发挥你的数字双胞胎的潜力

本文旨在说明如何在自定义数据集上高效且具有成本效益地对顶级性能的LLM进行微调。我们将探索使用Lit-GPT中的Falcon-7B模型和LoRA适配器的方法。
你是否曾想过拥有一个数字双胞胎?一个可以进行对话、学习甚至反映你思维的虚拟复制品?人工智能(AI)的最新进展使得这个曾经的未来想法成为可能。
AI社区的努力已经导致了许多高质量的开源LLM的开发,包括但不限于Open LLaMA、Falcon、StableLM和Pythia。你可以在自定义的指令数据集上对这些模型进行微调,以适应你特定的任务,比如训练一个能回答金融问题的聊天机器人。此外,当数据无法上传或与云API共享时,这种方法还可以提供数据隐私的优势。
在我的情况下,我希望模型通过模仿我来学会说话,使用我的笑话和填充词。
数据收集和准备
在我们深入细节之前,我想指出微调类似GPT的模型可能会非常棘手。尽管如此,我决定更进一步,用俄语训练模型:
-
这增加了额外的挑战,因为模型主要是在英文文本上训练的。
-
鉴于俄语是我的母语,我拥有大量包含个人通信的数据集。
数据收集
我选择了Telegram,因为它提供了方便的数据收集API。此外,它也是我与朋友之间大部分通信的主要平台。这个选择提供了一个宝贵的数据集,使模型能够更深入地理解我的独特沟通风格,并使其更有效地模仿我。
根据文档,我编写了一个小脚本,用于下载所有私聊的通信记录并将其保存到文件中:
- 初始化Telegram客户端:
from telethon.sync import TelegramClient
client = TelegramClient(PHONE_NUMBER, TELEGRAM_APP_ID, TELEGRAM_APP_HASH)
client.start()
- 通过筛选组和频道获取对话列表:
def get_dialogs(limit: int | None = 100) -> list[Dialog]:
"""从Telegram获取所有对话。"""
dialogs: list[Dialog] = client.get_dialogs(limit=limit)
