介绍
嘿,各位!是不是感觉你的电脑里堆满了各类 PDF、Word 文档、旧的 PowerPoint 演示文稿?有时候要找一个文件,感觉像是在大海捞针!你是不是常想,“只要我能找到 那个文件 就好了!” 🧐
如果我告诉你,其实可以让 AI 帮你找到文件并回答关于这些文件的问题呢?是的,我们要讲的就是本地文件生成式搜索引擎,通过 FAISS 和句子转换器等开源技术,为你带来智能文件管理新体验。
我构建了这个工具,让你无需记住每个文件的位置,依然能高效获取所需信息。来一起看看它是如何运作的吧!
为什么要构建这个工具? 🤔
因为我们都是书呆子啊!我们希望文件能够整理得连钢铁侠托尼·斯塔克都忍不住称赞一番!
下面是主要原因:
-
隐私优先:不希望你的重要文档飘在云端?你更需要一个本地、私密的解决方案,只有你自己能看到内容。
-
文件格式多样:PDF、DOCX、PPTX 各种格式不同,信息存储方式也不同。这款引擎能简化从多种格式提取数据的过程。
-
AI 搜索含义而非关键词:有时候你记不住具体的词,但你知道想要找的是什么。我们用 AI 来理解你的查询含义,而不仅仅匹配关键词。🧠
它是如何运作的:深入剖析 🚀
接下来,让我们一起看看核心代码。我们用了一些很酷的库,比如 FAISS 来进行索引,句子转换器模型来理解文档,以及 Ollama 的 LLM 生成回答。
1. 配置基础工具🛠️
首先,我们导入所需的库:
import os
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer
import PyPDF2
import docx
from pptx import Presentation
import streamlit as st
import ollama
- FAISS:帮助实现高效的相似性搜索。
- 句子转换器:将文本转换成向量,便于搜索。
- Streamlit:构建友好的用户界面。
- Ollama:生成 AI 回答。
2. 初始化搜索引擎🧠
我们加载预训练的 BERT 模型,将你的文档转换成向量。然后用 FAISS 来做内积搜索,找到相似文本。
model = SentenceTransformer('sentence-transformers/msmarco-bert-base-dot-v5')
dimension = 768
index = faiss.IndexFlatIP(dimension)
metadata = []
3. 读取文件内容📁
接着,我们创建函数来读取 PDF、Word、PPT 内容。
def read_pdf(file_path):
with open(file_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
return ' '.join([page.extract_text() for page in reader.pages])
def read_docx(file_path):
doc = docx.Document(file_path)
return ' '.join([para.text for para in doc.paragraphs])
def read_pptx(file_path):
prs = Presentation(file_path)
return ' '.join([shape.text for slide in prs.slides for shape in slide.shapes if hasattr(shape, 'text')])
4. 将文本分成小块✂️
为了获得更精准的结果,我们将文本分成小块:
def chunk_text(text, chunk_size=500, overlap=50):
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size - overlap):
chunks.append(' '.join(words[i:i + chunk_size]))
return chunks
5. 索引文件内容📊
将文档的文本块进行嵌入并存储在 FAISS 中,以便高效搜索。
def index_documents(directory):
global metadata
documents = []
for root, _, files in os.walk(directory):
for file in files:
content = ""
if file.endswith('.pdf'):
content = read_pdf(file_path)
elif file.endswith('.docx'):
content = read_docx(file_path)
elif file.endswith('.pptx'):
content = read_pptx(file_path)
if content:
chunks = chunk_text(content)
for i, chunk in enumerate(chunks):
documents.append(chunk)
metadata.append({"path": file_path, "chunk_id": i})
embeddings = model.encode(documents)
index.add(np.array(embeddings))
6. 进行语义搜索🔍
输入查询后,系统将其转换成向量,和文档中的内容进行匹配,找到最接近的结果。
def semantic_search(query, k=10):
query_vector = model.encode([query])[0]
distances, indices = index.search(np.array([query_vector]), k)
results = []
for idx in indices[0]:
meta = metadata[idx]
content = read_document_chunk(meta["path"], meta["chunk_id"])
results.append({"path": meta["path"], "content": content})
return results
7. 使用 AI 生成答案🤖💬
我们的 AI 伙伴 Ollama 可以生成答案,并引用相关文档内容。
def generate_answer(query, context):
prompt = f"""Answer the user's question using the documents given in the context..."""
