个 Document。在 Python 类型方面,它将返回一个 List[Document]。因此,列表的索引将对应于文档的页面,例如第一页的 documents[0],第二页的 documents[1],依此类推。
我们可以使用最简单的 Q&A 链实现 load_qa_chain。它加载一个链,允许你传入你想要查询的所有文档。
from langchain.llms import OpenAI
from langchain.chains.question_answering import load_qa_chain
# 我们指定 OpenAI 是我们想要在链中使用的 LLM
chain = load_qa_chain(llm=OpenAI())
query = '这份简历是关于谁的?'
response = chain.run(input_documents=documents, question=query)
print(response)
现在,运行这个脚本以获取响应:
➜ multi-doc-chatbot: python3 single-doc.py
这份简历是关于 Rachel Green 的。
实际上,在后台发生的是,文档的文本(即 PDF 文本)与查询一起发送到 OpenAPI Chat API,全部包含在一个请求中。
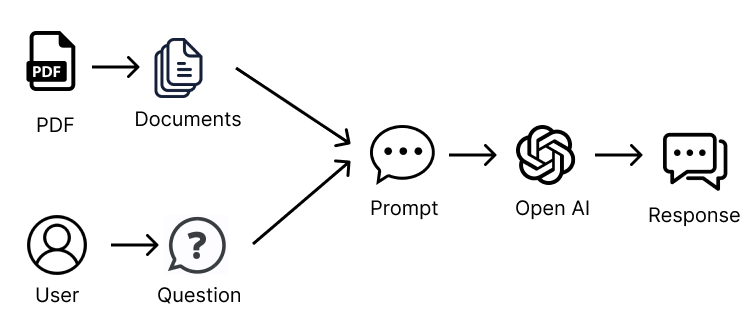
此外,load_qa_chain 实际上将整个提示包装在一些文本中,指示 LLM 仅使用提供的上下文信息。因此,发送到 OpenAI 的提示看起来像下面这样:
使用以下上下文片段回答最后的问题。
如果你不知道答案,只需说你不知道,不要试图编造一个答案。
{context} // 即 PDF 文本内容
问题:{query} // 即我们实际的查询,'这份简历是关于谁的?'
有用的答案:
这就是为什么如果你尝试问一些随机的问题,比如“巴黎在哪里?”,聊天机器人会回答说它不知道。
要显示发送到 LLM 的完整提示,可以在 load_qa_chain() 方法上设置 verbose=True 标志,这将在控制台打印实际发送到 API 的所有信息。这有助于理解它在后台是如何工作的,以及实际发送到 OpenAI API 的提示是什么样的。
chain = load_qa_chain(llm=OpenAI(), verbose=True)
```正如我们在开始时提到的,当我们只有少量信息需要在上下文中发送时,这种方法是很好的。大多数LLM都会对单个请求中可以发送的信息量有限制。因此,我们将无法在单个请求中发送我们文档中的所有信息。
为了克服这个问题,我们需要一种聪明的方法,只发送我们认为与我们的问题/提示相关的信息。
## 使用嵌入与单个PDF交互
### 嵌入来拯救!
如前所述,我们可以使用嵌入和向量存储来仅发送与我们的提示相关的信息。我们需要遵循的步骤如下:
- 将所有文档拆分为小的文本块
- 将每个文本块传递给嵌入转换器,将其转换为嵌入
- 将嵌入和相关的文本片段存储在向量存储中

让我们开始吧!