dialogs = [dialog for dialog in dialogs if dialog.is_user] # 移除组或频道
logger.info(f"找到{len(dialogs)}个对话")
return dialogs
- 下载通信记录:
def parse_messages(dialog: Dialog, limit: int = 1000) -> list[dict]:
"""从对话中获取所有消息。"""
all_messages_list = []
offset_id = 0
while True:
messages: list[Message] = client(
GetHistoryRequest(
peer=dialog,
offset_id=offset_id,
offset_date=None,
add_offset=0,
limit=limit,
max_id=0,
min_id=0,
hash=0,
)
).messages
if not messages:
break
all_messages_list.extend(
{
"date": message.date.isoformat(),
"message": message.message,
"out": message.out,
}
for message in messages
# 过滤音频或视频内容
if message.message and not message.is_bot
)
offset_id = offset_id = messages[-1].id
return all_messages_list
你可以在这里找到完整的脚本。
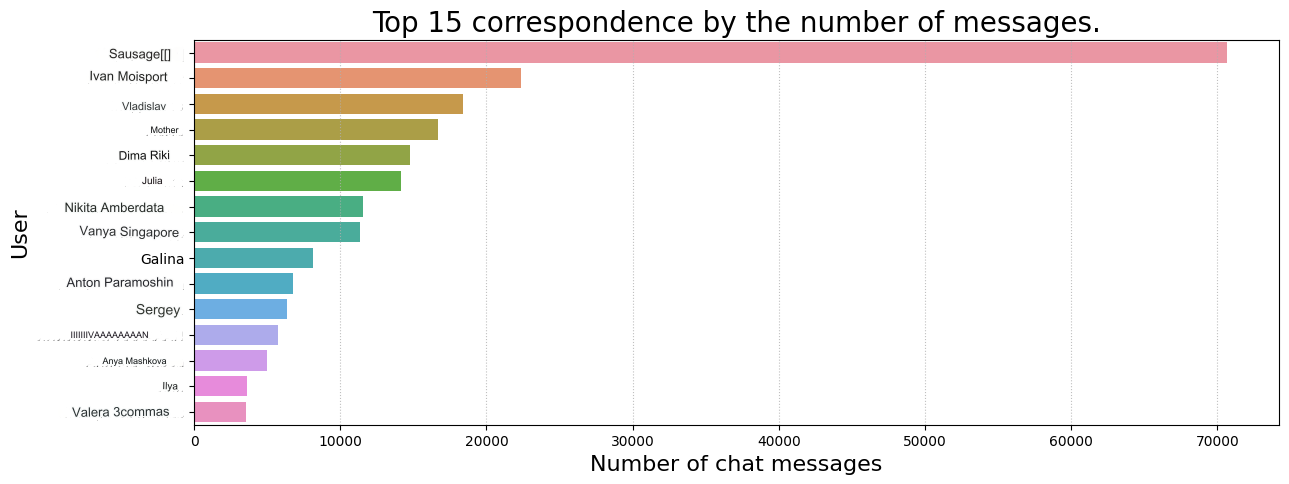
值得一提的是,我有意在数据集中排除了音频和视频消息,并且只关注基于文本的内容。因此,对话中的一些信息可能已经丢失。从这样的数据中提取文本是一个全面的话题,最好适合单独的文章来讨论。
数据准备
在这一点上,你必须仔细处理指令中的数据,以便对LLM进行微调。
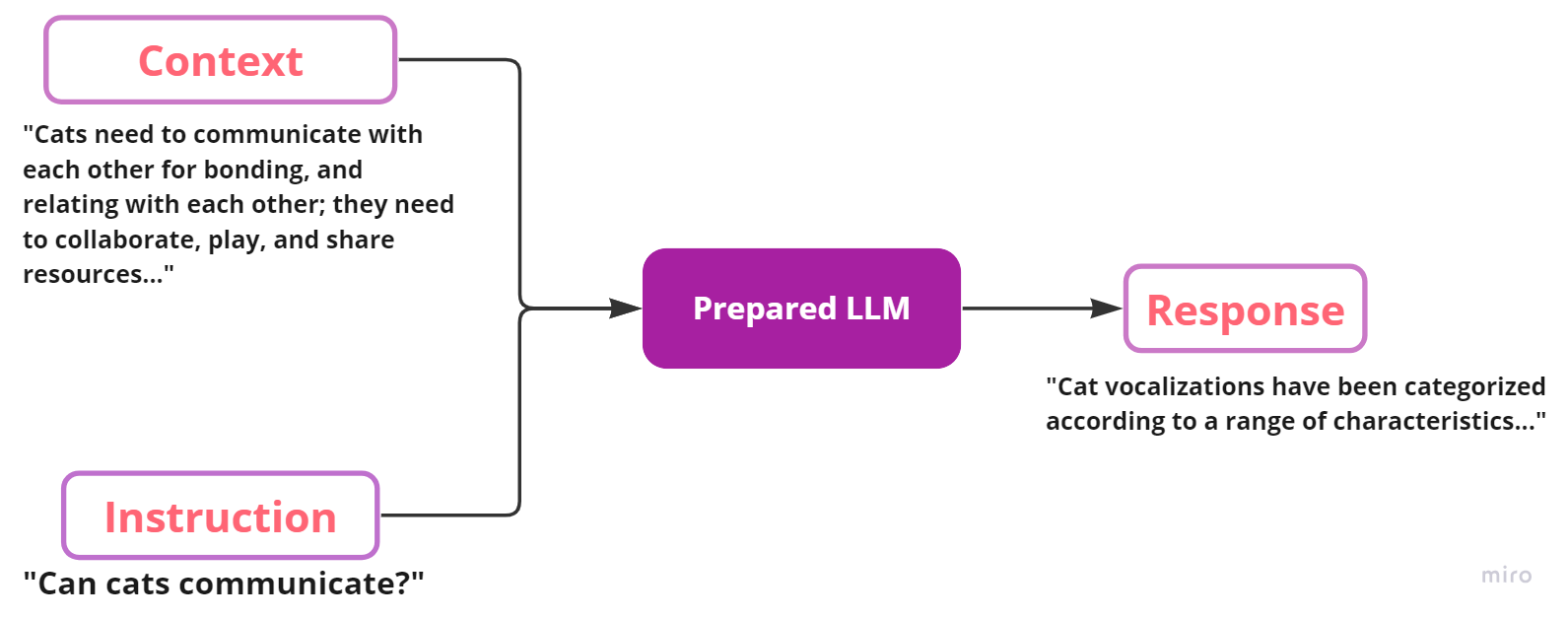