response = ollama.generate(model='tinyllama', prompt=prompt)
return response['response']
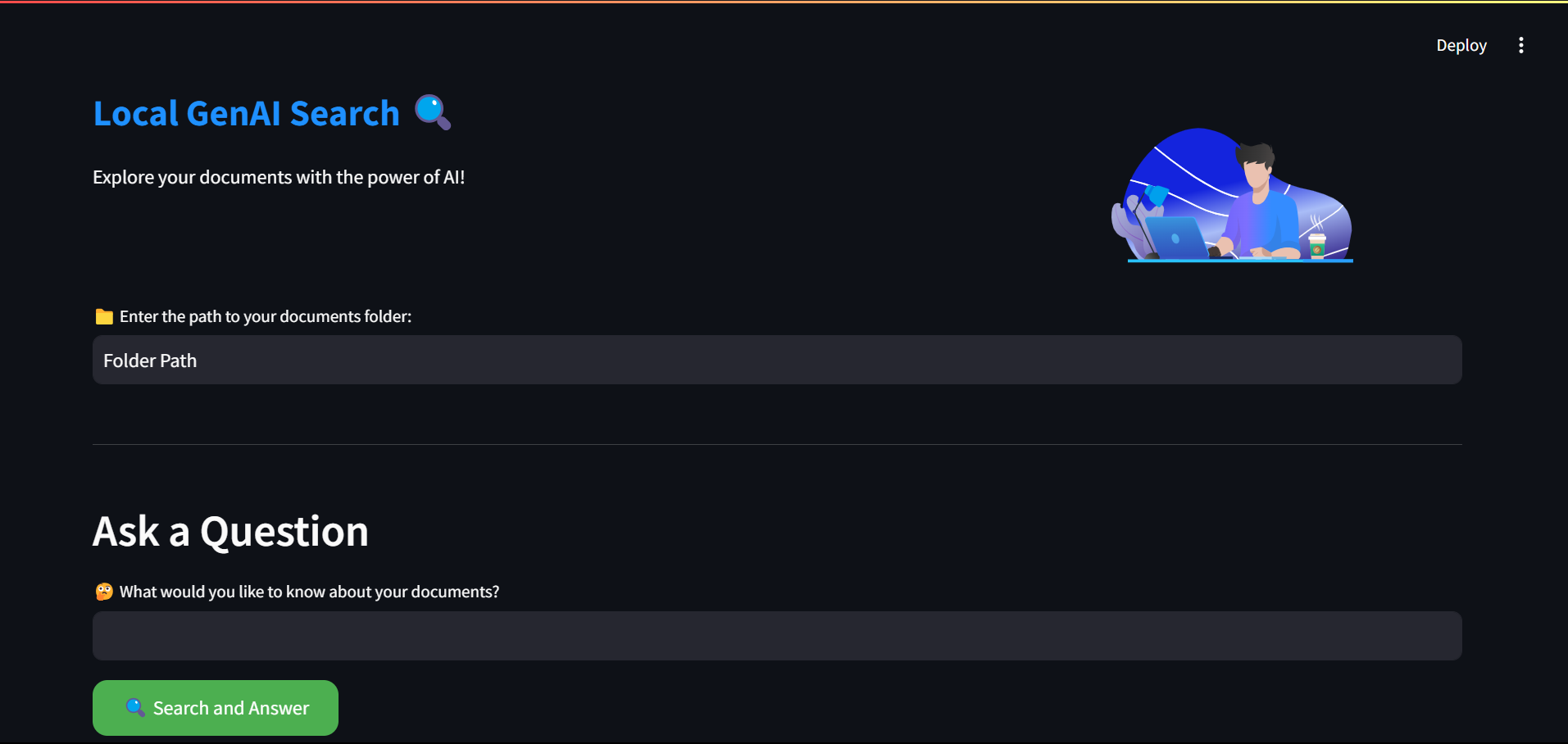
8. 构建用户界面🎨✨
使用 Streamlit 构建一个简单的界面,方便用户操作。
def main():
st.markdown('<p class="big-font">本地 GenAI 搜索 🔍 </p>')
documents_path = st.text_input("📁 输入你的文档文件夹的路径:")
if st.button("🚀 索引文档"):
index_documents(documents_path)
question = st.text_input("🤔 你想知道什么?")
if st.button("🔍 搜索并回答"):
search_results = semantic_search(question)
answer = generate_answer(question, search_results)
st.markdown(f"### 🤖 AI 答案:\n{answer}")
就这样了!🎉
通过这个教程,我们构建了一个可以在本地搜索文件并生成回答的生成式 AI 搜索引擎。🤓💡
是不是心动了?💥 整个代码已上传到我的 GitHub,可以随时下载、实验和优化。赶快成为你自己的“AI 搜索巫师”吧! 🧙♂️✨
结论
一个完全功能的本地文件生成式搜索引擎就这样搭建完成了。它在你的设备本地运行,保障隐私,还能够智能地回答你提出的各类问题。这个工具就像一个聪明的小助手,懂你所储存的一切,再也无需手动搜索文件夹。
现在,是时候让 AI 来帮助你轻松管理本地文件了!