首先,创建一个名为`single-long-doc.py`的新文件,以表示此脚本可用于处理太长而无法作为上下文传递给提示的PDF
```bash
touch single-long-doc.py
现在,将以下代码添加到文件中。代码中的注释解释了步骤。记得添加你的API密钥。
import os
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
os.environ["OPENAI_API_KEY"] = "sk-"
# 如前所述加载文档
loader = PyPDFLoader('./docs/RachelGreenCV.pdf')
documents = loader.load()
# 我们将数据拆分为1,000个字符的块,块之间有200个字符的重叠,这有助于提供更好的结果并包含块之间的信息上下文
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
documents = text_splitter.split_documents(documents)
# 我们创建一个向量数据库,使用OpenAIEmbeddings转换器从我们的文本块创建嵌入。我们将所有的数据库信息都设置为存储在./data目录中,这样就不会使我们的源文件混乱
vectordb = Chroma.from_documents(
documents,
embedding=OpenAIEmbeddings(),
persist_directory='./data'
)
vectordb.persist()
一旦我们将内容加载为嵌入到向量存储中,我们就回到了最初只有一个PDF与之交互的情况。也就是说,我们现在准备将信息传递给LLM提示。然而,与最初一样,我们不会将所有的documents作为上下文的源传递给链,而是将我们的向量存储作为源传递给链,链将使用它来根据我们的问题检索只有相关文本,并仅将该信息发送到LLM提示中。
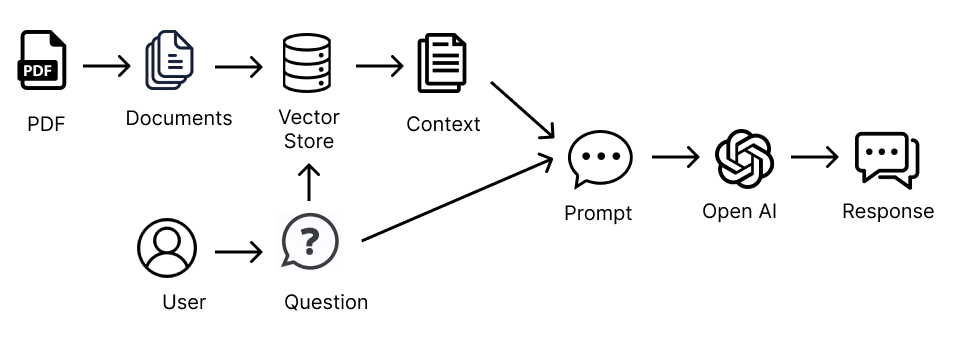
这次,我们将使用RetrievalQA链,它可以使用我们的向量存储作为上下文信息的源。
同样,链将在我们的提示周围包装一些文本,指示它仅使用提供的信息来回答问题。因此,我们最终发送给LLM的提示如下所示:
使用以下上下文片段回答最后的问题。
如果你不知道答案,只需说你不知道,不要试图编造一个答案。
{context} // 即我们检索到的被认为与我们的问题最相关的文本块
问题:{query} // 即我们的实际查询
有用的答案:
因此,让我们创建RetrievalQA链,并向LLM提出一些查询。我们创建RetrievalQA链,将向量存储作为我们的信息来源传入。在幕后,这将根据提示和存储之间的语义相似性仅检索向量存储中的相关数据。
请注意,我们在检索器上设置了search_kwargs={‘k': 7},这意味着我们希望从向量存储中发送七个文本块到我们的提示中。如果超过这个数量,我们将超过OpenAI提示令牌的限制。但是我们拥有的信息越多,我们的答案就越准确,所以我们确实希望尽可能多地发送信息。这篇文章提供了一些关于调整文档聊天机器人LLM参数的有用信息。
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(),
retriever=vectordb.as_retriever(search_kwargs={'k': 7}),
return_source_documents=True
)
# 现在,我们可以对我们的Q&A链执行查询
result = qa_chain({'query': '这份简历是关于谁的?'})
print(result['result'])
现在,运行脚本,你应该会看到结果。
➜ multi-doc-chatbot python3 single-long-doc.py
Rachel Green.
太棒了!我们现在已经使用嵌入和向量存储构建了我们的文档阅读器和聊天机器人!