微调通常涉及训练预训练模型以遵循指令或执行其他特定的目标任务(例如情感分类)。ChatGPT(最初是GPT-3基础模型的微调版本)是一个典型的例子,它被微调以遵循指令。指令数据集通常有三个键:instruction(指令)、input(给定指令的可选上下文)和LLM的预期response(响应)。下面是一个示例指令数据的样本:
[
{
"instruction": "猫能够交流吗?",
"context": "猫需要相互交流以建立联系和相互关联;它们需要合作、玩耍和共享资源...",
"response": "猫的声音根据一系列特征进行了分类...",
}
]
在示例中,微调过程可以如下所示:
重要的是要记住,你可以根据自己的需求修改数据格式。例如,你可以输入一个函数,并要求模型生成文档作为响应。然而,根据我的经验,较小的模型(如7B)可能在处理复杂提示时遇到困难。
为了克服这个问题,尝试简化提示或将其分解为一系列连续的指令。这样,你可以获得更好的结果并提高模型的性能。
为了根据我的聊天构建指令,我采用了几种方法:
-
当两条消息之间的时间间隔超过一天时,将对话分成批次。这样,我们将其视为新的沟通主题的开始,因此不会有来自上一次对话的上下文。
-
将同一用户连续的消息连接成一条消息。我们知道,有些人倾向于连续写入多条短消息。
-
设置最大上下文长度以加快训练过程。
-
为我的回答和对话者的回答添加标签,以帮助模型更好地理解上下文。
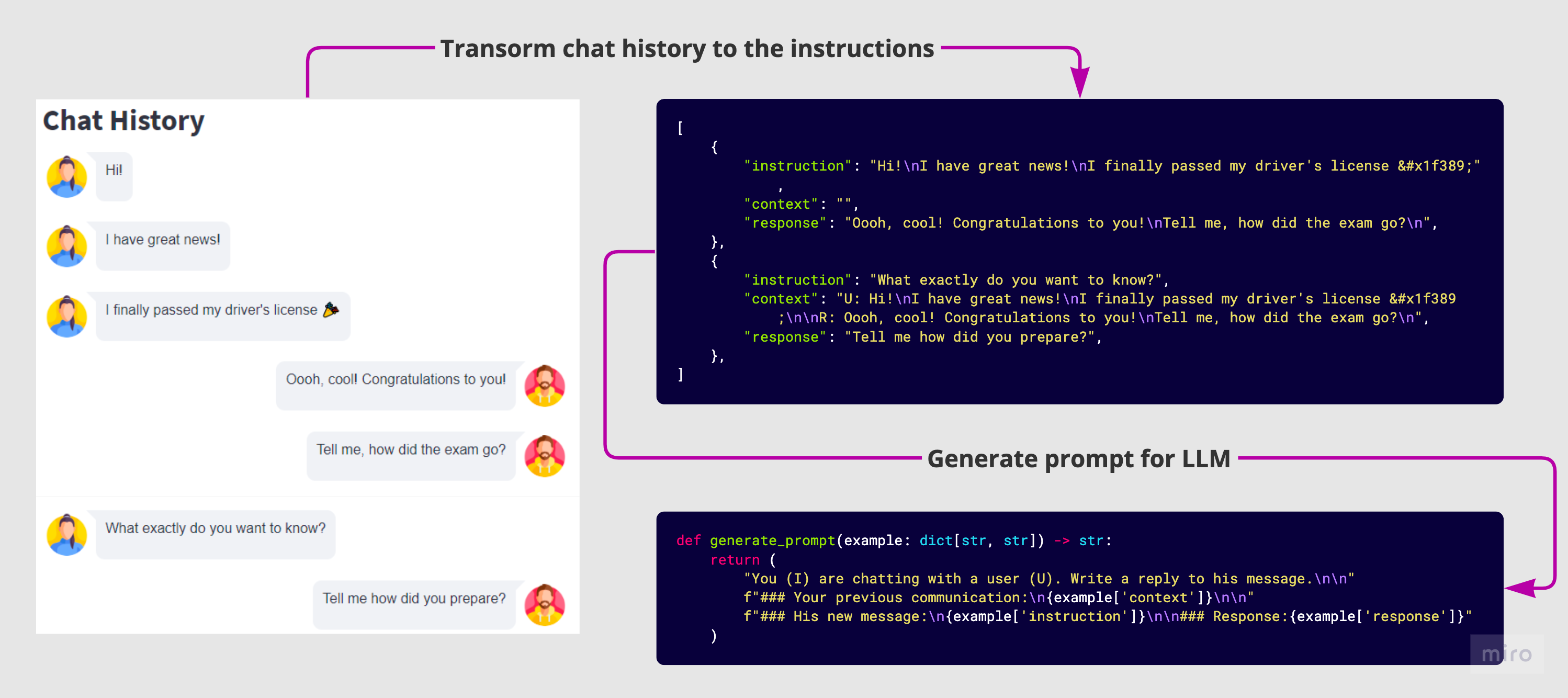
我还清除了聊天历史中的个人密码或电子邮件等敏感信息。
最终,我得到了51K条指令,与Databricks的Dolly 2.0指令数据集(约15k条指令)和Alpaca数据集(约52K条指令)相当。
模型
我决定选择猎鹰 - 由技术创新研究所发布的最新开源大型语言模型。它是一个仅有解码器的自回归模型,有两个变体:一个拥有70亿参数的模型和一个拥有400亿参数的模型。40B模型变体在AWS上使用384个GPU进行了2个月的训练。
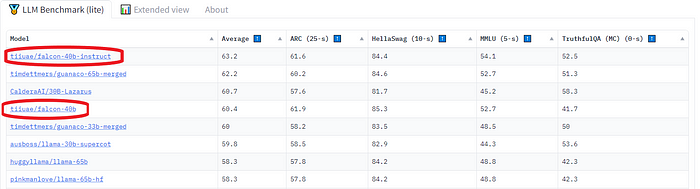
根据已知信息来看,猎鹰架构与GPT-3和LLaMA非常相似,只是使用了多查询注意力(Shazeer 2019)和RefinedWeb语料库作为训练数据集(这可能是成功的关键)。
使用LoRA进行参数高效的LLM微调
如果我们考虑增强LLM(大型语言模型)模型的方法,一个有价值的资源是OpenAI的文章PALMS: Pre-training an Autoencoder Latent Model for Sequence Generation。该文章讨论了使用微调的方法,即使用与原始训练相同的技术对模型进行重新训练,但学习率较低(约0.1)。这个过程允许我们在特定数据上训练模型,从而改善其在我们期望的领域中的响应能力。
除了微调,还有其他方法,比如使用适配器。适配器是在原始模型的现有层上添加额外的较小层,只训练这些新添加的层。这种方法可以加快学习过程,因为涉及的权重相对较小。
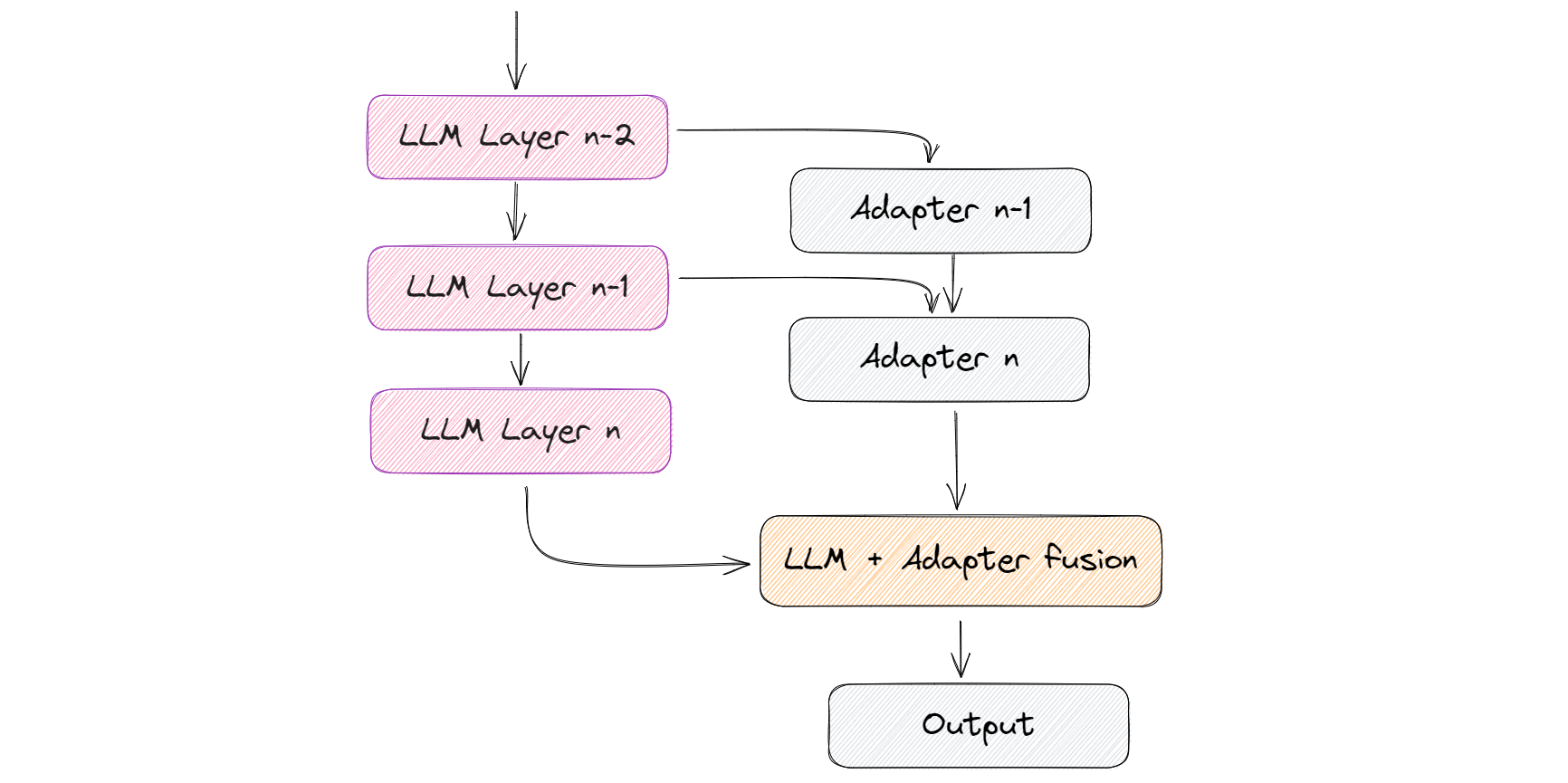
LoRA的概念受到了关于矩阵权重在训练过程中如何变化的观察的启发,这些观察在Aghajanyan等人的工作(2020)中得到了强调。这些观察表明,矩阵可以在保留大部分重要信息和结构的同时,通过较低维度的空间有效地近似表示。
每个矩阵_W在训练过程中表示为W + A * B的和。初始矩阵W被冻结,只有矩阵A和B被训练。因此,更新的权重可以表示为ΔW = W + A * B。通过确保矩阵A和B_保持较小,学习过程变得更快,需要更少的资源。简而言之,这就是LoRA方法,如下图所示。
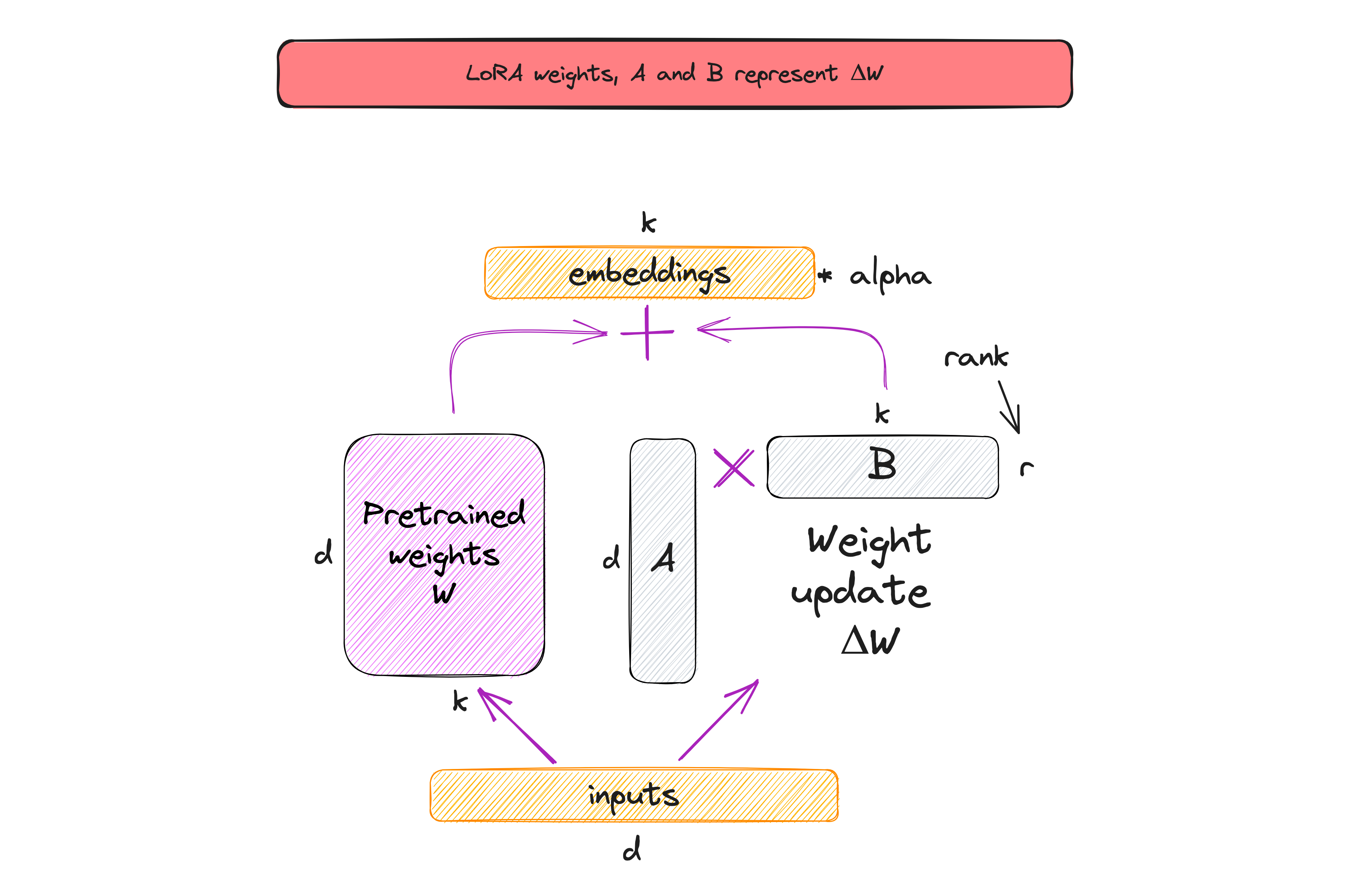 请注意,上图中的 r 是一个超参数,我们可以使用它来指定用于自适应的低秩矩阵的秩。较小的 r 导致较简单的低秩矩阵,从而在自适应过程中需要学习的参数较少。在 LoRA 中选择较小的 r 在模型复杂性、自适应能力和欠拟合或过拟合的风险之间存在权衡。
请注意,上图中的 r 是一个超参数,我们可以使用它来指定用于自适应的低秩矩阵的秩。较小的 r 导致较简单的低秩矩阵,从而在自适应过程中需要学习的参数较少。在 LoRA 中选择较小的 r 在模型复杂性、自适应能力和欠拟合或过拟合的风险之间存在权衡。