请注意,我们将向量存储的persist_directory设置为./data。因此,这是向量数据库存储所有信息的位置,包括它生成的嵌入向量和与每个嵌入相关的文本块。
如果你打开项目根文件夹中的data目录,你将看到其中的所有数据库文件。很酷,对吧!就像MySQL或Mongo数据库一样,它有自己的目录来存储所有信息。
如果你更改了代码或存储的文档,并且聊天机器人的响应开始变得奇怪,请尝试删除此目录,它将在下一次脚本运行时重新创建。这有时可以帮助解决奇怪的响应问题。
添加聊天历史记录
现在,如果我们想进一步,我们还可以使我们的聊天机器人记住以前的问题。
在实现上,所有发生的事情就是在与聊天机器人的每次交互中,我们必须将我们以前的对话历史,包括问题和答案,传递给提示。这是因为LLM没有一种存储有关我们以前请求的信息的方法,所以我们必须在每次调用LLM时传递所有信息。
幸运的是,LangChain还提供了一组类,可以让我们直接做到这一点。这称为ConversationalRetrievalChain,它允许我们传入一个名为chat_history的额外参数,其中包含我们与LLM的以前对话的列表。
让我们为此创建一个新的脚本,称为multi-doc-chatbot.py(稍后我们将添加多文档支持😉)。
touch multi-doc-chatbot.py
像之前一样设置PDF加载器、文本拆分器、嵌入和向量存储。现在,让我们初始化Q&A链。
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI
qa_chain = ConversationalRetrievalChain.from_llm(
ChatOpenAI(),
vectordb.as_retriever(search_kwargs={'k': 6}),
return_source_documents=True
)
链运行命令接受chat_history作为参数。因此,首先,让我们通过将stdin和stout命令嵌套在While循环中来启用终端上的连续对话。接下来,我们必须根据与LLM的对话来手动构建这个列表。链不会自动完成这个操作。因此,对于每个问题和答案,我们将构建一个名为chat_history的列表,每次将其传递回链运行命令。
import sys
chat_history = []
while True:
# 这将打印到终端,并等待从用户接收输入
query = input('Prompt: ')
# 提供一种退出脚本的方法
if query == "exit" or query == "quit" or query == "q":
print('Exiting')
sys.exit()
# 我们将查询传递给LLM,并打印出响应。除了我们的查询,还将传递来自我们的向量存储的语义相关信息的上下文,以及我们的聊天历史记录列表
result = qa_chain({'question': query, 'chat_history': chat_history})
print('Answer: ' + result['answer'])
# 我们根据我们的问题和LLM的响应构建chat_history列表,然后脚本返回到循环的开始处,并再次准备接受用户输入。
chat_history.append((query, result['answer']))
删除data目录,以便在下一次运行时重新创建。当你在不删除先前设置创建的数据的情况下更改链和代码设置时,响应有时可能会出现奇怪的情况。
运行脚本,
python3 multi-doc-chatbot.py
并开始与文档进行交互。请注意,它可以识别以前问题和答案的上下文。你可以提交exit或q来离开脚本。
multi-doc-chatbot python3 multi-doc-chatbot.py
Prompt: 这份简历是关于谁的?
Answer: 这份简历是关于Rachel Green。
Prompt: 他们的姓氏呢?
Answer: Rachel Green的姓氏是Green。
Prompt: 那么名字呢?
Answer: Rachel。
这就是全部!我们现在已经构建了一个可以与多个文档进行交互的聊天机器人,并且可以保持聊天历史记录。但是等等,我们仍然只与单个PDF进行交互,对吧?
与多个文档交互
与多个文档进行交互很容易。如果你记得,从我们的PDF文档加载器创建的Documents只是一个Documents列表,即List[Document]。因此,要增加我们与之交互的文档基础,我们只需将更多的Documents添加到此列表中。让我们向我们的docs文件夹添加一些更多的文件。你可以从GitHub存储库docs文件夹中复制剩余的示例文档。现在我们的docs文件夹中应该有一个.pdf、一个.docx和一个.txt文件。
现在,我们可以简单地遍历该文件夹中的所有文件,并将它们中的信息转换为Documents。从那时起,流程与之前相同。我们只需将documents列表传递给文本分割器,文本分割器将将分块信息传递给嵌入转换器和向量存储器。
因此,在我们的情况下,我们希望能够处理pdf、Microsoft Word文档和文本文件。我们将遍历docs文件夹,根据文件扩展名处理文件,使用适当的加载器处理文件,并将它们添加到documents列表中,然后将其传递给文本分割器。
from langchain.document_loaders import Docx2txtLoader
from langchain.document_loaders import TextLoader
documents = []
for file in os.listdir('docs'):
if file.endswith('.pdf'):
pdf_path = './docs/' + file
loader = PyPDFLoader(pdf_path)
documents.extend(loader.load())
elif file.endswith('.docx') or file.endswith('.doc'):
doc_path = './docs/' + file
loader = Docx2txtLoader(doc_path)
documents.extend(loader.load())
elif file.endswith('.txt'):
text_path = './docs/' + file
loader = TextLoader(text_path)
documents.extend(loader.load())
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=10)
chunked_documents = text_splitter.split_documents(documents)