有关更多详细信息和深入了解,请参考以下资源:
-
Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
-
Parameter-Efficient LLM Finetuning With Low-Rank Adaptation (LoRA)
实验
为了进行实验,我使用了 Lit-GPT 库,其中包含了一个开源的 LLM 实现,并由 Lightning Fabric 提供支持。至于硬件设置,我使用了一块具有 40 GB 内存容量的单个 A100 GPU。
下载模型权重
开始实验的第一步是下载模型权重并将其转换为 lit-gpt 格式。这个过程非常简单:
# 下载模型权重:
python scripts/download.py --repo_id tiiuae/falcon-7b
# 将权重转换为标准化格式:
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/tiiuae/falcon-7b
你可以在这个 howto 部分 找到下载其他支持的权重(如 RedPajama)的说明。
准备数据集
微调包括两个主要步骤:首先,我们以 Lit-Parrot 格式处理数据集,然后在处理后的数据集上运行微调脚本。
我修改了现有的 Alpaca 脚本,它提供了一个准备函数,用于加载原始指令数据集、创建提示并对其进行标记化。在我的情况下,我需要将函数更改为生成提示:
def generate_prompt(example: dict[str, str]) -> str:
"""生成一个标准化的提示消息以提示模型"""
return (
"You (I) are chatting with a user R. Write a reply to his message.\n\n"
f"### Your previous communication:\n{example['context']}\n\n"
f"### His new message:\n{example['instruction']}\n\n"
f"### Your response:{example['response']}"
)
在进行了这些更改之后,你可以开始数据准备过程:
python scripts/prepare_dataset_my.py \
--checkpoint_dir checkpoints/tiiuae/falcon-7b/
准备提示的时间不长。在我的情况下,对于 51k 条指令,只需要 2 分钟:

对 Falcon 模型进行微调
一旦准备好数据集,微调模型就非常简单。
我在 fine-tuning 脚本 中更改了一些参数以获得更好的结果,以下是我使用的超参数设置概述:
bfloat16 精度(我在文章 7 ways to speed up inference of your hosted LLMs 中更详细地介绍了 bfloat16)。
-
此外,脚本被配置为使用有效批量大小为 128 进行 51k 次迭代的训练,使用了梯度累积(有关梯度累积的更多细节,请参见文章 Finetuning LLMs on a Single GPU Using Gradient Accumulation)。
-
对于 LoRA,我使用了秩为 16,以获得更高质量的训练适配器。并将 alpha 设置为 32(alpha 是一个缩放因子,用于调整组合结果的大小,平衡预训练模型的知识和新任务特定的自适应)。
然后,你需要运行 finetune/lora.py 脚本,并提供你的数据路径。
python finetune/lora_my.py \
--checkpoint_dir checkpoints/tiiuae/falcon-7b/ \
--data_dir data/falcon/ \
--out_dir out/falcon \
--precision bf16-true
监控微调过程
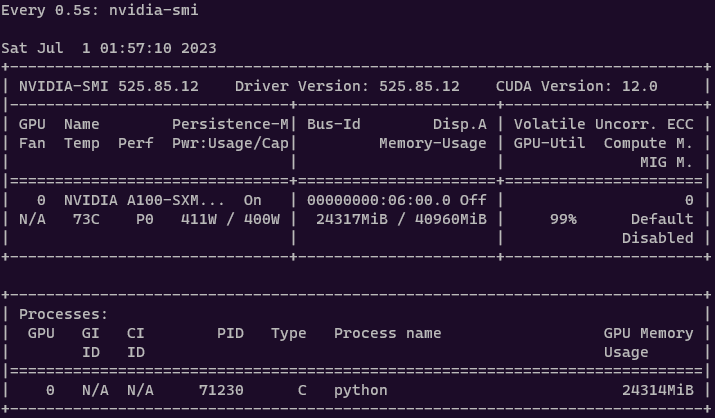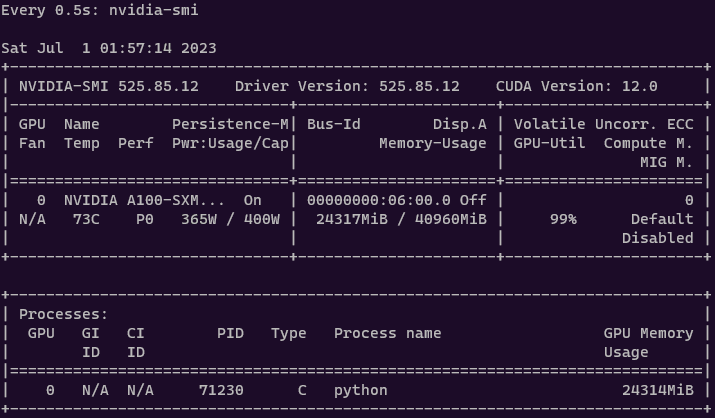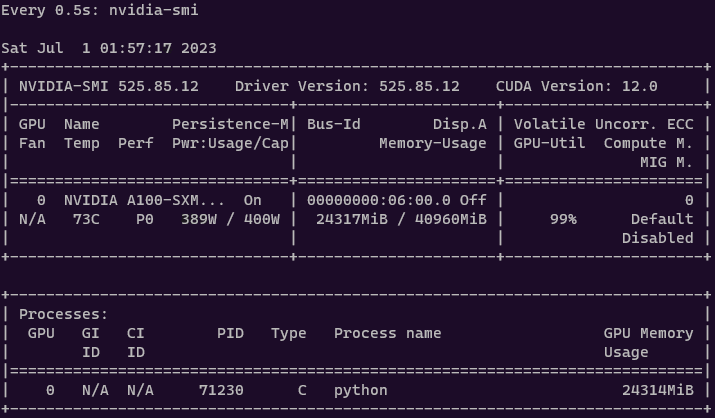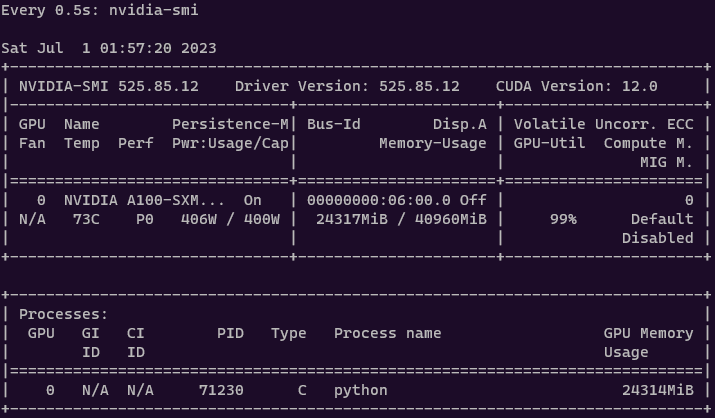