# 现在我们继续之前的步骤,将chunked_documents传递给向量存储器
# ...
现在,您可以再次运行脚本,并询问有关所有候选人的问题。如果您在docs文件夹中添加新文件后删除/data文件夹,似乎会有所帮助。否则,聊天机器人似乎无法获取新信息。
python3 multi-doc-chatbot.py
所以,我们有了一个能够与多个文档中的信息进行交互并保持聊天历史记录的聊天机器人。我们可以通过为终端输出添加一些颜色并处理空字符串输入来提升用户体验。以下是完整的脚本副本:
import sys
import os
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import Docx2txtLoader
from langchain.document_loaders import TextLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.text_splitter import CharacterTextSplitter
from langchain.prompts import PromptTemplate
os.environ["OPENAI_API_KEY"] = "sk-XXX"
documents = []
for file in os.listdir("docs"):
if file.endswith(".pdf"):
pdf_path = "./docs/" + file
loader = PyPDFLoader(pdf_path)
documents.extend(loader.load())
elif file.endswith('.docx') or file.endswith('.doc'):
doc_path = "./docs/" + file
loader = Docx2txtLoader(doc_path)
documents.extend(loader.load())
elif file.endswith('.txt'):
text_path = "./docs/" + file
loader = TextLoader(text_path)
documents.extend(loader.load())
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=10)
documents = text_splitter.split_documents(documents)
vectordb = Chroma.from_documents(documents, embedding=OpenAIEmbeddings(), persist_directory="./data")
vectordb.persist()
pdf_qa = ConversationalRetrievalChain.from_llm(
ChatOpenAI(temperature=0.9, model_name="gpt-3.5-turbo"),
vectordb.as_retriever(search_kwargs={'k': 6}),
return_source_documents=True,
verbose=False
)
yellow = "\033[0;33m"
green = "\033[0;32m"
white = "\033[0;39m"
chat_history = []
print(f"{yellow}---------------------------------------------------------------------------------")
print('Welcome to the DocBot. You are now ready to start interacting with your documents')
print('---------------------------------------------------------------------------------')
while True:
query = input(f"{green}Prompt: ")
if query == "exit" or query == "quit" or query == "q" or query == "f":
print('Exiting')
sys.exit()
if query == '':
continue
result = pdf_qa(
{"question": query, "chat_history": chat_history})
print(f"{white}Answer: " + result["answer"])
chat_history.append((query, result["answer"]))
LangChain存储库
为了更好地了解背后发生的事情,我建议您下载LangChain源代码并浏览一下,看看它是如何工作的。
git clone https://github.com/hwchase17/langchain
如果您使用像PyCharm这样的IDE浏览源代码(我认为社区版是免费的),您可以热点击(CMD + 单击)每个方法和类调用,它会直接带您到它们编写的位置,这对于点击代码库浏览代码非常有用。
改进
当您开始尝试与聊天机器人交互并查看其对不同问题的回答时,您会注意到它只有在某些情况下才会给出正确答案。
我们当前的方法确实有一些限制。例如,OpenAI令牌限制为4,096个令牌,这意味着我们不能发送超过大约6-7个文档块的文本。这意味着我们可能甚至没有发送来自所有文档的信息,这对于我们想要知道例如CV文档中所有人的姓名是很重要的。例如,一个文档可能完全被忽略,因此我们会错过一个关键的信息。
而且我们只有三个文档。想象一下有100个。在某些时候,仅4096个令牌的令牌限制将不足以给出准确的答案。也许您需要使用不同的LLM,例如不同于OpenAI的LLM,其中您可以拥有更高的令牌限制,以便可以在其中发送更多上下文。您现在可能听说过的一些功能是具有更高和更高令牌限制的LLM。
如果文档源大小太大,也许训练LLM是正确的选择,而不是通过提示上下文发送信息。或者可能可以对链参数或向量存储器检索技术进行一些智能调整。也许是智能提示工程或递归查找的某种代理可能是正确的选择。这篇文章提供了一些关于如何调整提示以获得更好响应的想法。
可能这些都是结合使用的,答案可能也会因您想要解析的文档类型而有所不同。例如,如果您选择专注于特定的文档类型,例如CV、用户手册或网站抓取,可能会有某些更适合特定类型内容的优化。
总的来说,要获得一个良好运行的多文档阅读器,我认为您需要在只是让它工作的表面部分之外再进一步,开始找出一些这些增强功能,这些功能可以使其成为一个更强大和有用的聊天机器人。
总结
所以,就是这样。我们构建了一个单文档聊天机器人,并完成了一个记住我们聊天历史记录的多文档聊天机器人。希望本文有助于解开嵌入、向量存储器和链和向量存储器检索器的参数调整的一些神秘感。