你可以使用 Linux 的 watch 命令每半秒运行一次 nvidia-smi:
watch -n 0.5 nvidia-smi
你可以在 out/falcon 文件夹中找到模型检查点,并使用生成脚本来与模型进行交互。
在单个 A100 GPU 上,微调模型大约需要 10 小时和 30 GB 的内存。此外,值得注意的是,适配器本身非常轻量级,只有 40MB 的大小。这与 Falcon 模型相比要小得多,后者的大小为 16GB。
使用微调模型进行推理
你可以使用微调后的 LLM 检查点来生成文本。Lit-Parrot 提供了 生成脚本。它支持 int8 和 int4 的量化,适用于内存较少的设备,你还可以更改精度并使用多个 GPU 设备:
python generate/lora.py \
--checkpoint_dir checkpoints/tiiuae/falcon-7b \
--lora_path out/falcon/lit_model_lora_finetuned.pth \
--prompt "What happened to you? Tell me" \
--max_new_tokens 300
--precision bf16-true
在我的情况下,我在 1 个 GPU 设备上运行了模型,没有进行量化,并使用了 bfloat16 精度。我还将原始的 lora 脚本 进行了修改,并将其拆分为两部分:
-
使用 streamlit 和 streamlit-chat 的 Web 界面,以更快地测试模型。你可以在 这里 找到我的版本。
-
使用 FastAPI Web 框架的 RestAPI 进行模型推理。这样可以将模型加载到内存中一次,然后再次使用它。
演示(我将文本翻译成中文以便清楚理解):
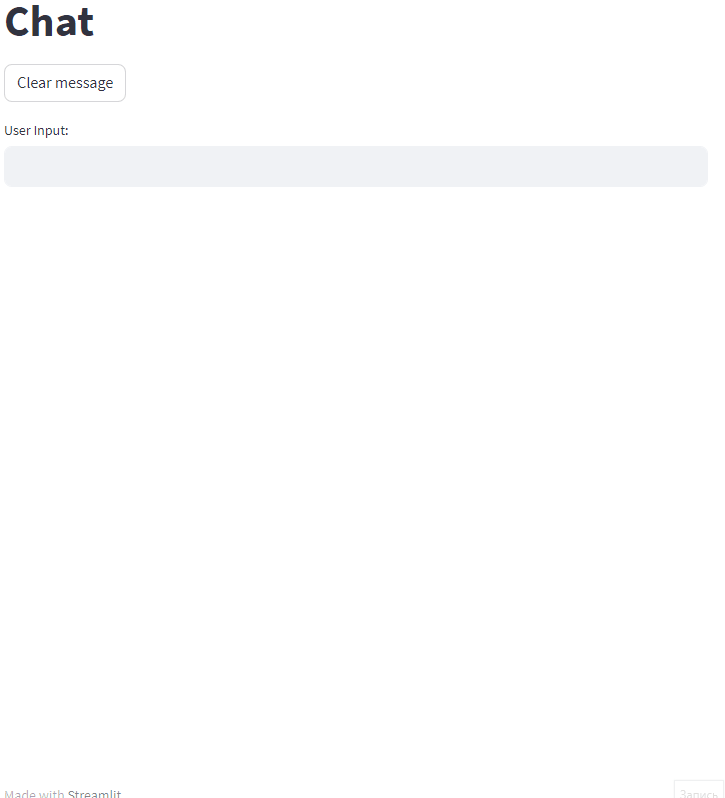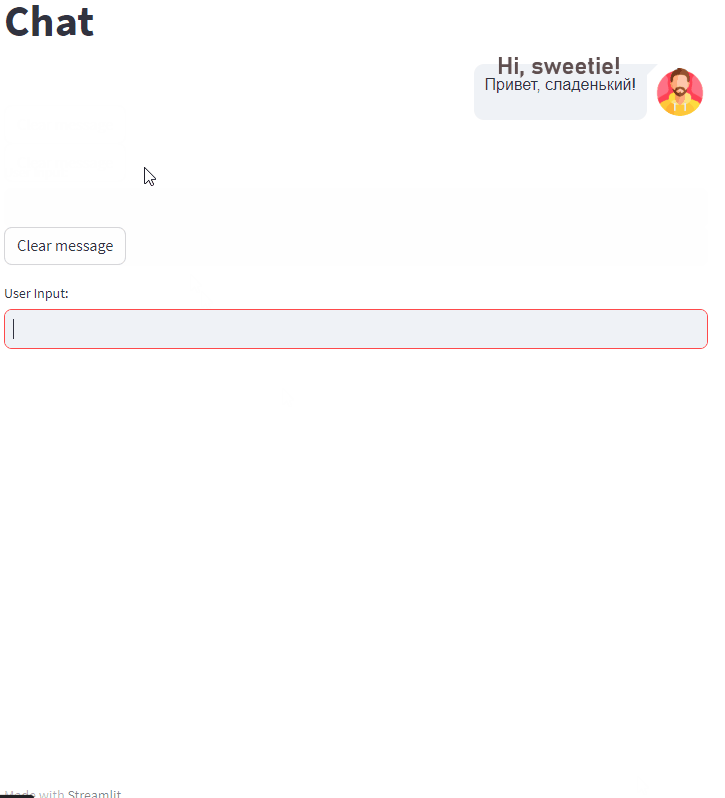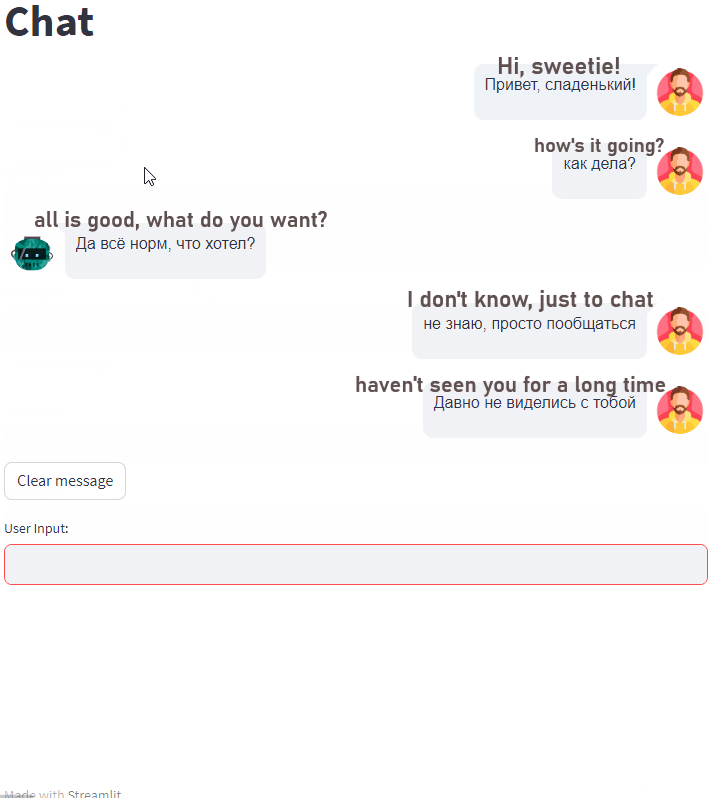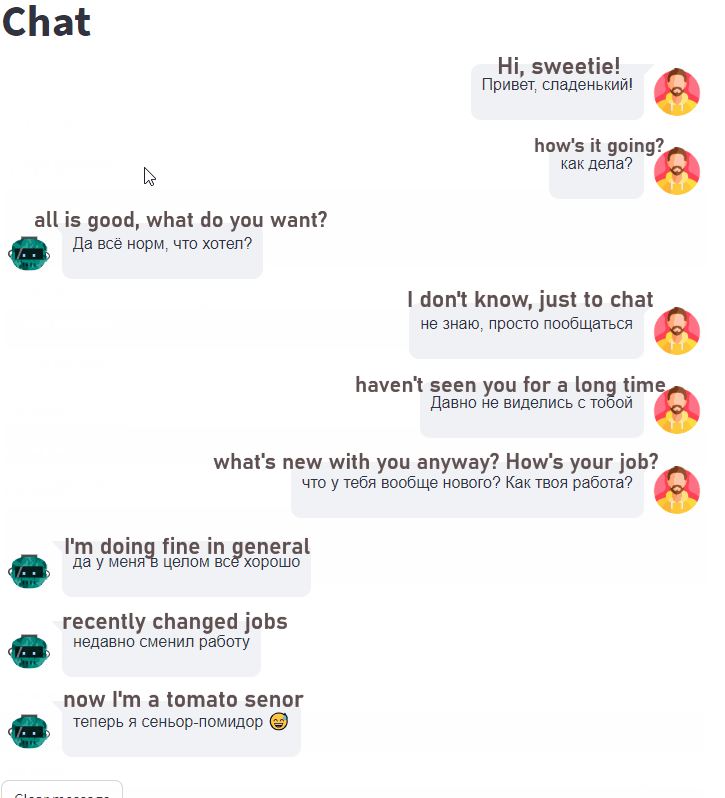
需要注意的是,这是我得到的最好的例子之一。其他的结果明显较差。
即使没有进行量化,模型的响应时间也非常快,每秒处理 45.51 个标记。如果你想加速文本生成或减少内存使用量,我建议查看我的之前的文章 7 ways to speed up inference of your hosted LLMs。
质量比较
虽然本文不涉及对真实任务的详细性能基准测试,但我可以分享一下我在使用微调模型时的个人观察。
在测试过程中,我遇到了一些奇怪的行为,比如生成无关的文本、偶尔忽略上下文以及难以保持连贯对话。
我认为可以通过以下几种方式来解决这个问题:
-
加强数据清洗过程,确保数据质量更高。
-
加入额外的带注释对话数据集。
-
将 LoRA 的秩从 16 增加到 32。
-
使用更大的模型,如 Falcon-40B。
-
减少上下文的长度或简化上下文。
-
简化提示,提供更清晰的指令。
限制
虽然 Lit-GPT 提供了广泛的功能,但我建议主要将其用于假设测试。在我看来,它还没有完全准备好用于生产。例如,在撰写本文时,Lit-GPT 缺乏内置的将模型转换回 HuggingFace 格式的实现。然而,这仍然是可能的,库的作者提出了几种解决方案:
-
对 HuggingFace 的每个类进行反向转换。
-
创建
lit_gpt.model的 HF Transformer 模型版本。
请注意,第一种方法不支持LoRA 和 Adapter 的修改。
在开发解决方案时,请记住这些限制。如果你要为生产环境微调 LLMs,我建议使用纯 PyTorch 进行微调。你可以参考亚马逊的这篇文章获取更多信息。
结论
只需要一个 GPU 和几个小时就能微调 LLMs 的能力真是令人印象深刻。你可以为不同的任务构建许多小的 LoRA 模块。当这些微调模型部署用于实时推理时,你只需要加载相同的基础模型一次。考虑到 LLM 的物理大小超过 100GB,这个优势是不可忽视的。
然而,有必要以现实的期望来对待这个过程。很可能需要尝试不同的超参数才能获得最佳结果。此外,数据集的注释和清洗是确保最佳结果的关键步骤。还要注意 LLM 的训练数据是什么,并且为类似任务的基准测试进行检查。
通过认真遵循这些步骤,我相信可以取得出色的结果!---